If we duplicate tags and give one tag set to the processor side and the other tag set to the bus side, we can reduce the amount the traffic from both sides interfere with each other. This will prevent scenarios such as a processor receiving a ton of read/write requests making it unable to quickly respond when a load request occurs. In the new duplicated version, the processor will be able to respond to the load request regardless of how many bus requests it receives.
This comment was marked helpful 0 times.
Amanda
Can someone describe the notion of non-interferring, parallel "processor-side" and "bus-side" lookups in more detail? I understand why it works: by duplicating entries, the processor is not held up by consistent lookup requests from the bus and can proceed with loads/stores/etc. I'm not sure what this looks like from an implementation perspective. Are we thinking multiple processors to one cache, or are we exposing something to the bus that we hadn't before, leaving the processor free to do other things?
This comment was marked helpful 0 times.
kayvonf
@Amanda, the answer who make more sense if we had a lecture describing how hardware works (but I'll leave that to ECE classes). One simple way to think of this is that the chip has storage for the tags. By duplicating that storage and the logic necessary to read its contents, a design might allow both the processor and the cache's snooping logic to perform their operations on the tag data in parallel. Otherwise, you can imagine one of these clients might need to wait for the other due to contention in access to the tag data. Details of cache design in a multi-core setting would be the subject of a graduate architecture class.
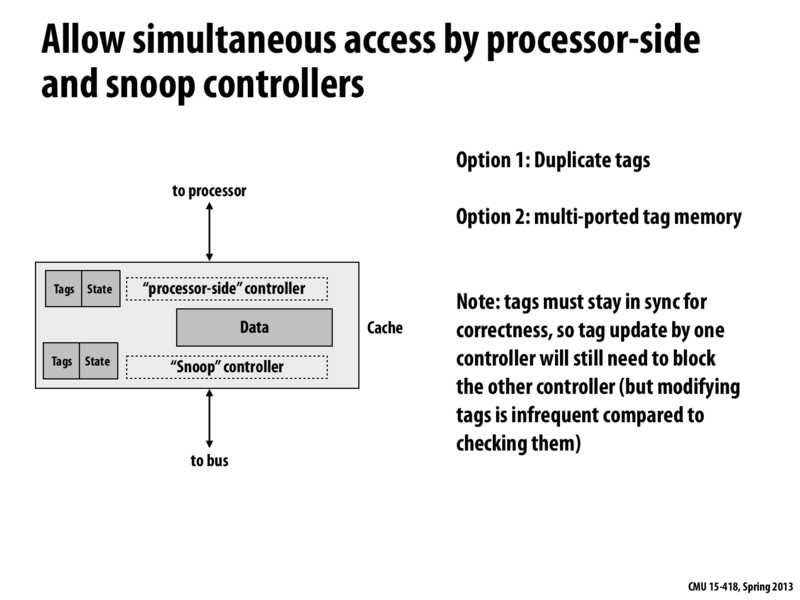
If we duplicate tags and give one tag set to the processor side and the other tag set to the bus side, we can reduce the amount the traffic from both sides interfere with each other. This will prevent scenarios such as a processor receiving a ton of read/write requests making it unable to quickly respond when a load request occurs. In the new duplicated version, the processor will be able to respond to the load request regardless of how many bus requests it receives.
This comment was marked helpful 0 times.
Can someone describe the notion of non-interferring, parallel "processor-side" and "bus-side" lookups in more detail? I understand why it works: by duplicating entries, the processor is not held up by consistent lookup requests from the bus and can proceed with loads/stores/etc. I'm not sure what this looks like from an implementation perspective. Are we thinking multiple processors to one cache, or are we exposing something to the bus that we hadn't before, leaving the processor free to do other things?
This comment was marked helpful 0 times.
@Amanda, the answer who make more sense if we had a lecture describing how hardware works (but I'll leave that to ECE classes). One simple way to think of this is that the chip has storage for the tags. By duplicating that storage and the logic necessary to read its contents, a design might allow both the processor and the cache's snooping logic to perform their operations on the tag data in parallel. Otherwise, you can imagine one of these clients might need to wait for the other due to contention in access to the tag data. Details of cache design in a multi-core setting would be the subject of a graduate architecture class.
This comment was marked helpful 0 times.