Solution 3 and 4 focus on reducing the contention for access to the data structure. Solution 3 on the previous slide introduced finer granularity locks, so that there was only contention when the same element of the data structure was being written to, rather than for all writes to the data structure. Solution 4 builds upon this by creating multiples copies of the grid, dividing the points between these grids, and then computing the data structure for each one. This reduces the number of accesses to the same element since fewer points are being written to each data structure. These results can then be combined for the same final result, with less contention. There is additional work and memory, but depending on the system and the particular problem, this tradeoff for faster synchronization can be well worth it.
This comment was marked helpful 0 times.
kayvonf
An important observation is that Solution 1 duplicates computation in order to reduce synchronization. (It completely eliminates synchronization in this case). Solutions three and four trade off memory footprint (they duplicate structures) in exchange for reducing contention. A similar idea was used to reduce synchronization in Lecture 4, when we reduced three barriers to one in the solver example.
Question: When might it be a bad idea to trade off memory footprint for synchronization/contention?
This comment was marked helpful 0 times.
Mayank
If we have limited memory, then increasing memory footprint can result in reduction of parallelism. For example, when we were implementing our solution for assignment 2, initially we had allocated a bunch shared memory arrays for position, color, radius. The size of each shared memory array was proportional to the number of threads in the block. Since, we were allocating so much shared memory, we were not able to increase the number of threads per block beyond a certain point. Hence, even though we had more sub-problems and compute units available, the amount of parallelism was being limited by shared memory.
This comment was marked helpful 1 times.
kfc9001
@kayvonf Increasing memory requirements might be a idea on a shared memory system that potentially has a shared cache across processors (i.e. an i7). If the space requirements are much greater than in the serial implementation, there may be a lot of conflict misses in a cache that may potentially outweigh the benefits of processing in parallel.
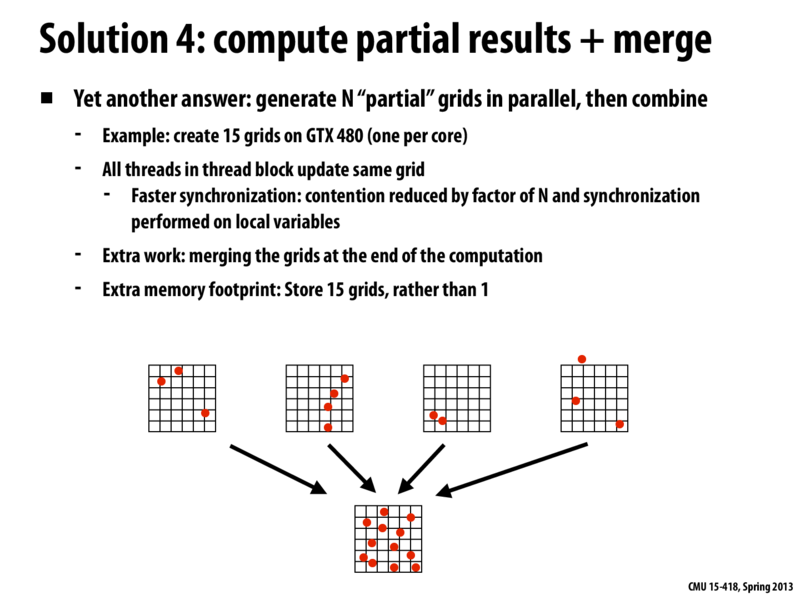
Solution 3 and 4 focus on reducing the contention for access to the data structure. Solution 3 on the previous slide introduced finer granularity locks, so that there was only contention when the same element of the data structure was being written to, rather than for all writes to the data structure. Solution 4 builds upon this by creating multiples copies of the grid, dividing the points between these grids, and then computing the data structure for each one. This reduces the number of accesses to the same element since fewer points are being written to each data structure. These results can then be combined for the same final result, with less contention. There is additional work and memory, but depending on the system and the particular problem, this tradeoff for faster synchronization can be well worth it.
This comment was marked helpful 0 times.
An important observation is that Solution 1 duplicates computation in order to reduce synchronization. (It completely eliminates synchronization in this case). Solutions three and four trade off memory footprint (they duplicate structures) in exchange for reducing contention. A similar idea was used to reduce synchronization in Lecture 4, when we reduced three barriers to one in the solver example.
Question: When might it be a bad idea to trade off memory footprint for synchronization/contention?
This comment was marked helpful 0 times.
If we have limited memory, then increasing memory footprint can result in reduction of parallelism. For example, when we were implementing our solution for assignment 2, initially we had allocated a bunch shared memory arrays for position, color, radius. The size of each shared memory array was proportional to the number of threads in the block. Since, we were allocating so much shared memory, we were not able to increase the number of threads per block beyond a certain point. Hence, even though we had more sub-problems and compute units available, the amount of parallelism was being limited by shared memory.
This comment was marked helpful 1 times.
@kayvonf Increasing memory requirements might be a idea on a shared memory system that potentially has a shared cache across processors (i.e. an i7). If the space requirements are much greater than in the serial implementation, there may be a lot of conflict misses in a cache that may potentially outweigh the benefits of processing in parallel.
This comment was marked helpful 1 times.