Memory access on lecture 3, slide 26 was more cost uniform because the memory locations were about the same distance from every processor. As we can see on this slide, the memory locations are not the same distance from each processor leading to differences in cost of memory access.
This comment was marked helpful 0 times.
Amanda
Just to rephrase; If I understand correctly, a given processor will allocate memory at closer addresses?
This comment was marked helpful 0 times.
kayvonf
Clarity alert! Processors don't allocate memory. Processors just execute instructions, some of which load and store from memory. Programs however, can allocate memory. As you learned in 15-213, the OS decides how regions of a processes virtual address space (allocated by a program) map to physical memory locations in the machine. It would be advisable for an operating system to set up first memory mappings so memory is near to the processor that is most likely to access it.
Let me explain the slide in more detail: This slide shows a parallel computer where main system memory is not one big monolithic unit, but is instead partitioned into four physical memories. Each memory is located close to a processor. Each processor can access its "nearby" memory with lower latency (and potentially higher bandwidth) than the memories that are farther way.
Let's assume for a moment that this computer has 1 GB of memory, and each of the four boxes labeled "memory" you see in the figure constitutes 256 MB. Data at physical addresses 0x0 through 0x10000000 are stored in the left-most box. Physical address 0x10000000 through 0x20000000 are stored in the next box, etc.
Now consider the left-most processor in the figure, which I'll call processor 0. Let's say the processor runs a program that stores the variable x at address 0x0. A load of x by processor 0 might take 100 cycles. However, now consider the case where x is stored at address 0x10000000. Now, since this address falls within a remote memory block, a load of x by the same processor, running the same program, might take 250 cycles.
With a NUMA memory architecture, the performance characteristics of an access to an uncached memory address depend on what the address is! (Up until now, you might have thought that performance only dependents on whether the address was cached on not.)
NUMA adds another level of complexity to reasoning about the cost of a memory access. Extra complexity for the programmer is certainly undesirable, however in this case its benefit is that co-locating memory near processors can be a way to provide higher memory performance for programs that are carefully written with NUMA characteristics in mind.
This comment was marked helpful 0 times.
Mayank
Although it is not memory access, but is it right to draw an analogy to programs running in a distributed environment? For example, routing a map-reduce job from mapper to reducer should take care of where the file is located (same machine / same rack)? It seems that these 2 problems are similar, but at different scale.
This comment was marked helpful 0 times.
kayvonf
@Mayank: Yes, exactly. The costs of communication are important regardless of the environment you might be running in. The point is that some forms of communication might be significantly more expensive than other forms, and being aware of these physical costs might be beneficial when optimizing a program. In my slide, I pointed out that the costs of communication for a memory operation can be dependent on the location of the data in a machine. You gave another nice example where the costs of disk access may be dependent on the data's location in a distributed file system.
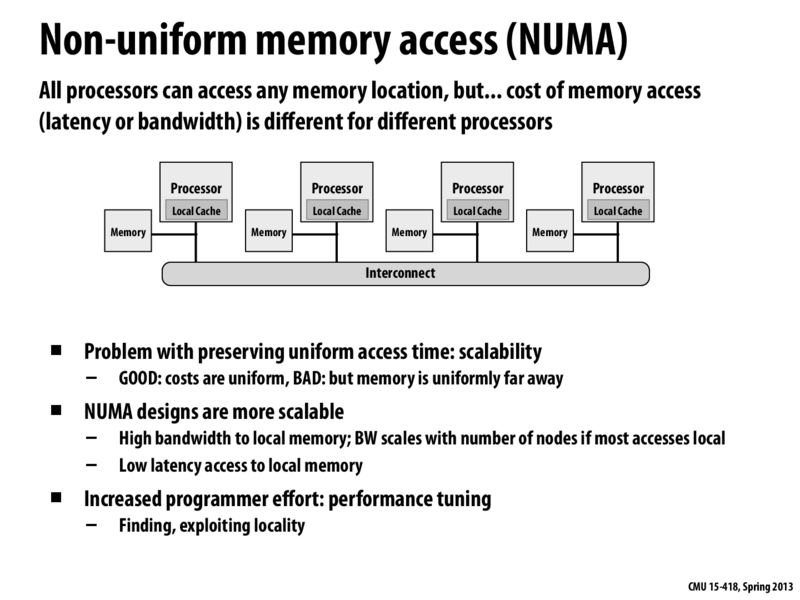
Memory access on lecture 3, slide 26 was more cost uniform because the memory locations were about the same distance from every processor. As we can see on this slide, the memory locations are not the same distance from each processor leading to differences in cost of memory access.
This comment was marked helpful 0 times.
Just to rephrase; If I understand correctly, a given processor will allocate memory at closer addresses?
This comment was marked helpful 0 times.
Clarity alert! Processors don't allocate memory. Processors just execute instructions, some of which load and store from memory. Programs however, can allocate memory. As you learned in 15-213, the OS decides how regions of a processes virtual address space (allocated by a program) map to physical memory locations in the machine. It would be advisable for an operating system to set up first memory mappings so memory is near to the processor that is most likely to access it.
Let me explain the slide in more detail: This slide shows a parallel computer where main system memory is not one big monolithic unit, but is instead partitioned into four physical memories. Each memory is located close to a processor. Each processor can access its "nearby" memory with lower latency (and potentially higher bandwidth) than the memories that are farther way.
Let's assume for a moment that this computer has 1 GB of memory, and each of the four boxes labeled "memory" you see in the figure constitutes 256 MB. Data at physical addresses 0x0 through 0x10000000 are stored in the left-most box. Physical address 0x10000000 through 0x20000000 are stored in the next box, etc.
Now consider the left-most processor in the figure, which I'll call processor 0. Let's say the processor runs a program that stores the variable
xat address 0x0. A load ofxby processor 0 might take 100 cycles. However, now consider the case wherexis stored at address 0x10000000. Now, since this address falls within a remote memory block, a load ofxby the same processor, running the same program, might take 250 cycles.With a NUMA memory architecture, the performance characteristics of an access to an uncached memory address depend on what the address is! (Up until now, you might have thought that performance only dependents on whether the address was cached on not.)
NUMA adds another level of complexity to reasoning about the cost of a memory access. Extra complexity for the programmer is certainly undesirable, however in this case its benefit is that co-locating memory near processors can be a way to provide higher memory performance for programs that are carefully written with NUMA characteristics in mind.
This comment was marked helpful 0 times.
Although it is not memory access, but is it right to draw an analogy to programs running in a distributed environment? For example, routing a map-reduce job from mapper to reducer should take care of where the file is located (same machine / same rack)? It seems that these 2 problems are similar, but at different scale.
This comment was marked helpful 0 times.
@Mayank: Yes, exactly. The costs of communication are important regardless of the environment you might be running in. The point is that some forms of communication might be significantly more expensive than other forms, and being aware of these physical costs might be beneficial when optimizing a program. In my slide, I pointed out that the costs of communication for a memory operation can be dependent on the location of the data in a machine. You gave another nice example where the costs of disk access may be dependent on the data's location in a distributed file system.
This comment was marked helpful 0 times.