



Answer: The foreach loop is parallelized by ISPC because it is a construct that a programmer can use to indicate to ISPC that each iteration of the foreach loop is independent and can be executed in parallel. Thus, ISPC takes advantage of this and parallelizes it accordingly. The inner for loop, however, is not parallelized since ISPC always treats regular for loops as sequential constructs.
This comment was marked helpful 0 times.

I don't think that description is completely accurate.
As Kayvon put it in lecture, there is no parallelism expressed in the code in this or the previous slide. ISPC does not parallelize loops. It creates program instances, each of which run sinx. So what you actually have is multiple instances of the function being run in parallel. The ISPC compiler assigns iterations of the foreach loop to different program instances, but the loop itself is not parallel. foreach is really no different than making the assignment yourself like in the previous slide, only you're letting the compiler make that assignment instead. The manual assignment in the previous slide is one example assignment ISPC could make for the foreach loop here.
This comment was marked helpful 1 times.

An easier way to think of this is: Once a call to ISPC function is made, a gang of program instances would start to run the ISPC function in parallel, and return the control back to the caller when all the instances are finished. It doesn't matter whether we use foreach or program counter/ program index. Those are basically syntax for ISPC, which give programmers flexibility to assign the work manually or let the compiler to do the job.
This comment was marked helpful 1 times.

I am failing to grok the semantics of "parallelize" and what is meant by the presence or absence of parallelism in the code here, I think. I understand what the SIMD instructions that the compiler generates will do and how the compiler will get there, but how exactly are we defining "parallelize" for the purpose of this discussion?
This comment was marked helpful 0 times.
By parallelize, we mean introduce parallelism (i.e. create instances/threads/tasks/etc). The foreach loop doesn't mean 'do this in parallel'. It simply means at compile time divide up this work for program instances that will be executing this function. The spawning of the program instances is where parallelization happens since that's where things are spawned that run in parallel. That occurs outside of the function. When each spawned instance of sinx executes the function body, it will know what indices in the range 0..N it should work on based on the division the compiler did (think of it as creating a for loop with programCount/programIndex like in the previous slide), and each instance will execute the code inside the function completely sequentially.
I think it's important to keep in mind we are working on a SPMD abstraction level here. The abstraction doesn't say how those instances of sinx should be run in parallel, just that there will be instances of it running in parallel. SIMD instructions are one possible way to implement the running of the instances in parallel.
This comment was marked helpful 3 times.

The foreach loop says "these loop iterations are independent work". ISPC uses that information to decide on a good way to parallelize the loop.
The actual code is being executed "in parallel", in the sense that 8 iterations are being done (by 8 different ALUs) at the same time.
This comment was marked helpful 0 times.

This is a little late, but I am feeling slightly confused by this discussion.
Isn't dividing up the work among the "gang of program instances" something like creating threads to run the function in parallel? So why is it there is no parallelism expressed in this code?
This comment was marked helpful 0 times.

@kuity You're right, the program instances of the gang are each running the function in parallel, much like multiple forked threads running it in parallel. Kayvon says there is no parallelism expressed in this code, because there is nothing explicitly parallel about it. Taken in a non-SIMD environment, this is a purely sequential program, iterating from 1.. N. It's all up to the ISPC compiler to give meaning to "program count" and utilize the parallel SIMD lanes, whereas pthreads code would be explicitly parallel- you, the programmer would be instructing which threads to run which functions.
This comment was marked helpful 1 times.

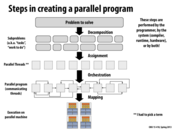

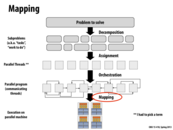
Each of these steps to creating a parallel program can be performed by either the user or the system. For instance, the assignment of the subproblems after they are decomposed is user-specified, the orchestration of the threads is handled by the system.
This comment was marked helpful 0 times.
It's interesting to note that the line between what is user controlled and system controlled can vary. The system is capable of handling decomposition, for example, when it comes to instruction level parallelism.
This comment was marked helpful 1 times.

This is how I interpret these steps: You are the project leader of a group and you need to write a report. - Decomposition: Figuring out the possible ways to split up the report. For example, splitting by section or by role (outline writer, writer, editor), etc. - Assignment: Assigning a portion to each group member. This can be done statically (person A takes sections 1 and 2, person B takes section 3,etc.) or dynamically (everyone calls dibs on a section and helps other people out if they finished early) or maybe a combo. - Orchestration: Finding dependencies and communication between team members. If person A hasn't written the results, person B who has Discussion is going to run into issues. Also someone will probably have to compile everyone's sections together and format them in the end. - Mapping: Actually giving instructions to your group and having them work.
This comment was marked helpful 0 times.


Put another way, depth (from 15-150 and 15-210) is a lower bound on the execution time, just as work is an upper bound.
This comment was marked helpful 0 times.

Can you explain depth for those of us that didn't take 15-150 or 15-210?
This comment was marked helpful 0 times.
Consider summing 8 numbers using a tree. The depth would be 3 and the work would be 7.
This comment was marked helpful 0 times.

15-150 defines span/depth as: An upper bound on the longest sequential part of the program, which gives us a lower bound on the overall running time assuming an unlimited supply of processors is available and we partition the work among as many processors as we need.
This is easiest to think about when looking at a particular computation as a tree. So, the example given above is a very specific example of this. Although each computation within any given row of a tree can be done independently (in parallel), computation between rows is sequential and thus a lower bound on runtime.
This comment was marked helpful 1 times.
Break your computation down into a series of steps (as fine-grained as you want). Draw an edge from step A to step B if B depends on A. Then depth is the length of the longest path in this graph (where we pay to go through vertices, and the cost of a vertex is the amount of work there).
Note that this graph is a DAG (what would a cycle mean?), and any valid topological sort is an order a sequential processor could do the work. You can maximize parallelism by always working on every vertex of in-degree 0 (imagine that when you finish the work at a vertex, it and its outgoing edges disappear).
This comment was marked helpful 2 times.
@acappiello: I believe you mean lower bound on runtime ;) Here's an example computation tree, for the visually inclined:
*
/ \
+ -
/ \ / \
2 2 3 1
The work of computing the ((2+2)*(3-1)) is given by the number of nodes in the tree (3.. or 7 if you like to include the integer loads) while the span is given by the longest path from root to leaf (2 or 3 based on the same condition).
This comment was marked helpful 0 times.
@pebbled Oops. Yeah, I made a mistake there. I meant to say that it's an upper bound on the longest sequential part of the code, which is effectively a lower bound on overall runtime. I'll edit that post.
This comment was marked helpful 0 times.

@acappiello: One further clarification: I wouldn't say span is a bound on the "longest sequential part of the program" since that definition makes it sound like a program with multiple sequential parts is only bounded by the longest of those parts. A better way to think about a program's span (a.k.a. its "depth"), is to consider the longest sequence of dependent operations in a program. As @pebbled says when referring to the example of an expression tree, the span is the longest path from the root of the expression tree to a leaf. Since none of these dependent operations can be carried out in parallel, no parallel program can finish faster than the time it takes to execute this sequence.
Clarification: I also what to point out that in this class theory and practice don't always meet up because theory does not model all the factors that contribute to performance in a real system. We've also learned about how caching effects in this class that might cause a parallel program to run with superlinear performance and thus seemingly outperform the bound set by span if wall clock time was measured. This doesn't violate the notion of span. It just means that the dependent sequence of instructions was somehow carried out faster in the parallel configuration than in the serial one, not because of parallelization of this sequence (which is impossible due to the dependencies), but because of some other system-level effect.
This comment was marked helpful 0 times.

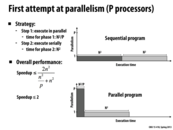

Kayvon mentioned that although we parallelized step 1, we will be running step 2 serially. As a result, the maximum speedup that can be achieved using p processors will be significantly affected and is in fact slightly less than 2. Amdahl's law describes the impact of serial portions of code on speedup.
This comment was marked helpful 0 times.


Question: To combine the partial sums, we add them one by one to get O(P) running time. Is it possible to add them as a binary tree, using O(log(P)) time? What is about the implementation of reduceAdd function?
This comment was marked helpful 0 times.

@unihorn Although it may be possible to split some of the addition across multiple processors, we probably wouldn't see any real speedup. In most cases P will not be that large and the communication across processors may even make it take longer than just doing it serially. Also, ${N^2 \over P} $ will most likely dominate the O(P) time.
This comment was marked helpful 1 times.

The parts of the program that are inherently sequential (for this case, it would be the step wherein we combine partial sums) usually are the major factors that limit its speedup. The graph on the next slide (slide 10) is good to look at to observe the effect of an increase in processors on maximum speedup, given a set fraction of the program that is inherently sequential.
This comment was marked helpful 0 times.

Looking just at the partial sums, would it be possible to perform each level of the binary tree in parallel on one processor using SIMD with a noticeable speedup (no tasks)?
This comment was marked helpful 0 times.
@bourne The sums across one level of the tree are independent, so there's no reason you couldn't process as many in parallel as you have SIMD lanes on your processor. It could be some tricky code, however, to keep each program instance fed with input, when the input to each level is the output from the previous level.
This comment was marked helpful 0 times.

Getting the 100x speedup from S=0.01 is hard; even with 1000 processors the speedup is only ~90x
This comment was marked helpful 0 times.
There are some interesting implications made apparent by this graph.
As we discussed at the very beginning of the course, parallelism was born out of our inability to continue to push the clock speed of processors any higher due to issues with heat (lecture 1, slide 27). However, this demonstrates that there is an upper limit to parallelism, as programs are not 100% parallel. So, while more processors continues to increase the amount of parallelism possible on a system, it becomes harder to exploit it.
This comment was marked helpful 0 times.

Here is a nice demonstration of Amdahls Law.
This comment was marked helpful 1 times.

Later in the course, we learn that it is important to take into account the capability of each core, and in heterogenous systems, the type of each core.
This comment was marked helpful 0 times.

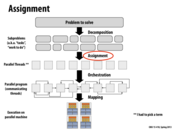


On the left hand side, the programmer assigned the work to different threads (or workers). On the right hand side, the compiler takes care of workload assignment. (likely to have the same workload distribution in this case)
This comment was marked helpful 0 times.
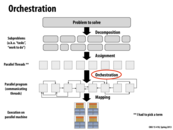

Correctness is also a big problem in orchestration! (e.g. race conditions). Bugs here are typically challenging to track down because they depend on non-deterministic thread scheduling.
This comment was marked helpful 0 times.


One example of putting unrelated threads of work on the same processor would be if one of your threads was handling I/O. Since this thread would have to wait for disk reads (and would be inactive a lot of the time) putting another thread on the processor that had to do a lot of computations would keep the processor in use more of the time.
This comment was marked helpful 0 times.

Question -- it's usually the job of the OS to map threads to processors -- how does that play into / affect these mapping decisions? Is it even possible/tractable for the programmer to explicitly schedule threads, or to specify that a group of threads should be mapped together?
This comment was marked helpful 0 times.
Yes, most systems do provide the programmer mechanisms to set the affinity of a thread. A thread's affinity specifies (or strongly hints at) what physical resource it should be mapped to. For example, if you are interested in mapping a pthread to a particular processor you may be interested in the pthread library function pthread_getaffinity_np().
You can also set the affinity of a process using sched_setaffinity().
This comment was marked helpful 0 times.

You can also reconfigure the scheduler using sched_setscheduler. The SCHED_FIFO scheduler is (roughly) a cooperative scheduler, where your thread will run until you block on IO or call sched_yield (or a higher priority process becomes runnable).
This comment was marked helpful 0 times.


Question What's an example of a problem where the mapping between work and data isn't very clear? Just wanted to hear about some cool examples.
This comment was marked helpful 0 times.
How about a chess bot? I think it's basically just computation (the only data that might be involved will be an endgame tablebase, an opening book and a repetition table I guess...)
This comment was marked helpful 0 times.
Perhaps another example would be client code for loading a website with many elements (media elements that requests json objects from other websites, forms awaiting user input, dynamic placement of divs etc.)? In this case it is not at all clear how to partition data so it would be preferable to single out the costly computations and try to partition them.
This comment was marked helpful 0 times.



One of the real world application with such set up is particle simulation systems, where the forces of neighboring particles are applied the the central particle to compute the acceleration and speed, so the position of each particle can be updated.
This comment was marked helpful 0 times.

As the inner loop iterate the points from left to right, right side element depends on the result of its left side neighbor. Similarly, elements also depends on the result of its neighbor above it.
This comment was marked helpful 0 times.

Question: Doesn't line 20 and 21 show that A[i, j] is dependent on the elements to its left, above, right, and below? Why does it only depend on the elements to its left and above?
This comment was marked helpful 0 times.
@xs33 They only depend on the elements to the left and above because of lines 17 and 18 which define the order in which cells are computed. Those two cells are computed before the current cell, which is the dependency. The cells to the right and below still have the values from the previous iteration.
This comment was marked helpful 0 times.



Since computing the new value of an element at (i,j) requires you to first do the calculation for (i-1,j) and (i,j-1) each element on each round has a dependency on the elements that are above it and/or the left of it. However, this means that all elements on a given diagonal (the blue lines) are independent of each other and can be done in parallel. This gives some parallelization, but overall is not the most effective technique, because you still have to do each diagonal in order, which is still a lot of sequential code.
This comment was marked helpful 0 times.

An interesting note about this algorithm is that the amount of parallelism changes as the computation progresses. Initially, there is very little parallelism, which then increases until we reach halfway through the grid, at which point it once again begins to decrease. As mentioned above, this means that it is not the most effective technique, since we are not always fully taking advantage of all the possible parallelization.
This comment was marked helpful 0 times.
Note that you can run many iterations at once, as long as they are separated by at least one diagonal. So in fact the parallelization you can get here is very good (basically as good as the red-black coloring suggested a few slides later; you can do work on about half the elements at a time).
To elaborate: the last diagonal can compute iteration 1 at the same time the third-to-last diagonal computes iteration 2 at the same time the fifth-to-last diagonal computes iteration 3...
This comment was marked helpful 0 times.
@jpaulson -- that's actually a really cool idea, to set your program up to run iterations in waves, but it's probably not the best design choice for this geometry. It's certainly takes advantage of more parallelism, but it doesn't really address the drawbacks of the diagonal method -- nontrivial to code, not much parallelism early on (and at the end) for two reasons now, and you still have lots of synchronization.
This comment was marked helpful 0 times.
@briandecost If you had a small difference required to stop (difference between one iteration and the next) you could probably just stop in the middle of several iterations- leaving each diagonal on a different iteration. While this would not be the same as the sequential if the error is small enough running the end iterations to completion would result in only a negligible change.
This comment was marked helpful 0 times.
Note that this algorithm runs in O($n$) time and the previous algorithm runs in O($n^2$) time. That means that if both algorithms were optimized, as $n$ increases, the running time for the first algorithm increases exponentially.
This comment was marked helpful 0 times.
@kuity: Huh? Are you assuming you actually have $n$ cores to run on?
This comment was marked helpful 0 times.
@jpaulson Oh yeah, I was indeed assuming that. I was more thinking about it in terms of the span of the algorithm rather than the actual specs of the machine, though (so assuming no hardware limitations).
This comment was marked helpful 0 times.

Wouldn't jpaulson's method of parallelism across iterations theoretically be one of the best ways to parallelize this algorithm? It allows there to be n processors doing useful work at all times. The only drawback I see is the need for synchronization after every calculation, every iteration needs to move to the next calculation at the same time.
This comment was marked helpful 0 times.

If you make each iteration depend on the previous iteration instead of partial results of the current iteration, you get the Jacobi method instead of Gauss-Seidel method. Jacobi probably converges about as well and is super-parallel, but uses twice as much memory.
This comment was marked helpful 0 times.

Question: I don't know if this is an overly general question, but it was mentioned in class that during the final project, we might need to change algorithms. Is there a way to know when we would need to change algorithms or are we just be expected to reason through it? For example, how would we make the jump from parallelizing along the diagonals to the red-black coloring? Or when would we switch from improving parallelization to reducing dependencies?
This comment was marked helpful 0 times.
In response to @hh: I think it depends on the problem you're working on. For example, in this case, it would depend on a couple of things. Do we NEED to use the Gauss-Siedel method for our application to work correctly? If so, the best we can get is the diagonal lines. But let's say we're using the Gauss-Siedel method, just to "blur" the field to some threshold (I'm not sure exactly what this does but Kayvon mentioned it in lecture). If we don't care about the exact method that this "blurring" happens as long as the general effect is similar, or if we care about speed a lot more, then it would make sense to switch to the red-black coloring.
And then I'm sure a lot of other factors come into account, too. For example, what kind of system am I running on. If I only have two cores, is it worth completely switching algorithms (or debugging what may be a tougher algorithm) to get what may end up being a very slight speed boost. I think this is as much a software-engineering decision as a computer science one (distinguish those terms however you see fit).
This comment was marked helpful 0 times.
@Incanam -- to try to clarify what Kayvon meant by "blurring the field", this method is a typical example of a numerical solution of a differential equation. You have some boundary conditions (in his example it's the topmost and leftmost rows) and you want to know what the solution looks like -- it's sort of like the iterative sqrt program from HW, but all the data elements depend on each other, so the effects of the boundary conditions propagate (blur) through the system until all the values stop changing (convergence).
Any algorithm that converges to the solution is fine -- we accept the approximate nature of the solution because we can't get an analytical solution anyways
This comment was marked helpful 0 times.
@Incanam Thanks for the help/clarification! I guess an addition to your answer is that you should measure/analyze to figure out what factors do come into account (lecture 6, slide 20). An example was brought up in that lecture on this slide: lecture 6, slide 28 (you don't want to change algorithms when the costs are small).
This comment was marked helpful 0 times.

When redesigning algorithms, keep in mind that it can be ok to increase overall work if this also allows you to increase the amount of parallelism.
This comment was marked helpful 0 times.

Can someone explain how the one comment made during class about doing parallel iterations to tackle this problem? Would it be doing every single node all the time and effectively each diagonal would be on its own iteration(because it is using old values of the top and left nodes), meaning that the whole problem would take ~2x as many iterations but every node could be done in parallel?
This comment was marked helpful 0 times.

Question: I don't get how the parallelization returns the same result as the serial one. When computing a red cell with the neighboring black cells, shouldn't the black cells (above and left) be updated beforehand? As identified in slide 23, because the dependency starts from the very left top cell of the gird, although we can update the red cells independently, it looks like the dependency still remains between the black cells and the red cells. Can someone help me out?
This comment was marked helpful 0 times.
@danielk2 -- The dependency isn't just the top left cell, but the top and left edges of the grid (boundary conditions). The method from slide 22 computes each node "in order", so for one or two iterations you get a different result from what you get with this "out of order" alternating-checkerboard scheme. But if you think about many iterations, the end result is the same: both algorithms converge to approximately the same solution for a given set of boundary conditions.
The difference is they don't necessarily take the same path to convergence, nor the same amount of computation. It doesn't matter that they're not exactly the same, because the discretization onto the grid was already an approximation.
This comment was marked helpful 1 times.
@abunch: You may be referring to the first comment made on slide 24 describing doing multiple iterations on the same time, which has a good explanation. Every diagonal could be calculating a different iteration in parallel, except for the beginning and ending, which would still be sequential. I don't think this should affect how many iterations it does total, it should still calculate the same amount of work as the sequential version, just faster.
This comment was marked helpful 0 times.
@bourne I think @abunch was referring to calculating every single node in parallel in one iteration, not just the nodes on each diagonal. If that's the case, I think that it would be a different algorithm altogether and I'm not sure if you can safely say that there will be 2x the number of iterations.
This comment was marked helpful 0 times.
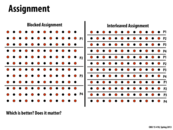
We should keep the context of this question in mind when answering. If P1, P2, P3 and P4 represented different machines, 'Blocked Assignment' would do significantly better than 'Interleaved Assignment' since the 'Interleaved Assignment' would require a lot of communication between these machines (which would be expensive). On the other hand, if P1, P2, P3 and P4 represented different threads on a single machine, the interleaved assignment would probably do better (not a 100 % sure about this) due to shared data.
This comment was marked helpful 0 times.



The rows in gray represent that data that P2 will need to compute values in the next iteration. In the blocked assignment, there are only two rows on the border of the data that P2 is responsible for, so P2 will only need to receive this much data from P1 and P3. Most of the data that P2 needs to compute its next iteration is data that P2 already has. If there were more (n) rows in the matrix, there would still only be 2 rows highlighted on the left hand side and there would be n/2 highlighted on the right hand side.
Because of the cost of communication between processors, we would choose the blocked assignment for this problem.
(Note that in the sin example from last lecture, we preferred an interleaved assignment because of memory locality, an entirely different reason)
This comment was marked helpful 1 times.
Nice comment @mschervi. However, I want to point out that memory locality is actually the reason both for choosing the blocked assignment here (where we assumed our machine was a collection computers, such as in a cluster setting) and also for choosing an interleaved assignment of loop iterations to program instances in the sinx example (programming models lecture, slides 007 and 008).
Here, the locality we want to take advantage of is that a processor already has data it needs in local memories, and thus data transfers need not occur.
In the ISPC example, the locality is spatial locality: we wanted all instances to request adjacent data elements at the same time (to allow implementation as an efficient block load, and avoid the need for a more costly gather operation)
This comment was marked helpful 1 times.
ISPC utilizes one core, so in the sinx example interleaved loop iteration improves locality. On the other hand, each block is computed with one core (good locality already under the cluster setting assumption), and thus no need for data transfer.
This comment was marked helpful 0 times.
@kayvonf -- Isn't memory locality just another way of thinking about minimizing communication?
- With the blocked assignment, P2 needs its own local data, plus half a row each from P1 and P3 for every iteration. Additionally, two rows of P2's assigned data get updated by P1 and P3.
- With the interleaved assignment, P2 needs to load pretty much every data element from nonlocal.
The way it's drawn, I think P2 needs 4 non-local pieces of data for every local piece of data! (Of course in a real example it's only a tiny (but nonzero) fraction of nonlocal data, giving the significant memory locality advantage you mentioned compared to this interleaved assignment).
"Maximizing memory locality" doesn't seem all that distinct to me from "minimize data communication" -- is that an astute observation or a flaw in the way I'm thinking about this?
This comment was marked helpful 0 times.
@briandecost: Yes! The presence of locality is an opportunity for sharing, and thus an opportunity for program optimization.
Temporal locality exists when a piece of data is used by a processor multiple times. If the value is cached between the uses, memory-to-processor communication is avoided for all but the first use. The cost of the load from memory is amortized over (a.k.a. shared by) all computations that use the value.
Spatial locality exists when a process accesses a piece of data and then subsequently accesses nearby data. In the example above, data generated in iteration i is used to compute nearby elements in iteration i+1. Thus, if the computation of elements nearby in space is performed on the same processor, communication need not occur.
Another example of spatial locality comes up in the discussion of caches. A load of any one piece of data brings in an entire cache line of data. If the program exhibits high spatial locality in its data accesses, the rest of that line will be used by subsequent loads. Thus, the latency of future loads is small (the data is in cache before the load occurs) and also the entire line is loaded into cache at once using a single batch load operation (rather than individually reading each value from memory).
This comment was marked helpful 0 times.
At first I didn't understand how interleaving improved spatial locality. My misconception was that I only considered that the programCount * iteration + programIndex will be executed serially and was confused how this would improve spatial locality. What I forgot was that since the code is executed in gangs, the spatial locality that is being referred to is the fact that all gang members are requesting data closely to each other, thus improving spatial locality.
This comment was marked helpful 1 times.
To clarify, @markwongsk is referring to the interleaved assignment of data elements to ISPC program instances in the sinx example in Lecture 3, slides 8 and 9.
Prior to this course you probably only considered intra-thread locality. That is, spatial or temporal locality in the operations performed by a single thread of control. Here, this is a case of inter-thread locality (specifically, inter-ISPC-program instance). By inter-thread, I'm referring to locality in data access across concurrently running threads of control. In the interleaves sinx ISPC program example, assignment of work to instances is set up such that different instances access adjacent data elements at the same time. As you can imagine, the hardware can typically handle this situation more efficiently than if the data accessed by each program instance was widely spaced in memory.
In the implementation of sinx, each of the eight program instances simultaneously accesses consecutive elements of the input array: 8 x 4 bytes = 32 total consecutive bytes read.
This comment was marked helpful 0 times.
A brief summary from what @kayvonf said about locality in this example:
We can take advantage of memory locality with blocked assignment as each processor has its block elements stored in local memory, minimizing the time cost of data transfer.
This comment was marked helpful 0 times.



Locks are useful to protect read and write safety. By locking an array or a pointer, the user can guarantee that only one thread can access the critical section at a time. One must be careful when using locks as an improper locking order can cause a deadlock in the program and no work can be achieved.
Barriers are useful if there are multiple highly parallelizable tasks that occur sequentially. Thus, all of the threads can be used on the first task. Then a barrier put in place to make sure that all threads reach that point. Then all the threads can be used for the second task as well. A barrier is necessary in some cases because the user needs to know that their critical section, perhaps an array, will no longer be modified.
This comment was marked helpful 0 times.



Barriers are a synchronization tool that causes threads to wait at a specific location in the program until every thread has reached the same location. In this example, the first barrier is used to make sure that before any thread performs its calculations, every thread correctly sees that the value of diff is 0. The second barrier is used to ensure that every thread has been able to make its update to diff so that it can properly check for the tolerance. The last barrier is needed in the event that the some threads already performed the check and needed to perform the loop again that they do not set diff to 0 to change the result of the check for other threads.
This comment was marked helpful 0 times.
Another important part of this program that is not highlighted is the LOCK and UNLOCK on the diff variable. Since diff is a global variable that is being accessed and updated by all threads, the user must lock the variable before updating it so that there are no concurrency issues. For instance, when thread 0 locks diff to update it, then other threads will not be able to access diff until thread 0 is completed updating and unlocking diff.
This comment was marked helpful 0 times.


Could an alternative method to condense barriers be to only keep barriers that are immediately before code where a thread requires the results from the other threads for its next step of computation? If this barrier passes, each thread can move on assuming that its next round of computation will be required, but only storing new data locally until the barrier is hit again.
For example, in this program, there would only be one barrier before the mydiff computation code, since this code requires the neighboring values that other threads are responsible for. When a thread passes this barrier, it assumes that done is false (even if the program truly should be done after that round). Then, when the barrier is reached again, do the previous round's tolerance check. If it passes, update all information and continue. If it fails, discard the newly computed values, and the global results are still preserved.
This comment was marked helpful 0 times.


Because atomicity of the read-modify-write operation is not ensured in the above example, the result in diff is going to be incorrect since T0 and T1 both load the old value of diff and only add their own partials to it before writing back. At no point do the two partial sums interact. (Note that the example assumes diff is 0 and that 1 is stored in both registers r2.)
This comment was marked helpful 1 times.


For those familiar with Java, the Java synchronized keyword is a good example for the second point on this slide. When you declare a synchronized Java method, you're guaranteed that only at most one thread will ever be executing in that method at any given time.
This comment was marked helpful 0 times.
You can declare synchronized blocks as well!
synchronized (someObjectToUseAsTheLock) {
// critical section
}
This comment was marked helpful 0 times.


The third line of T1: while (flag == 0); is an example of "busy waiting". In bad cases, the "stuff independent of X" that T1 executes could finish much sooner than the code to produce X. If this happens, T1 will waste a bunch of processor cycles by checking the while loop over and over again, instead of allowing other threads to do something useful with said cycles, thus potentially affecting performance non-negligibly.
This comment was marked helpful 0 times.
@dyc: You probably were taught that busy waiting was a poor use of resources: since the thread that is busy waiting is tying up the processor, preventing threads that might set the flag variable to 1 from executing. But this assumes that all relevant threads are sharing the same processing resources.
One thing to consider is whether busy waiting is so bad on a multi-processor system. If you only have two threads in your program, and are running on a machine with two processors, it might be an okay idea -- and even preferable -- to busy-wait! There's no other thread that needs to run that the processor should be released for!
We'll discuss implications (good and bad) of busy-waiting on a parallel system in detail later in the course. It's useful to learn about cache coherence before before discussing the issue in detail.
This comment was marked helpful 0 times.


The loop iterations are not parallelized. Rather, ISPC spawns a gang of program instances of sinx from the main function (from previous lecture). So the there is parallelization of the function but not loop iterations.
This comment was marked helpful 1 times.
The is the ISPC interleaved assignment example from lecture 3, slide 7. While the loop iterations are not parallized, it's worthy to note that each program instance goes through N/programCount iterations of the loop where the iterations are assigned to the instances in an interleaved way as opposed to block assignment.
This comment was marked helpful 0 times.