Question: What happens if we setup ISPC to create gangs of size 8 but each core only has 4 SIMD ALUs? Will we just run 4 and 4 sequentially? Or will groups of 4 be put on two different cores to achieve an 8x speedup?
This comment was marked helpful 0 times.
kayvonf
ISPC's current implementation will run the gang of 8 using two back-to-back 4-wide instructions on the same core.
In the current ISPC implementation the only mechanism to utilize multi-core processing within an ISPC function is to spawn ISPC tasks.
This comment was marked helpful 0 times.
mmp
One reason for that design decision is that ISPC provides a number of guarantees about how and when the program instances in a gang can communicate values between each other; they're allowed to do this effectively after each program statement. If a group of 8 was automatically split over two cores, then fulfilling those guarantees would be prohibitively expensive. (So better to let the programmer manage task decomposition through a separate explicit mechanism...) For further detail, see my extended comment on slide 7.
This comment was marked helpful 0 times.
akashr
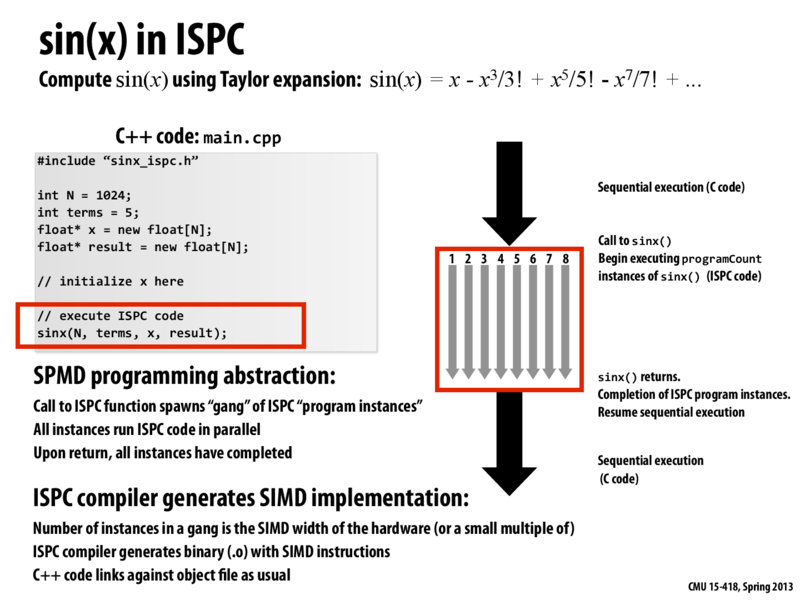
Everything before the sinx function call is done in sequential order. When we call the sinx function, the ISPC compiler takes over and starts generating the gang. The number of instances that we do get depends on the hardware as well. For example, the 5205/5202 machines have a SIMD width of 4. Once the instances are generated, we will begin executing instances of sinx function. We should be aware be that these are not threads, but rather just instances of a gang that run in parallel. We are taking advantages of the SIMD instructions within the processor for this to work. The order of the how the work is split between the different instances depends on how the ISPC function is written in the first place. Once the ISPC function finishes running, we will return back to the code and start resuming in sequential order.
@Thanks dmatlack
This comment was marked helpful 0 times.
chaominy
Question: Is the number of program instances determined by the number of SIMD units and the compile option SSE2/SSE4/AVX ?
This comment was marked helpful 0 times.
kayvonf
The number of program instances is determined entirely by the compiler option --target. The correct value of target is largely a function of the SIMD width of the machine. (That is, the type of SIMD instructions the CPU supports, e.g., SSE4 and AVX).
There's a default value for target for each CPU, but in your Makefiles we've explicitly set it to --target=sse4-x2 for the Gates machines. This tells ISPC to generate SSE4 instructions, but use a gang size of 8 rather than the obvious size of 4. We've found this to generate code that executes a little faster than the --target=sse4 option.
This comment was marked helpful 0 times.
dmatlack
@aksahr I think the GHC 5 machines have a SIMD width of 4 rather than 2 (see lecture 2, slide 35)
This comment was marked helpful 0 times.
acappiello
To demonstrate the differences in compiling with different --target options, namely how the double-width is handled, I made a small test program:
export void foo(uniform int N, uniform float input[], uniform float output[])
{
for (uniform int i = 0; i < N; i+= programCount) {
output[i + programIndex] = 5 * input[i + programIndex] + 7;
}
}
It's easy to find the duplicated instructions in the double width output.
The avx dumps were similar. It's interesting that the movups instructions for each group of 4 are done one after another, but the mulps and addps are grouped.
This comment was marked helpful 5 times.
max
Question: Did "unrolling the loop" refer to compiling with a different --target option, or was something else being changed to improve the performance?
This comment was marked helpful 0 times.
unihorn
I think both ways can lead to "unrolling the loop". When compiling with sse4-x2 instead of sse4, the compiler makes the decision of unrolling, which can be discovered from above example. This actually explains why it says 8-width ISPC. On the other hand, it can be done manually too. If you rewrite the code and unroll the loop, "unrolling the loop" can be observed in assembly file, too.
This comment was marked helpful 0 times.
kayvonf
@unihorn: But only by using --target=sse4-x2 will the ISPC gang size be eight (programCount = 8). In this situation almost every operation in the ISPC program gets compiled to two four-wide SIMD instructions. This has nothing to do with the for loop in the code examples, and has everything to do with ISPC needing to implement the semantic that all logic within an ISPC function (unless it pertains to uniform values) is executed by all instances in a gang.
As you point out, in the case of the for loop example above or the sinx example from lecture, it would be possible to get an instruction schedule that looked a lot like the gang-size-8 schedule if you configured ISPC to generate code with a gang size of four, but then modified the ISPC program so that the loop is manually unrolled.
Question: To check your understanding, consider an ISPC function without a for loop in it. How would you modify the ISPC code to get a compiled instruction sequence using gang-size 4 that was similar to what might be produced with gang-size 8.
This comment was marked helpful 0 times.
pebbled
@kayvon: I'm having trouble thinking of an ISPC function without a for loop which could be compiled for both gang sizes 4 and 8. A loop is the most natural way to break work up into pieces of programCount size. Without this, it seems we would have to case on programCount, or else the behavior of our function would be determined by a compiler flag.
Question: What happens if we setup ISPC to create gangs of size 8 but each core only has 4 SIMD ALUs? Will we just run 4 and 4 sequentially? Or will groups of 4 be put on two different cores to achieve an 8x speedup?
This comment was marked helpful 0 times.
ISPC's current implementation will run the gang of 8 using two back-to-back 4-wide instructions on the same core.
http://ispc.github.com/perfguide.html#choosing-a-target-vector-width
In the current ISPC implementation the only mechanism to utilize multi-core processing within an ISPC function is to spawn ISPC tasks.
This comment was marked helpful 0 times.
One reason for that design decision is that ISPC provides a number of guarantees about how and when the program instances in a gang can communicate values between each other; they're allowed to do this effectively after each program statement. If a group of 8 was automatically split over two cores, then fulfilling those guarantees would be prohibitively expensive. (So better to let the programmer manage task decomposition through a separate explicit mechanism...) For further detail, see my extended comment on slide 7.
This comment was marked helpful 0 times.
Everything before the
sinxfunction call is done in sequential order. When we call thesinxfunction, the ISPC compiler takes over and starts generating the gang. The number of instances that we do get depends on the hardware as well. For example, the 5205/5202 machines have a SIMD width of 4. Once the instances are generated, we will begin executing instances ofsinxfunction. We should be aware be that these are not threads, but rather just instances of a gang that run in parallel. We are taking advantages of the SIMD instructions within the processor for this to work. The order of the how the work is split between the different instances depends on how the ISPC function is written in the first place. Once the ISPC function finishes running, we will return back to the code and start resuming in sequential order.@Thanks dmatlack
This comment was marked helpful 0 times.
Question: Is the number of program instances determined by the number of SIMD units and the compile option SSE2/SSE4/AVX ?
This comment was marked helpful 0 times.
The number of program instances is determined entirely by the compiler option
--target. The correct value of target is largely a function of the SIMD width of the machine. (That is, the type of SIMD instructions the CPU supports, e.g., SSE4 and AVX).There's a default value for target for each CPU, but in your Makefiles we've explicitly set it to
--target=sse4-x2for the Gates machines. This tells ISPC to generate SSE4 instructions, but use a gang size of 8 rather than the obvious size of 4. We've found this to generate code that executes a little faster than the--target=sse4option.This comment was marked helpful 0 times.
@aksahr I think the GHC 5 machines have a SIMD width of 4 rather than 2 (see lecture 2, slide 35)
This comment was marked helpful 0 times.
To demonstrate the differences in compiling with different
--targetoptions, namely how the double-width is handled, I made a small test program:It's easy to find the duplicated instructions in the double width output.
sse4:
sse4-x2:
The avx dumps were similar. It's interesting that the
movupsinstructions for each group of 4 are done one after another, but themulpsandaddpsare grouped.This comment was marked helpful 5 times.
Question: Did "unrolling the loop" refer to compiling with a different
--targetoption, or was something else being changed to improve the performance?This comment was marked helpful 0 times.
I think both ways can lead to "unrolling the loop". When compiling with sse4-x2 instead of sse4, the compiler makes the decision of unrolling, which can be discovered from above example. This actually explains why it says 8-width ISPC. On the other hand, it can be done manually too. If you rewrite the code and unroll the loop, "unrolling the loop" can be observed in assembly file, too.
This comment was marked helpful 0 times.
@unihorn: But only by using
--target=sse4-x2will the ISPC gang size be eight (programCount = 8). In this situation almost every operation in the ISPC program gets compiled to two four-wide SIMD instructions. This has nothing to do with theforloop in the code examples, and has everything to do with ISPC needing to implement the semantic that all logic within an ISPC function (unless it pertains touniformvalues) is executed by all instances in a gang.As you point out, in the case of the
forloop example above or thesinxexample from lecture, it would be possible to get an instruction schedule that looked a lot like the gang-size-8 schedule if you configured ISPC to generate code with a gang size of four, but then modified the ISPC program so that the loop is manually unrolled.Question: To check your understanding, consider an ISPC function without a for loop in it. How would you modify the ISPC code to get a compiled instruction sequence using gang-size 4 that was similar to what might be produced with gang-size 8.
This comment was marked helpful 0 times.
@kayvon: I'm having trouble thinking of an ISPC function without a for loop which could be compiled for both gang sizes 4 and 8. A loop is the most natural way to break work up into pieces of
programCountsize. Without this, it seems we would have to case onprogramCount, or else the behavior of our function would be determined by a compiler flag.This comment was marked helpful 0 times.