If you consider the worst case as one core computing your longest task and the rest sitting idle, scheduling the long tasks first gives a better load balancing because with every task you assign your worst case performance decreases.
The reason that you can't always do this is that you need to have some idea of which task will take the longest. If you don't know how long the tasks will take relative to each other, you can't come up with a good ordering.
This comment was marked helpful 0 times.
kailuo
Question: In OS scheduling, the running time of processes can be predicted by looking at their past records. I wonder how workload of tasks can be predicted here?
This comment was marked helpful 0 times.
martin
Compared to the time taken in the previous slide where P1-P3 finished the work first and waited for P4 to finish the last long task, this new scheduling order helps balance the workload a lot better, as P1-P3 take more work on while P4 focuses more on the long task. However, we need some knowledge of the workload (specifically, the expected runtime of the tasks) in order to perform this scheduling optimization. Therefore, predictability in time needed to finish the task is important.
This comment was marked helpful 0 times.
ypk
Implement good schedule even we can use distributed work queue so that we can reduce overhead of redistributing work
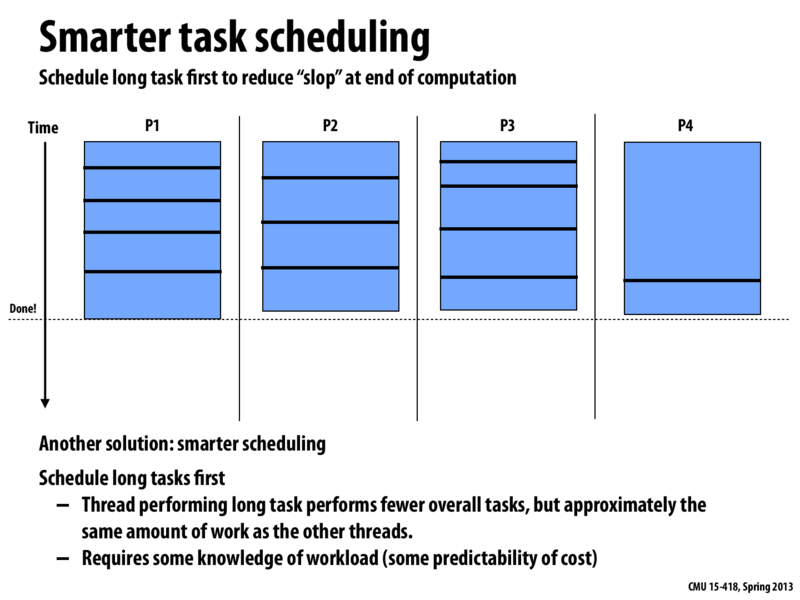
If you consider the worst case as one core computing your longest task and the rest sitting idle, scheduling the long tasks first gives a better load balancing because with every task you assign your worst case performance decreases.
The reason that you can't always do this is that you need to have some idea of which task will take the longest. If you don't know how long the tasks will take relative to each other, you can't come up with a good ordering.
This comment was marked helpful 0 times.
Question: In OS scheduling, the running time of processes can be predicted by looking at their past records. I wonder how workload of tasks can be predicted here?
This comment was marked helpful 0 times.
Compared to the time taken in the previous slide where P1-P3 finished the work first and waited for P4 to finish the last long task, this new scheduling order helps balance the workload a lot better, as P1-P3 take more work on while P4 focuses more on the long task. However, we need some knowledge of the workload (specifically, the expected runtime of the tasks) in order to perform this scheduling optimization. Therefore, predictability in time needed to finish the task is important.
This comment was marked helpful 0 times.
Implement good schedule even we can use distributed work queue so that we can reduce overhead of redistributing work
This comment was marked helpful 0 times.