The rows in gray represent that data that P2 will need to compute values in the next iteration. In the blocked assignment, there are only two rows on the border of the data that P2 is responsible for, so P2 will only need to receive this much data from P1 and P3. Most of the data that P2 needs to compute its next iteration is data that P2 already has.
If there were more (n) rows in the matrix, there would still only be 2 rows highlighted on the left hand side and there would be n/2 highlighted on the right hand side.
Because of the cost of communication between processors, we would choose the blocked assignment for this problem.
(Note that in the sin example from last lecture, we preferred an interleaved assignment because of memory locality, an entirely different reason)
This comment was marked helpful 1 times.
kayvonf
Nice comment @mschervi. However, I want to point out that memory locality is actually the reason both for choosing the blocked assignment here (where we assumed our machine was a collection computers, such as in a cluster setting) and also for choosing an interleaved assignment of loop iterations to program instances in the sinx example (programming models lecture, slides 007 and 008).
Here, the locality we want to take advantage of is that a processor already has data it needs in local memories, and thus data transfers need not occur.
In the ISPC example, the locality is spatial locality: we wanted all instances to request adjacent data elements at the same time (to allow implementation as an efficient block load, and avoid the need for a more costly gather operation)
This comment was marked helpful 1 times.
martin
ISPC utilizes one core, so in the sinx example interleaved loop iteration improves locality. On the other hand, each block is computed with one core (good locality already under the cluster setting assumption), and thus no need for data transfer.
This comment was marked helpful 0 times.
briandecost
@kayvonf -- Isn't memory locality just another way of thinking about minimizing communication?
With the blocked assignment, P2 needs its own local data, plus half a row each from P1 and P3 for every iteration. Additionally, two rows of P2's assigned data get updated by P1 and P3.
With the interleaved assignment, P2 needs to load pretty much every data element from nonlocal.
The way it's drawn, I think P2 needs 4 non-local pieces of data for every local piece of data! (Of course in a real example it's only a tiny (but nonzero) fraction of nonlocal data, giving the significant memory locality advantage you mentioned compared to this interleaved assignment).
"Maximizing memory locality" doesn't seem all that distinct to me from "minimize data communication" -- is that an astute observation or a flaw in the way I'm thinking about this?
This comment was marked helpful 0 times.
kayvonf
@briandecost: Yes! The presence of locality is an opportunity for sharing, and thus an opportunity for program optimization.
Temporal locality exists when a piece of data is used by a processor multiple times. If the value is cached between the uses, memory-to-processor communication is avoided for all but the first use. The cost of the load from memory is amortized over (a.k.a. shared by) all computations that use the value.
Spatial locality exists when a process accesses a piece of data and then subsequently accesses nearby data. In the example above, data generated in iteration i is used to compute nearby elements in iteration i+1. Thus, if the computation of elements nearby in space is performed on the same processor, communication need not occur.
Another example of spatial locality comes up in the discussion of caches. A load of any one piece of data brings in an entire cache line of data. If the program exhibits high spatial locality in its data accesses, the rest of that line will be used by subsequent loads. Thus, the latency of future loads is small (the data is in cache before the load occurs) and also the entire line is loaded into cache at once using a single batch load operation (rather than individually reading each value from memory).
This comment was marked helpful 0 times.
markwongsk
At first I didn't understand how interleaving improved spatial locality. My misconception was that I only considered that the programCount * iteration + programIndex will be executed serially and was confused how this would improve spatial locality. What I forgot was that since the code is executed in gangs, the spatial locality that is being referred to is the fact that all gang members are requesting data closely to each other, thus improving spatial locality.
This comment was marked helpful 1 times.
kayvonf
To clarify, @markwongsk is referring to the interleaved assignment of data elements to ISPC program instances in the sinx example in Lecture 3, slides 8 and 9.
Prior to this course you probably only considered intra-thread locality. That is, spatial or temporal locality in the operations performed by a single thread of control. Here, this is a case of inter-thread locality (specifically, inter-ISPC-program instance). By inter-thread, I'm referring to locality in data access across concurrently running threads of control. In the interleaves sinx ISPC program example, assignment of work to instances is set up such that different instances access adjacent data elements at the same time. As you can imagine, the hardware can typically handle this situation more efficiently than if the data accessed by each program instance was widely spaced in memory.
In the implementation of sinx, each of the eight program instances simultaneously accesses consecutive elements of the input array: 8 x 4 bytes = 32 total consecutive bytes read.
This comment was marked helpful 0 times.
kuity
A brief summary from what @kayvonf said about locality in this example:
We can take advantage of memory locality with blocked assignment as each processor has its block elements stored in local memory, minimizing the time cost of data transfer.
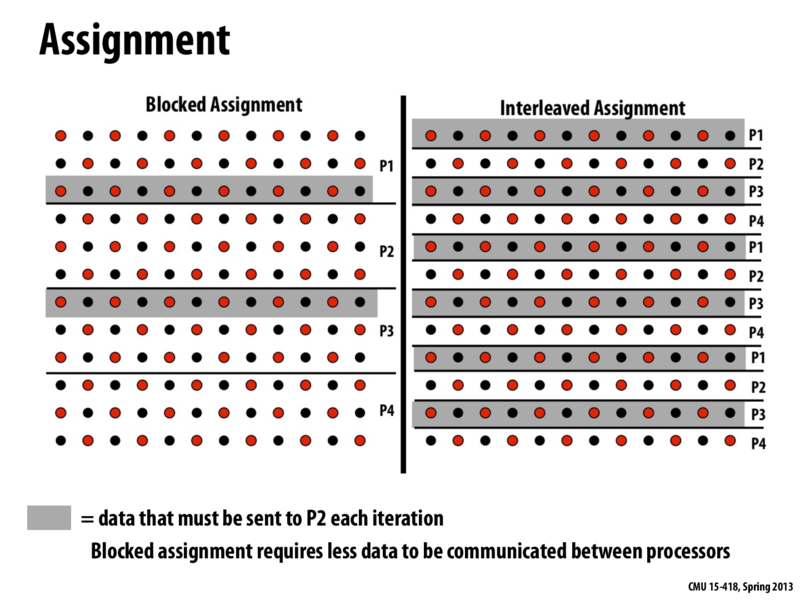
The rows in gray represent that data that P2 will need to compute values in the next iteration. In the blocked assignment, there are only two rows on the border of the data that P2 is responsible for, so P2 will only need to receive this much data from P1 and P3. Most of the data that P2 needs to compute its next iteration is data that P2 already has. If there were more (n) rows in the matrix, there would still only be 2 rows highlighted on the left hand side and there would be n/2 highlighted on the right hand side.
Because of the cost of communication between processors, we would choose the blocked assignment for this problem.
(Note that in the sin example from last lecture, we preferred an interleaved assignment because of memory locality, an entirely different reason)
This comment was marked helpful 1 times.
Nice comment @mschervi. However, I want to point out that memory locality is actually the reason both for choosing the blocked assignment here (where we assumed our machine was a collection computers, such as in a cluster setting) and also for choosing an interleaved assignment of loop iterations to program instances in the
sinxexample (programming models lecture, slides 007 and 008).Here, the locality we want to take advantage of is that a processor already has data it needs in local memories, and thus data transfers need not occur.
In the ISPC example, the locality is spatial locality: we wanted all instances to request adjacent data elements at the same time (to allow implementation as an efficient block load, and avoid the need for a more costly gather operation)
This comment was marked helpful 1 times.
ISPC utilizes one core, so in the sinx example interleaved loop iteration improves locality. On the other hand, each block is computed with one core (good locality already under the cluster setting assumption), and thus no need for data transfer.
This comment was marked helpful 0 times.
@kayvonf -- Isn't memory locality just another way of thinking about minimizing communication?
The way it's drawn, I think P2 needs 4 non-local pieces of data for every local piece of data! (Of course in a real example it's only a tiny (but nonzero) fraction of nonlocal data, giving the significant memory locality advantage you mentioned compared to this interleaved assignment).
"Maximizing memory locality" doesn't seem all that distinct to me from "minimize data communication" -- is that an astute observation or a flaw in the way I'm thinking about this?
This comment was marked helpful 0 times.
@briandecost: Yes! The presence of locality is an opportunity for sharing, and thus an opportunity for program optimization.
Temporal locality exists when a piece of data is used by a processor multiple times. If the value is cached between the uses, memory-to-processor communication is avoided for all but the first use. The cost of the load from memory is amortized over (a.k.a. shared by) all computations that use the value.
Spatial locality exists when a process accesses a piece of data and then subsequently accesses nearby data. In the example above, data generated in iteration
iis used to compute nearby elements in iterationi+1. Thus, if the computation of elements nearby in space is performed on the same processor, communication need not occur.Another example of spatial locality comes up in the discussion of caches. A load of any one piece of data brings in an entire cache line of data. If the program exhibits high spatial locality in its data accesses, the rest of that line will be used by subsequent loads. Thus, the latency of future loads is small (the data is in cache before the load occurs) and also the entire line is loaded into cache at once using a single batch load operation (rather than individually reading each value from memory).
This comment was marked helpful 0 times.
At first I didn't understand how interleaving improved spatial locality. My misconception was that I only considered that the
programCount * iteration + programIndexwill be executed serially and was confused how this would improve spatial locality. What I forgot was that since the code is executed in gangs, the spatial locality that is being referred to is the fact that all gang members are requesting data closely to each other, thus improving spatial locality.This comment was marked helpful 1 times.
To clarify, @markwongsk is referring to the interleaved assignment of data elements to ISPC program instances in the
sinxexample in Lecture 3, slides 8 and 9.Prior to this course you probably only considered intra-thread locality. That is, spatial or temporal locality in the operations performed by a single thread of control. Here, this is a case of inter-thread locality (specifically, inter-ISPC-program instance). By inter-thread, I'm referring to locality in data access across concurrently running threads of control. In the interleaves
sinxISPC program example, assignment of work to instances is set up such that different instances access adjacent data elements at the same time. As you can imagine, the hardware can typically handle this situation more efficiently than if the data accessed by each program instance was widely spaced in memory.In the implementation of
sinx, each of the eight program instances simultaneously accesses consecutive elements of the input array: 8 x 4 bytes = 32 total consecutive bytes read.This comment was marked helpful 0 times.
A brief summary from what @kayvonf said about locality in this example:
We can take advantage of memory locality with blocked assignment as each processor has its block elements stored in local memory, minimizing the time cost of data transfer.
This comment was marked helpful 0 times.