






Question Just to make sure, if we have 8 program instances and if one of the instances takes much longer time than the other seven of them, do the other seven instances wait doing nothing until the slower instance is over?
This comment was marked helpful 0 times.

Good question. Conceptually yes. The semantics of the ISPC program are that when reaching the end of the ISPC function body, all instances wait until the entire gang has completed. Then control returns to the calling C code.
But your question seems to be more about the actual implementation, not the semantics. Now that you know that a gang of ISPC program instances is implemented as a sequence of SIMD instructions, and you know about SIMD execution, you are equipped to answer your question. Can someone take a shot?
One reason the instances might take different amounts of time to complete is that they execute different sequences of instructions (one instance might have more to do, and thus run longer). That is not the case in the above code as all instances will execution the execute same sequence. (Self-test: Do you see why this is true?)
However if the instances did execute different logic, and require different instruction sequences, as they may for the program written on this slide, then you can imagine an implementation might have to employ the techniques we discussed last lecture about mapping conditional control flow to SIMD hardware. In light of this implementation, can you now answer your question?
Also see http://ispc.github.com/ispc.html#control-flow
This comment was marked helpful 0 times.


Question: What happens if we setup ISPC to create gangs of size 8 but each core only has 4 SIMD ALUs? Will we just run 4 and 4 sequentially? Or will groups of 4 be put on two different cores to achieve an 8x speedup?
This comment was marked helpful 0 times.
ISPC's current implementation will run the gang of 8 using two back-to-back 4-wide instructions on the same core.
http://ispc.github.com/perfguide.html#choosing-a-target-vector-width
In the current ISPC implementation the only mechanism to utilize multi-core processing within an ISPC function is to spawn ISPC tasks.
This comment was marked helpful 0 times.

One reason for that design decision is that ISPC provides a number of guarantees about how and when the program instances in a gang can communicate values between each other; they're allowed to do this effectively after each program statement. If a group of 8 was automatically split over two cores, then fulfilling those guarantees would be prohibitively expensive. (So better to let the programmer manage task decomposition through a separate explicit mechanism...) For further detail, see my extended comment on slide 7.
This comment was marked helpful 0 times.

Everything before the sinx function call is done in sequential order. When we call the sinx function, the ISPC compiler takes over and starts generating the gang. The number of instances that we do get depends on the hardware as well. For example, the 5205/5202 machines have a SIMD width of 4. Once the instances are generated, we will begin executing instances of sinx function. We should be aware be that these are not threads, but rather just instances of a gang that run in parallel. We are taking advantages of the SIMD instructions within the processor for this to work. The order of the how the work is split between the different instances depends on how the ISPC function is written in the first place. Once the ISPC function finishes running, we will return back to the code and start resuming in sequential order.
@Thanks dmatlack
This comment was marked helpful 0 times.

Question: Is the number of program instances determined by the number of SIMD units and the compile option SSE2/SSE4/AVX ?
This comment was marked helpful 0 times.
The number of program instances is determined entirely by the compiler option --target. The correct value of target is largely a function of the SIMD width of the machine. (That is, the type of SIMD instructions the CPU supports, e.g., SSE4 and AVX).
There's a default value for target for each CPU, but in your Makefiles we've explicitly set it to --target=sse4-x2 for the Gates machines. This tells ISPC to generate SSE4 instructions, but use a gang size of 8 rather than the obvious size of 4. We've found this to generate code that executes a little faster than the --target=sse4 option.
This comment was marked helpful 0 times.
@aksahr I think the GHC 5 machines have a SIMD width of 4 rather than 2 (see lecture 2, slide 35)
This comment was marked helpful 0 times.

To demonstrate the differences in compiling with different --target options, namely how the double-width is handled, I made a small test program:
export void foo(uniform int N, uniform float input[], uniform float output[])
{
for (uniform int i = 0; i < N; i+= programCount) {
output[i + programIndex] = 5 * input[i + programIndex] + 7;
}
}
It's easy to find the duplicated instructions in the double width output.
sse4:
1e3: 0f 10 14 06 movups (%rsi,%rax,1),%xmm2
1e7: 0f 59 d0 mulps %xmm0,%xmm2
1ea: 0f 58 d1 addps %xmm1,%xmm2
1ed: 0f 11 14 02 movups %xmm2,(%rdx,%rax,1)
sse4-x2:
333: 0f 10 14 06 movups (%rsi,%rax,1),%xmm2
337: 0f 10 5c 06 10 movups 0x10(%rsi,%rax,1),%xmm3
33c: 0f 59 d0 mulps %xmm0,%xmm2
33f: 0f 58 d1 addps %xmm1,%xmm2
342: 0f 59 d8 mulps %xmm0,%xmm3
345: 0f 58 d9 addps %xmm1,%xmm3
348: 0f 11 5c 02 10 movups %xmm3,0x10(%rdx,%rax,1)
34d: 0f 11 14 02 movups %xmm2,(%rdx,%rax,1)
The avx dumps were similar. It's interesting that the movups instructions for each group of 4 are done one after another, but the mulps and addps are grouped.
This comment was marked helpful 5 times.

Question: Did "unrolling the loop" refer to compiling with a different --target option, or was something else being changed to improve the performance?
This comment was marked helpful 0 times.

I think both ways can lead to "unrolling the loop". When compiling with sse4-x2 instead of sse4, the compiler makes the decision of unrolling, which can be discovered from above example. This actually explains why it says 8-width ISPC. On the other hand, it can be done manually too. If you rewrite the code and unroll the loop, "unrolling the loop" can be observed in assembly file, too.
This comment was marked helpful 0 times.
@unihorn: But only by using --target=sse4-x2 will the ISPC gang size be eight (programCount = 8). In this situation almost every operation in the ISPC program gets compiled to two four-wide SIMD instructions. This has nothing to do with the for loop in the code examples, and has everything to do with ISPC needing to implement the semantic that all logic within an ISPC function (unless it pertains to uniform values) is executed by all instances in a gang.
As you point out, in the case of the for loop example above or the sinx example from lecture, it would be possible to get an instruction schedule that looked a lot like the gang-size-8 schedule if you configured ISPC to generate code with a gang size of four, but then modified the ISPC program so that the loop is manually unrolled.
Question: To check your understanding, consider an ISPC function without a for loop in it. How would you modify the ISPC code to get a compiled instruction sequence using gang-size 4 that was similar to what might be produced with gang-size 8.
This comment was marked helpful 0 times.

@kayvon: I'm having trouble thinking of an ISPC function without a for loop which could be compiled for both gang sizes 4 and 8. A loop is the most natural way to break work up into pieces of programCount size. Without this, it seems we would have to case on programCount, or else the behavior of our function would be determined by a compiler flag.
This comment was marked helpful 0 times.


The key idea in the ISPC code lies is the first for loop. This loop should compute the sine of N numbers. This code cuts these N computations into chunks of size programCount. Each chunk of size programCount is run in parallel.
Each program instance computes the elements of the array i when i mod N = programIndex.
This comment was marked helpful 0 times.

This interleaved implementation is preferred to the blocked implementation in the next slide because with interleaved program instances when the program instances read memory (all at the same time), that memory is contiguous and easy to grab all at once.
This comment was marked helpful 0 times.

Question: Is this the same idea as a shader, e.g. GLSL?
This comment was marked helpful 0 times.
Close. Graphics shading languages like GLSL or HLSL are designed to provide a more "pure" data-parallel set of abstractions. Thus a GLSL program looks a lot more like my example data-parallel/stream programming abstractions on slide 37. You write the kernel function (a.k.a., a GLSL shader), and it is executed by the graphics system once per element of an input stream of vertices/fragments/etc. There is no way to reference any data but the stream element the kernel are provided (plus some per-kernel read-only state such as textures). In fact I almost decided to use GLSL as an example there, but was worried about confusing those that have not taken 15-462.
This comment was marked helpful 0 times.

Question: Can I understand the uniform modifier in this way:
It is like a static modifier in a java class, all of the instances of this class share the same value of this variable, while the variable without uniform modifier in a ispc program is like private, only this instance has access to this variable.
This comment was marked helpful 0 times.
@yingchal: That's an okay (but not perfect) analogy. I'll say it another way: All program instances in an ISPC gang share a single instance of a uniform variable. This is similar to a per-thread-block shared variable in CUDA. Non-uniform variables are local to the program instance, so each ISPC program instance maintains a potentially unique value for the variable. Uniform variables go out of scope when the gang completes.
This comment was marked helpful 0 times.
Question: There is a nested for loop in this example. We could use ISPC gangs on variable i, or on variable j. Using on i and j at the same time are forbid currently. Does it have the same effect on both ways? If not, how can we decide on it?
This comment was marked helpful 0 times.
I'd like to see someone else try and answer @unihorn's question. There is a nested loop in this example. Which iterations (if any) are parallelized by ISPC? Which are not? Hint: think carefully!!! If you get this answer right you've got a good command of the implementation of the ISPC language.
This comment was marked helpful 0 times.

I'll take a stab.
If I understand the question correctly, I think the answer to @unihorn's question is: gang instances are not assigned to loops.
The abstraction we are using here is SPMD (single program, multiple data). Thus ISPC spawns a gang of programCount instances of sinx. There is no parallelization of loop iterations; rather there are multiple instances of the function running which execute in parallel.
This comment was marked helpful 2 times.

The video related to this lecture mentioned the abstraction and implementation of ISPC. I am still not quite sure about their differences. My understanding is:
ISPC abstraction: your SPMD program will run the code on a gang of program instances, and return only after all of them have finished.
ISPC implementation: a gang of program instances will be run on the SIMD lanes on the same core.
Is that right? If yes, I still have confusion that why "run on the SIMD lanes of the same core" is not part of the answer to "what is the abstraction of ISPC"? (how it is implemented may have side effect, why don't we need to include that in the abstraction?)
This comment was marked helpful 0 times.
@TeBoring: The notion of a "gang of program instances" is an abstraction in itself- really these independent pieces of computation are compiled into a single stream of (4/8/...-wide SSE/AVX/...) instructions which are run sequentially on a single core. These instructions are capable of manipulating multiple pieces of data stored in a special register file (XMM/YMM on SSE4/AVX chips).
This implementation has no side effects other than those made plain by the abstraction: if multiple program instances mess with the same data, there will be race conditions. It doesn't matter whether the threads of execution are being concurrently scheduled on a single-core processor, run in parallel on multiple cores, or secretly combined into a single sequential stream of wider instructions. (Of course there are differences in performance, but optimization time is when we disabuse ourselves of this abstraction)
This comment was marked helpful 1 times.
@TeBoring: Your description of the ISPC programming model abstraction and the ISPC implementation is completely correct. However, given the semantics of the ISPC programming model, alternative implementations are also possible. For example, for the program above, a perfectly valid ISPC compiler might not emit AVX instructions and simply emit a sequential binary that executes the logic from each of the program instances one after each other. The resulting compiled binary is correct -- it computes what the program specifies it should compute -- it's just slow). Alternatively, it would be valid for the compiler to have spawned eight pthreads, one for each program instance to carry out the logic on eight cores.
The point is that there is nothing in the basic ISPC model that dictates this choice and the programmer need not think about the implementation if he/she simply wants to create a correct program. However, as I'm sure it's now clear in this class, the programmer will need to think about the underlying implementation if an efficient program is desired.
Now, I'm being a little loose with my comments here because there are in fact certain details in ISPC that do put constraints on the implementation. One example is the cross-instance functions (e.g, reduceAdd), which do place a scheduling constraint on execution. Since reduceAdd entails communication of values between program instances, all program instances must run up until this point in the program to determine what values to communicate. (Otherwise, it's impossible to perform the reduction!) Consider an ISPC function that contains a reduceAdd. The ISPC system can not run instance 0 to completion before starting instance 1 because the reduceAdd operation, which must be executed as part of instance 0, depends on values computed by instance 1.
This comment was marked helpful 0 times.
Clarification and corrections on @kayvonf: The implementation of ISPC is actually a bit more constrained by the language semantics (and I'll argue that's a good thing.) It'd be difficult to provide an implementation of ISPC that used one CPU hardware thread (think: pthread) per program instance and ran efficiently.
ISPC guarantees that program instances synchronize after each program sequence point, which is roughly after each statement. This allows writing code like:
uniform float a[programCount];
a[programIndex] = foo();
return a[programCount - 1 - programIndex];
In the third line, program instances are reading values written by other program instances in line 2. This is valid ISPC, and is one of the idiomatic ways to express communication between the program instances. (See The ISPC User's Guide for details.)
So one implication of this part of the language abstraction is certainly that it constrains viable implementation options; perhaps one could implement ISPC by spawning a pthread per program instance, but it'd be necessary for the compiler to conservatively emit barriers at places where it was possible that there would be inter-program instance communication. This in turn is tricky because:
In a language with a C-based pointer model like ISPC, the compiler has to be pretty conservative about what a pointer may actually point to.
Barrier synchronization on CPUs is sort of a pain to do efficiently. (This is a challenge for CPU OpenCL implementations; see discussion in this paper for some details and further references.
Both of these also mean that an implementation that implemented program instances as one-to-one with CPU HW threads would make it much harder for the programmer to reason about their program's performance; small changes to the input program could cause large performance deltas, just because they inadvertently confused the compiler enough about what was actually going on that it had to add another barrier. Especially for a language that is intended to provide good performance transparency to the programmer, this is undesirable.
In the end, I don't think there is any sensible implementation of an ISPC gang other than one that ran on SIMD hardware. Indeed, if you take out the foreach stuff in the language and just have the programCount/programIndex constructs, you can look at what is left as C extended with thin abstractions on top of the SIMD units, not even an explicitly parallel language at all. (In a sense.)
This comment was marked helpful 0 times.


The difference between the code on this slide and the previous one is the assignment of work to program instances. On this slide, each program instance is responsible for computing the sine of the values in a chunk of the array. The same work gets done, but in a different order. The version on the previous slide is more efficient and is how the "foreach" loop would divide up the work, for reasons explained in a comment there.
This comment was marked helpful 2 times.


The difference between this code and the previous ones is in this code, each "foreach" is independent. We don't really care how to distribute them in multiple program instances. And they can be computed in any order.
This comment was marked helpful 0 times.
You mentioned in the lecture that the order in which the calculations are done in the array for this code can be done in any order. Question: Is the compiler smart enough to realize that we can look through the array x here in order and do the calculations in order so that we get the least data loads from memory? Or do we have to manually do it like we did 2 slides ago?
This comment was marked helpful 0 times.
In response to akashr's question, I actually feel that the interweaving process is not only the smartest choice, but the easiest to implement by the compiler. So it is a safe bet that they are done in order. Number one rule though: No Guarantees!
This comment was marked helpful 0 times.
This is a good example of the value of the difference between abstraction and implementation.
The ISPC language/execution model spec does allow the compiler to try to choose an ordering that made memory access as coherent or regular as possible; that could be an interesting thing to try.
The current implementation doesn't do that, though; it currently ends up doing a straightforward mapping of the iteration range to program instances. I think this is actually a reasonable approach for two reasons.
First, I would guess that such an optimization would be nice for simple cases, but wouldn't be less frequently useful for more complex programs. For the simple ones, it's easy enough to rewrite the loop to be more coherent anyway.
Second, one problem with this kind of "smart" compiler optimization is that, paradoxically, it can be a pain for the programmer in that it makes it hard to have a clear mental model of what the compiler will do. e.g. if you're a good programmer and you expect that optimization to kick in in some case but then it doesn't (due to some unknown implementation limitation in the compiler), then what do you do? What if it kicks in when you don't want it to and that you really did mean to write the loop that way, thank you very much? In general, this sort of optimization makes it harder to predict what the compiler output will be, which is undesirable for performance-oriented programmers. (That said, if the programmer isn't performance oriented, this sort of thing would make more sense, since one might assume they won't do anything themselves on this front, so better to at least sometimes see a performance benefit from doing it for them.)
Now, given that last point, one might argue that it would be better if the ISPC spec defined a particular execution order for "foreach" loops, so that programmers can reason about the memory access patterns that will result when they use this construct! (At least the current implementation provides that predictability.)
This comment was marked helpful 0 times.

Question:
It seems like using foreach gives the compiler more flexibility than having the programmer write code using programIndex to manually assign work to specific instances. But looking at the discussion, it seems to be simply for convenience for us coders... Then, is there any benefits using programIndex? Will having control over "how tasks are assigned" using programIndex give us some chance to optimize/speedup our program? It seems like there might be a "smart" ways create gangs of even amount of work but that might come with good amount of overheads...
This comment was marked helpful 0 times.


Since read-modify-write operation may be not atomic. If two program instances try to modify sum simultaneously, the sum may be incorrect. So one way to solve it is to create partial sum for each program instance. "partial" in each instance can only be modified by one instance so that correctness can be guaranteed.
This comment was marked helpful 0 times.

It is also significant to note that one should only return uniform variables, something that each program instance has in common with one another.
This comment was marked helpful 0 times.

Question: Can someone please tell me how reduceAdd() works conceptually?
This comment was marked helpful 0 times.
The input to reduceAdd is of type per-instance float. The output of reduceAdd is of type uniform float.
The semantics of uniform float sum = reduceAdd(partial) above are as follows:
You can think about reduceAdd running once per gang, not once per program instance. reduceAdd accepts as input the individual values of partial for each instance in the gang, computes their sum, and then returns a single value as a result, which is stored into the uniform value sum.
Note that this is a form of inter-instance communication. ISPC provides special language built-in functions like reduceAdd for this purpose.
This comment was marked helpful 0 times.

Question: What does the prefix _mm256 mean?
This comment was marked helpful 0 times.

It uses 256 bit registers. Reference.
This comment was marked helpful 0 times.

Based on the implementation of ISPC, it seems that there will never be a need for barrier synchronization or join within an ISPC function, as all program instances execute the same instructions (with some SIMD lanes turned off in case of divergence). Is this understanding correct? However, since we can have more program instances than number of SIMD lanes, how is this ensured? Or do we have to use specialized primitives like reduceAdd whenever we want some kind of barrier synchronization?
This comment was marked helpful 0 times.
ISPC essentially guarantees that the instances within a gang will be re-synchronized after each program statement (more specifically, at "sequence points" in the program, which is a concept that comes from the C standard). See some more discussion here: http://ispc.github.com/ispc.html#data-races-within-a-gang.
Thus, there isn't any need for barrier synchronization or the like between the program instances in a gang. If one is also executing across multiple cores, then ISPC currently only supports launching tasks and waiting for tasks to complete; the tasks aren't supposed to coordinate with each other while executing.
It might be worthwhile for ISPC to support more options for expressing computation across multiple cores, in which case barrier sync or the like would be useful...
This comment was marked helpful 0 times.


Since the GHC 5205 machines each have four cores, executing an ISPC program with a specified number of tasks expands the execution of the SIMD instructions from only one core to the four cores of the machine. As we can see in Assignment 1 when we execute ISPC with tasks, this achieve multi-core execution thus giving us a greater speedup than if we simply ran ISPC code without tasks.
This comment was marked helpful 0 times.

If you look at the source code for the ISPC task system implementation, we can see that the compiler creates n-1 more pthreads where n is the number of cores. Each of these thread removes jobs from a shared task queue. It seems interesting that the implementation for the task abstraction that we use when writing ISPC programs, at least for assignment, actually uses another abstraction that we're more familiar with.
This comment was marked helpful 1 times.
Going back to Problem 4, part 3, we realized ISPC implementation is actually slower than serial implementation when we have gangs of seven 1s and one 2.999999. First, it seems like it is impossible for ISPC to be slower than serial because serial has to run seven 1s and one 2.999999 to finish "one gang" while ISPC should only take 2.999999 amount plus alpha (interweaved with one "1" task, i think...) of time to finish "one gang" (because 1s finish earlier in parallel). Thus, only reason for the slow down must be overhead on using ISPC, work it takes to allocate tasks to separate SIMD cores (4 ALUs) or work it takes to gather returned data from different cores, or some other overheads. Are we going to talk about these overheads some time? And, how big are these overheads?
This comment was marked helpful 0 times.
@raphaelk. There's one little detail you're overlooking (but you won't lose points for this since you got the gist of the question... which was to create an input that triggered maximally divergent execution). The reason for the slowdown is not ISPC "overhead" in assignment work as you suggest. Remember that we set the gang size to eight, so the ISPC implementation is going to run all eight instances for the entire 2.999 input control sequence. However, since the gang size is 8 and the SIMD width of the GHC 5201/5205 Intel CPUs is only 4, you end up running two instructions to implement each gang operation on all eight instances. As a result the ISPC code runs twice as many instructions as a sequential implementation of 2.999. Thus, the run time is much longer than a sequential implementation handling a single 2.999 input followed by seven 1.0 inputs. We were being a little tricky here. Your assessment of the situation: that overhead would be the only reason the ISPC implementation would be slower than sequential code, would certainly be correct if the gang size was set to four.
This comment was marked helpful 0 times.

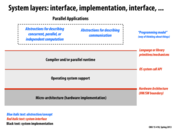

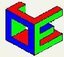
It is important to note that this isn't a simple matter of an abstraction and an implementation. The reality is that there are several layers of abstractions and implementations built upon each other that shouldn't be confused with each other. This follows from the critical theme of this lecture, that conflating abstraction with implementation is a common cause for confusion.
This comment was marked helpful 0 times.


This is a great example of implementation and abstraction hierarchies. As we can see, just calling pthread_create() spawns a whole series of calls that include both interfaces and implementations. pthread_create() is the interface for the common threading library, but under the hood it has an implementation which does a call to a system API's interface. This interface must also have an implementation which makes another call to the x86-64 architecture's interface, and so on.
This comment was marked helpful 0 times.
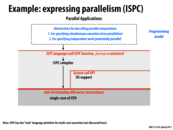

For the ISPC task abstraction, it will create n-1 more pthreads where n is the number of cores together with the main thread to do the tasks from a task pool. (At least in our assignment, the task abstraction uses pthread model, which can be found in asst1_src/common/tasksys.cpp).
So the hierarchy is similar to the pthread hierarchy in the previous slide as a whole, while for each individual task, it is under the model in this slide.
This comment was marked helpful 0 times.


All threads have access to the same variables. To guarantee atomicity, tools like locks are used to make sure only one thread accesses a variable at a time.
This comment was marked helpful 0 times.

Question: If x is shared, why do we declare int x in both threads?
This comment was marked helpful 0 times.
@ypk: I think the slide is pseudocode ;) Here's (bad) pthread code for the above:
#include stdio.h
#include stdlib.h
#include pthread.h
void *set(void *var);
void *test(void *var);
main() {
pthread_t thread1, thread2;
int x = 0;
pthread_create(&thread1;, NULL, set, &x);
pthread_create(&thread2;, NULL, test, &x);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
exit(0);
}
void *set(void *var) {
*(int *)var = 1;
}
void *test(void *var) {
while (!(*(int *)var));
printf("x has been set: %d!\n", *(int *)var);
}
This comment was marked helpful 0 times.
@pebbled: Compile it and give it a shot. I think it'll behave like you expect when compiled with no optimizations, and thread2 may hang looping endlessly in the while loop when compiled with -O3.
This comment was marked helpful 0 times.

@kayvonf: Tested. It works fine with no optimizations, but even with -O1 (and -O2 and -O3) it hangs.
@pebbled: Pedantic compiler errors (edit, maybe?): there are extraneous semicolons in pthread_create (after "&thread1;"), #includes need angle brackets, and main wants a return type.
This comment was marked helpful 0 times.

@jpaulson: Even more pedantic compiler correction:
If the return type of the
mainfunction is a type compatible withint, a return from the initial call to themainfunction is equivalent to calling theexitfunction with the value returned by the main function as its argument; reaching the}that terminates themainfunction returns a value of 0.
C99 Standard 5.1.2.2.3
main should have a declared return type of int, though. (5.1.2.2.1)
This comment was marked helpful 0 times.
Hint: See the definition of the C language's volatile type modifier. Let's get this code working!
Some useful discussions:
- http://stackoverflow.com/questions/9935190/why-is-a-point-to-volatile-pointer-like-volatile-int-p-useful
- http://en.wikipedia.org/wiki/Volatile_variable
This comment was marked helpful 0 times.
The following code works, which surprised me: (I expected that I would have to write volatile int x, but I don't, and in fact declaring x as volatile gives warnings).
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void *set(void *var);
void *test(void *var);
int main() {
pthread_t thread1, thread2;
int x = 0;
pthread_create(&thread1;, NULL, set, &x);
pthread_create(&thread2;, NULL, test, &x);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
exit(0);
}
void *set(void *var) {
*(volatile int *)var = 1;
}
void *test(void *var) {
while (!(*(volatile int *)var));
printf("x has been set: %d!\n", *(int *)var);
}
This comment was marked helpful 0 times.
As noted in the Wikipedia article @kayvonf linked, the volatile type class is not appropriate for synchronization between threads:
In C, and consequently C++, the volatile keyword was intended to[1]
- allow access to memory mapped devices
- allow uses of variables between setjmp and longjmp
- allow uses of sig_atomic_t variables in signal handlers.
Operations on volatile variables are not atomic, nor do they establish a proper happens-before relationship for threading.
The use of volatile for thread synchronization happens to work on x86 because that architecture defines an extremely robust memory model (See Intel Developer Manual 3A section 8.2). Other architectures may not ensure that the write to x in the set thread is ever made visible to the thread running test. Processors with relaxed memory models like this do exist. For example, in CUDA
The texture and surface memory is cached (see Device Memory Accesses) and within the same kernel call, the cache is not kept coherent with respect to global memory writes and surface memory writes, so any texture fetch or surface read to an address that has been written to via a global write or a surface write in the same kernel call returns undefined data.
The C11 standard added the stdatomic.h header defining atomic data types and operations. The set and test functions would call atomic_store and atomic_load and the compiler would insert any memory barriers necessary to ensure everything would work on whatever architecture the program is being compiled on. Compilers also usually have atomic builtin functions. GCC's are here.
See also Volatile Considered Harmful for a view from a kernel programmer's perspective.
This comment was marked helpful 2 times.
@sfackler: The issue here is not atomicity of the update to the flag variable x. (Atomicity is ensured in that a store of any 32-bit word is atomic on most systems these days.) The code only requires that the write of the value 1 to x by a processor running the "set" thread ultimately be visible to the processor running the "test" thread that issues loads from that address.
@jpaulson's code should work on any system that provides memory coherence. It may not work on a system that does not ensure memory coherence, since these systems do not guarantee that writes by one processor ultimately become visible to other processors. This is true even if the system only provides relaxed memory consistency. Coherence and consistency are different concepts, and their definition has not yet been discussed in the class. We are about two weeks away.
Use of volatile might no longer be the best programming practice, but if we assume we are running on a system that guarantees memory coherence (as all x86 systems do), the use of volatile in this situation prevents an optimizing compiler from storing the contents of the address *var in a register and replacing loads from *var with accesses to that register. With this optimization, regardless of when the other processor observes that the value in memory is set to one (and a cache coherent system guarantees it ultimately will), the "test" thread never sees this update because it is spinning on a register's value (not the results of the load from *var).
This comment was marked helpful 0 times.

It gets worse. Here's a paper from 2008 that talks about compiler bugs related to volatile:
http://www.cs.utah.edu/~regehr/papers/emsoft08-preprint.pdf
This comment was marked helpful 1 times.


This reminded me of the Rendezvous synchronization primitive.
This comment was marked helpful 0 times.

NVIDIA Cuda uses option 2 with keyword shared.
This comment was marked helpful 0 times.

Communication between threads in the shared address space model is primarily done using shared variables that act as locks or as data. How is the mapping of each thread's virtual address space determined as to ensure both common and private portions of physical location?
This comment was marked helpful 0 times.

@rutwikparikh Normally, the operating system has a tree to find the physical memory regions that contain a given virtual address, and the tree's nodes contain information on what is private and what is shared. Likewise, the kernel virtual memory needs to be concurrent to support this.
This comment was marked helpful 0 times.
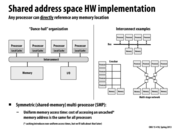
The diagram on the left shows the "Dance-hall" organization (an abstraction of a shared address space), in which processors can directly access memory via the Interconnect. The diagram on the right provides different examples of implementations of such an abstraction.
This comment was marked helpful 0 times.
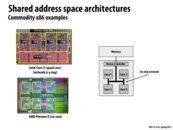
Note the size of the crossbar. It scales with an increasing number of cores, as it requires $ n^2 $ connections.
This comment was marked helpful 0 times.

Even though crossbars are considered to be one of the least scalable network topologies, there has been recent work (both by industry and academia) that have looked at scaling crossbar designs to a large number of endpoints. This includes new chip fabrication and packaging technologies (http://labs.oracle.com/projects/sedna/Papers/SC08.pdf), as well as architectural and layout optimizations (http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=06171053). As you will see later in the Interconnection Networks lecture, the major benefits of the crossbar topology are that it offers very high performance (high throughput, internally non-blocking) and uniform and low latency.
This comment was marked helpful 0 times.
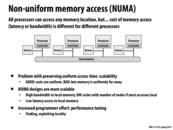
Memory access on lecture 3, slide 26 was more cost uniform because the memory locations were about the same distance from every processor. As we can see on this slide, the memory locations are not the same distance from each processor leading to differences in cost of memory access.
This comment was marked helpful 0 times.

Just to rephrase; If I understand correctly, a given processor will allocate memory at closer addresses?
This comment was marked helpful 0 times.
Clarity alert! Processors don't allocate memory. Processors just execute instructions, some of which load and store from memory. Programs however, can allocate memory. As you learned in 15-213, the OS decides how regions of a processes virtual address space (allocated by a program) map to physical memory locations in the machine. It would be advisable for an operating system to set up first memory mappings so memory is near to the processor that is most likely to access it.
Let me explain the slide in more detail: This slide shows a parallel computer where main system memory is not one big monolithic unit, but is instead partitioned into four physical memories. Each memory is located close to a processor. Each processor can access its "nearby" memory with lower latency (and potentially higher bandwidth) than the memories that are farther way.
Let's assume for a moment that this computer has 1 GB of memory, and each of the four boxes labeled "memory" you see in the figure constitutes 256 MB. Data at physical addresses 0x0 through 0x10000000 are stored in the left-most box. Physical address 0x10000000 through 0x20000000 are stored in the next box, etc.
Now consider the left-most processor in the figure, which I'll call processor 0. Let's say the processor runs a program that stores the variable x at address 0x0. A load of x by processor 0 might take 100 cycles. However, now consider the case where x is stored at address 0x10000000. Now, since this address falls within a remote memory block, a load of x by the same processor, running the same program, might take 250 cycles.
With a NUMA memory architecture, the performance characteristics of an access to an uncached memory address depend on what the address is! (Up until now, you might have thought that performance only dependents on whether the address was cached on not.)
NUMA adds another level of complexity to reasoning about the cost of a memory access. Extra complexity for the programmer is certainly undesirable, however in this case its benefit is that co-locating memory near processors can be a way to provide higher memory performance for programs that are carefully written with NUMA characteristics in mind.
This comment was marked helpful 0 times.
Although it is not memory access, but is it right to draw an analogy to programs running in a distributed environment? For example, routing a map-reduce job from mapper to reducer should take care of where the file is located (same machine / same rack)? It seems that these 2 problems are similar, but at different scale.
This comment was marked helpful 0 times.
@Mayank: Yes, exactly. The costs of communication are important regardless of the environment you might be running in. The point is that some forms of communication might be significantly more expensive than other forms, and being aware of these physical costs might be beneficial when optimizing a program. In my slide, I pointed out that the costs of communication for a memory operation can be dependent on the location of the data in a machine. You gave another nice example where the costs of disk access may be dependent on the data's location in a distributed file system.
This comment was marked helpful 0 times.
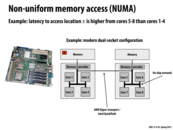


More info from the PSC site:
"The sixteen cores on each blade share 128 Gbytes of local memory. Thus, each core has 8 Gbytes of memory and the total capacity of the machine is 32 Tbytes. This 32 Tbytes is divided into two partitions of 16 Tbyes of hardware-enabled shared coherent memory. Thus, users can run shared memory jobs that ask for as much as 16 Tbytes of memory. Hybrid jobs using MPI and threads and UPC jobs that need the full 32 Tbytes of memory can be accomodated on request."
http://www.psc.edu/index.php/computing-resources/blacklight#hardware
This comment was marked helpful 0 times.
Some interesting stats about the NUMA performance of Blacklight:
Latency to DRAM on the same blade as a processor: ~200 clocks
Latency to DRAM located on another blade: ~1500 clocks
Source: slide 6 of http://staff.psc.edu/blood/XSEDE/Blacklight_PSC.pptx
This comment was marked helpful 0 times.



A primary example of this would be various distributed systems. These can use remote procedure calls (RPC) or other message passing systems for communication. The basic idea of a RPC is to keep the same semantics as a normal procedure call, but behind the scenes run the procedure on some other machine and return the result to the original machine. This allows for a nice interface when programming a distributed system.
This comment was marked helpful 0 times.
Another example of message passing model is the channel mechanism in Golang. The key idea is sharing memory by communication. Threads communicate with each other through message passing via channel. Only one thread has access to the shared value at any given time.
This comment was marked helpful 0 times.
All inter-process communication in Erlang is done via message passing, if I'm not mistaken.
This comment was marked helpful 0 times.


The "challenges" mentioned in the slide above were discussed in lecture. In class we discussed how we might implement message passing systems where all we have is the traditional shared address space form of communication. One way to have message passing work on such systems is to assign each thread, worker, or "process" (in the pi calculus jargon) a mailbox in memory, or some tag to retrieve messages. From this point there are two approaches to take.
If you want asynchronous message passing (so that a data sender does not block while waiting for the receiver to collect data) the sender simply takes a lock and writes to the mailbox queue, and the receiver will simply pull the first message that came in off the queue. There are scalability issues with this approach, as the sender could send arbitrarily many messages before a receiver decides to take a message, which means that the system would basically need to provide an unbounded buffer for this to work perfectly.
The other approach is to have a synchronous message send, where the sending process blocks until the receiver is ready. Then both processes sync up, and the sending process can copy into the receiver's address space. Disadvantages are that messages are not necessarily queued up anymore, but more importantly the sending process cannot do any work while waiting for the receiver. This behooves receivers to keep checking messages more often, since not doing so could block senders indefinitely. However, if you think about it such a message passing system can actually be used as a crude thread barrier: just send a tiny amount of data and make multiple receivers receive it before moving forward in execution.
Example of this from obscure OSes: the rendezvous() system call in Plan 9 implemented a synchronous message passing system. The system call took a tag and a small amount of data. If two processes called rendezvous() with the same tag, they would swap data items. The more you know!
This comment was marked helpful 0 times.


For the first point, consider two processes running in separate address spaces. You could dedicate a shared buffer in memory that could be used for rudimentary message passing (process 1 writes data to the buffer, which process 2 reads from, etc.). Note that this shared buffer would still need a mutex however.
This comment was marked helpful 0 times.

Let's say you had a shared memory program that was being run across multiple machines. Every time a machines writes to shared memory, it updates it's local copy, and then sends a message out to all the other machines. Each of those machines then updates their own local copy.
This comment was marked helpful 0 times.



Note that this implementation of abs doesnt work correctly on MIN_INT.
This comment was marked helpful 0 times.
That would be the case if the array elements were ints, but they are floats. Or did you mean something else?
This comment was marked helpful 0 times.
Nope, I was being dumb. Thanks.
This comment was marked helpful 0 times.

Shouldn't the foreach loop run from i = 0 ... N/2?
This comment was marked helpful 0 times.
No. N/2 is being passed in.
This comment was marked helpful 0 times.

We noted in class that this implementation is better than one implemented in, say, MATLAB. The reason being that if we abstracted how our program would work in MATLAB, we would have it first create some temporary array storing all of our values, and then have to iterate through this temp again to duplicate each value, which means we would've iterated through the array twice.
This comment was marked helpful 0 times.


The program is non-deterministic because different iterations may write to same location. For example, x[n] is bigger than 0 while x[n+1] is less than 0, they will both write to y[n]. Therefore, the value of y[n] depends on the order of these two write instructions.
This comment was marked helpful 0 times.



Again this is the tradeoff when deciding at which level of abstraction to operate. The higher the abstraction the more expressive the code is. This increases programmers' productivity at the cost of losing control over the actual implementation. In the ideal world, code will be perfectly compiled into the optimal implementation, regardless of the language the program is actually written. Nowadays compilers are good but not "that" good yet, however the balance is tipping more towards high abstraction languages (Kesden's 213 assembly programming story). In fact there are a lot of research in creating better high level languages for modern computers. Google High Productivity Language Systems for some interesting readings.
The take home lesson is: use languages closer to implementation to squeeze the last drop from your hardware, and use high abstraction languages to produce complex, maintainable, and readable programs.
This comment was marked helpful 1 times.
I liked what Kayvon had to say about how, with the data parallel programming model, one must "think functionally", despite not programming in a functional way
This comment was marked helpful 0 times.
I think that Google's MapReduce Programming Model is like streaming programming to some extent. The foo is the mapper and the bar is the reducer. Instead of a sophisticated compiler, the MapReduce leverages a sophisticated infrastructure to handle the data stream, failure recovery etc. But the basic thought remains the same. This is also another example of the tradeoff that @Xiao says.
This comment was marked helpful 0 times.
@GG: correct, hence the name "MapReduce" ;-)
Notice that even MapReduce is a very hybrid system. It's functional in terms of mapping a kernel onto a stream of chunks. But the kernel itself is written in an imperative fashion. Thus, the framework applies constraints on the overall structure of the part of the computation that spans multiple machines (where challenges such as parallelism, fault-tolerance, etc. are very hard for an average programmer to deal with efficiently and correctly) but it does not constrain the computation inside the kernel (where its believed to be difficult for a programmer to shoot themselves in the foot, since a kernel is meant to run within a single thread of a single machine).
The design strikes a nice balance and the usefulness of the design is reflected in the popularity of the system.
This comment was marked helpful 0 times.

Not having to write a[i] prevents you from writing a large class of bugs, which is significant.
This comment was marked helpful 1 times.
You could also argue that not having to write 'if' statements saves you from a large class of bugs, but I'd argue that both of those have been shown to be generally worth the dangers they can introduce. :-)
This comment was marked helpful 0 times.

The above-left program computes the absolute value of a collection of numbers, but elements of the input collection are defined in terms of another collection as given below:
tmp_input[i] = input[ indices[i] ]
The i'th element of the input stream tmp_input to the kernel is the indices[i]'th value of the source stream input.
We call this operation a "gather" because the operation gathers contiguous elements from a source stream (here: input) to formulate a new stream (here: tmp_input) to pass to a kernel.
On the right, I show a similar situation that uses a "scatter". The elements of the output stream are scattered to locations of the output stream output.
This comment was marked helpful 0 times.
In this slide, we are introduced to two key concepts in the course: Gather and Scatter.
Gather, which assumes that the requested elements are spread across memory, is an operation that assembles and stores elements contiguously; or, in Kayvon's words, "a parallel load where the indices are not contiguous". As an instruction, this works by taking a vector register of indices (R0), an empty resultant vector register (R1) and a base pointer (mem_base), looking up the elements given by the indices R0 relative to mem_base, and storing these elements contiguously in R1. Currently, Gather does not exist on any CPU on the market, but (as is mentioned in the next slide) will be included in the new AVX instruction set.
Scatter does the opposite, taking a contiguous result and'scattering' its elements throughout memory, presumably in a manner converse to what is seen in Gather.
It's important to note that both of these operations are very memory-intensive. However, these concepts are key in implementing important parallel algorithms such as quicksort and sparse matrix transpose (Source)
Question: is there some kind of interesting tie-in between this stuff and distributed systems? Seems like there ought to be.
This comment was marked helpful 0 times.
Note: "the new AVX instruction set" is AVX2. AVX is already on Sandy Bridge, bulldozer, and later procs. And just to make this explicit: Scatter is not part of AVX2.
Question: Is scatter more difficult to implement than gather in hardware? Is gather more useful to programmers than scatter?
http://en.wikipedia.org/wiki/Advanced_Vector_Extensions#Advanced_Vector_Extensions_2
This comment was marked helpful 1 times.
In general, I think gather is more useful than scatter. I can't dig up numbers to substantiate this, but my understanding is that more loads are generally issued than stores for regular memory access; assuming that's true, I'd assume that gather would see more use than scatter when running SIMD/SPMD workloads.
I don't know of specific implementation issues for scatter vs. gather, but I know that both are quite hard--there's a reason it's taken so long to get even gather on CPUs. In general, having an instruction that can read from 8 completely different locations in memory is quite a change from before, when a single instruction could only access a single memory location. This in turn has all kinds of impact on the entire microarchitecture.
One example is fault handling: what if you are in the middle of a gather, have done a bunch of loads, and then you hit a page fault? You need to be able to resume the gather instruction partway through, after the fault is serviced. This is a bit of trouble.
Another example is the TLB: in the worst case, each of the gather addresses could be unaligned, so that it spans two pages; this means that up to 16 virtual-to-physical address translations have to be done. This presents the TLB with a workload quite different than it had before--now it has to get a bunch of translations done quickly.
In general, you can probably pick any part of the microarchitecture and come up with ways that gather and scatter impact its implementation / violate earlier assumptions in the design. Caches are probably another good place to think about this.
This comment was marked helpful 1 times.

Note that if such instructions existed, the line float value = x[idx]; from our eariler sinx ISPC program could be implemented as a gather.
The line result[idx] = value; is a scatter.
This comment was marked helpful 0 times.
Unfortunately, note that AVX2 only provides gather, not scatter.
This comment was marked helpful 0 times.
Even if both gather and scatter were supported in AVX2, they would still be significantly slower than contiguous blocks of load/store. This is why rearranging large data structures as much as possible to reduce gather and scatters result in noticeable speedups. In fact, the ISPC compile yells at you for using gather and scatters.
This comment was marked helpful 0 times.
Challenge question: Why might an instruction that performs a gather be a more costly instruction than an instruction that simply loads a contiguous block of memory (in the case above: 16 contiguous values from memory)? For the computer architects in the class... what might be the challenges of implementing such an instruction?
This comment was marked helpful 0 times.

Wouldn't a gather be more expensive because it is not a contiguous block of memory? The locations in memory could be much further apart from this, which would make caching the remaining values impossible. For example, if you have a cache line which can hold 16 values, and your data in memory is 17 address apart, you will get no cache hits because you needed to fetch the first value from data. Now, the remaining 15 values are useless to you. Now, not only do you waste time caching data which will be scrapped in the next iteration of the gather, but you also waste more time waiting for data to arrive from main memory as well.
This comment was marked helpful 0 times.




An example of the first point here is solving WSP (or anything else) using OpenMP on each individual machine, and then using MPI within a cluster to communicate between machines. OpenMP is strictly a shared address space model whereas MPI is strictly a message passing model, but they can be used together as a hybrid model.
This comment was marked helpful 0 times.


Question: I used the term "abstraction distance" in this summary without ever defining it in the lecture. What do you think I meant here?
This comment was marked helpful 0 times.
"Abstraction distance" indicates the distance between a logical abstraction and possible implementations. It is low when abstraction is similar to implementation. For example, the abstraction can be the set of all main features that extract from one implementation. Its description is more specific. On the contrary, it is high if abstraction is more general, which can be applied to several/many scenes. For instance, the abstraction can be the common set of main features that extract from several implementations. Using a low "abstraction distance" typically makes an abstraction more detailed but narrow, while using a high one indicates more general but lack of optimization.
This comment was marked helpful 1 times.
ISPC has an excellently written user's guide.
It is highly recommend that you read the following sections:
These sections largely discuss ISPC programming abstractions. The performance guide begins to dig deeper into how the compiler will implement these abstractions on a modern multi-core CPU with SIMD instructions.
This comment was marked helpful 0 times.