








In this example, the car is taking up part of the intersection (shared resource A) and the bus is taking up another part of the intersection (shared resource B). In order to get through the light, both parts of the intersection are needed, you need parts A and B of the intersection for your car to pass. Now the bus and car are deadlocked, the only way out is for one of them to back up.
This comment was marked helpful 3 times.


Here, no one would give out the resource, otherwise it would be eaten.
It is an interesting example of deadlock.
This comment was marked helpful 2 times.
Is this correct really? In the first picture, if the stork gives out the resource, I don't think it will get eaten :/
This comment was marked helpful 0 times.

The examples describe the necessary condition when occur a deadlock situation. 1. Mutual Exclusion?At least one resource are both non-sharable. 2. Resource Holding: In this case, each one hold one resource and wait for other to give out. 3. Circular Wait: There exists a circular relationship between two actions.
This comment was marked helpful 0 times.


Shouldn't the MPI example be using MPI_Ssend? MPI_Send does a send in standard mode, meaning that
In this [standard] mode, it is up to MPI to decide whether outgoing messages will be buffered. MPI may buffer outgoing messages. In such a case, the send call may complete before a matching receive is invoked.
MPI_Ssend operates in synchronous mode, meaning that
However, the [synchronous] send will complete successfully only if a matching receive is posted, and the receive operation has started to receive the message sent by the synchronous send.
This comment was marked helpful 0 times.

In example 1 there is deadlock as neither queue has a place to store its response. Queue A has produced work for B's queue, but B will not have work in its queue until it gives more work to A. Neither queue can make progress as a result and will continue to wait.
This comment was marked helpful 0 times.

Example 2 is a classic Dining philosophers problem: all the processors are waiting for one of the other processor's resource while holding a resource that is being waited by another processor. More explanation can be found here: Dining philosophers problem
This comment was marked helpful 0 times.
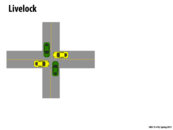
For each car, strategy is
while (have not crossed) {
if (full)
take a step back
else
go ahead
}
So neither car can go through the crossroad here.
This case is called livelock.
This comment was marked helpful 0 times.
I think you want go ahead inside of the while block.
This comment was marked helpful 0 times.
Livelock is the same as deadlock, in the sense that nothing useful is getting done. However, in livelock, work is being done, but in deadlock, nothing is happening.
This comment was marked helpful 0 times.

@pd43 I think saying that "work is being done" is misleading: it's more accurate to say that in a deadlock, all agents are blocked on a resource (idling), whereas in a livelock, at least one agent is performing an action (usually intended to avoid deadlock).
This comment was marked helpful 0 times.

Livelock occurs less often because it requires both party to take the "back-off" actions simultaneously, which is unlikely due to mechanisms like pipelining and write-back buffering. But in those cases it may introduce inconsistency.
This comment was marked helpful 0 times.

Since there is always at least one agent performing an action, livelock is a lot harder to detect. It appears as though your system is doing useful work, however it continually undoes all the work previously performed.
Is livelock really that much less common? I feel like any situation that results in deadlock could easily be translated into a situation of livelock. Instead of sitting and waiting for a resource, each agent "reverses".
This comment was marked helpful 0 times.

Livelock can also occur with Test&Test;&Set; and exponential backoff when two processors 1 and 2 acquire locks on memory addresses A and B respectively; however, these processors need both locks to make any progress. As a result, both processors will attempt to acquire these locks in exponentially longer times but will fail to do so. Thus, both processors do work of acquiring both locks but neither will acquire them; thus, resulting in livelock.
This comment was marked helpful 0 times.
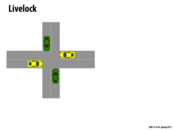
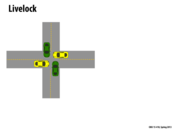

Although each of the cars are moving, none of them are making any progress because the road remains blocked for everyone. This is a live lock situation because something is constantly happening, but none of the "threads" can make any progress. If we think of each car as a thread, we can relate this example to those found in code.
This comment was marked helpful 0 times.

A common example occurs when two people are walking towards each other. They both notice that they will collide if they continue walking straight so they move left or right at the same time causing the same issue in a different location. Both parties have changed their position in the hopes of making progress, but progress is not made as they still cannot pass each other.
This comment was marked helpful 0 times.

Unlike deadlock, there is some work being done in livelock, but not necessarily useful work. With the car example, in a deadlock situation, none of the cars are moving and instead they're just waiting for another car to move so they can keep moving. In the livelock situation, each car does work by backing up to try to let others go by and then moving forward again, but ultimately like the deadlock situation, none of the cars actually get past the intersection.
This comment was marked helpful 0 times.

It seems like livelock results because the parties in a system do not communicate with each other. Each party is individually attempting to fix what would be a deadlock situation by backing off. Because there's a lack of coordination (parties are coordinating the back-off with the other parties), they get into a situation where they each back-off and reattempt at the same time leading to the livelock situation.
This comment was marked helpful 0 times.

Each car could wait for a random amount of time, then live lock can be solved without communication.
This comment was marked helpful 0 times.

Here is another example of livelock that occurs in the physical world:
This comment was marked helpful 0 times.
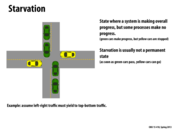
Sometimes we can reduce starvation by better scheduling the order.
This comment was marked helpful 0 times.

To remove starvation, you really need policies that enforce fairness. Like a mutex guaranteeing FIFO order when multiple clients try to acquire it (one unlucky guy might actually wait forever spinning on a lock). Or avoiding cases of priority inversion.
This comment was marked helpful 0 times.

Although starvation, unlike deadlock, does not cause any incorrectness in the implementation it could appear as a deadlock because some systems remain useless from some of the tasks. As @kfc9001 mentions, changing and maintaining priorities can be a simple way to solve starvation.
This comment was marked helpful 0 times.

One extreme example was the reboot of Mars Pathfinder robot. It experienced a priority inversion problem after landing. Although priority inversion is not exactly the same as starvation, they are very similar in that the low priority processes do not get the chance to run for enough time. http://research.microsoft.com/en-us/um/people/mbj/mars_pathfinder/mars_pathfinder.html
This comment was marked helpful 0 times.


This slide explains that we are going to study a basic implementation of the snooping protocol.
This comment was marked helpful 7 times.
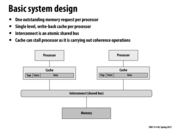
For anyone who is not entirely clear on what a bus is in the system, it is essentially a set of wires that the processors can communicate through. The bus is intrinsically broadcasting among the processors, which means that every processor that is connected to the bus can see the signals that are sent on it. However, two processors cannot communicate through it at the same time.
This comment was marked helpful 2 times.


The bus is essentially two buses, address and data. Note that the address line is thinner than the data line to signify lower data transfer. (For instance, 8 byte addresses on address bus, 64 byte cache lines on data bus.)
This comment was marked helpful 0 times.

Question: In class, Kayvon said that for a read operation, no bus transactions are allowed once the read request is sent to the memory controller until the processor (cache controller) has received the data. Can additional read requests be passed along the address bus while the memory controller is serving a different read request on the data bus? Or does that fall under the category of "non-atomic bus"?
edit: question answered in lecture -- this slide refers to an atomic bus, where there can be only one outstanding bus transaction at a time. Slide 20 in the next lecture refers to a split-transaction bus which more efficiently utilizes the bus.
This comment was marked helpful 0 times.

Everyone should think very carefully about why BusWr above (the same as Flush as in slide 25 of the cache coherence lecture) is different from BusRdX. A flush is the operation of flushing a dirty line out to memory when another processor needs access to the latest copy of the line. The line is dirty because this line had been written to at some point in the past.
BusRdX is an operation where a processor declares it will be writing to the value, and requires systemwide exclusive access. The completion of a BusRdX is considered to be the point at which the write commits systemwide (write serialization). A flush of the line's contents can happen much later, and it only needs to happen if the dirty line is evicted or is required by another processor in the system.
This comment was marked helpful 1 times.

So in other words,
A BusRdX is sent when a processor wants to write to some value in the future, hence demanding exclusive access,
while a BusWr is sent when a processor evicts a dirty cache line or receives a request for that line from another processor.
This comment was marked helpful 0 times.

If a processor observes a broadcast like a bus read/write, it has to look in its cache to see if it cached the given address. If it did, it may have to invalidate the address.
In a poorly designed multi-processor system, we may have a problem if too many processors broadcast reads and writes requests. For every broadcast, every processor will have to check to see if the given address is in it's cache. While a processor checks if it cached the address, it can't respond to other requests such as a load request. So if there are too many read/write requests, there may be a significant delay in responding to other requests such as loads.
This comment was marked helpful 0 times.
Some examples of what @sjoyner is saying:
- The processor needs to look up data to see if it exists in the tags
- The processors marks a tag as dirty
- The bus invalidates something in the cache, which leads to a
BusRdXto that address x
This comment was marked helpful 0 times.

This relates back to the slide about the problem of starvation if we're not careful with our design. If the controller prioritizes requests from the bus, the cache could be constantly busy looking up tags due to coherence traffic, preventing any potential processor request from issuing a load, subsequently killing ('starving') the performance of the local processor.
Conversely, if the loads and stores of the local processor are prioritized, then the cache can't get any of its data to perform tag lookups and respond to other processors, holding up the entire system because it's constantly serving the requests of one processor.
This comment was marked helpful 1 times.
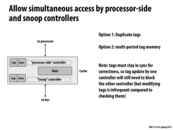
If we duplicate tags and give one tag set to the processor side and the other tag set to the bus side, we can reduce the amount the traffic from both sides interfere with each other. This will prevent scenarios such as a processor receiving a ton of read/write requests making it unable to quickly respond when a load request occurs. In the new duplicated version, the processor will be able to respond to the load request regardless of how many bus requests it receives.
This comment was marked helpful 0 times.

Can someone describe the notion of non-interferring, parallel "processor-side" and "bus-side" lookups in more detail? I understand why it works: by duplicating entries, the processor is not held up by consistent lookup requests from the bus and can proceed with loads/stores/etc. I'm not sure what this looks like from an implementation perspective. Are we thinking multiple processors to one cache, or are we exposing something to the bus that we hadn't before, leaving the processor free to do other things?
This comment was marked helpful 0 times.
@Amanda, the answer who make more sense if we had a lecture describing how hardware works (but I'll leave that to ECE classes). One simple way to think of this is that the chip has storage for the tags. By duplicating that storage and the logic necessary to read its contents, a design might allow both the processor and the cache's snooping logic to perform their operations on the tag data in parallel. Otherwise, you can imagine one of these clients might need to wait for the other due to contention in access to the tag data. Details of cache design in a multi-core setting would be the subject of a graduate architecture class.
This comment was marked helpful 0 times.

One temporary solution proposed during lecture was that we can have a fixed number of cycles set for a response and load while in the E state if we don't hear anything. However, if the processor is busy then this will lead to even more complexity.
This comment was marked helpful 0 times.

Snoop-valid may be better called snoop-invalid. Every processor starts with it on (set to 1), and once every processor turns it off, then the final "or" value will be 0 as stated in the slide.
This comment was marked helpful 0 times.
Every line is just a wire, so it just ORs the signals returned by each processor to get the result. Shared line: If a processor has an address in it's cache, it signals the other processors on this line. Dirty line: Processor signals that it has the address in the dirty state. Snoop-valid line: Processor signals that it is done. Another idea was to just wait a given period of time to make sure every processor has enough time to respond. However if all processors finish before time is up, it is better if we return right away than wait for the timer. The snoop-valid line makes this easy since we just wait until the line is set to 0.
This comment was marked helpful 1 times.

Could we not also make this a snoop-valid line by just and'ing all the processor responses. The only way that line would switch to valid was if all the processors are done and send a "on" signal. If any of the processors are not done, then the entire valid line will be off.
Could architects chose either or is there a better choice of the two. Snoop valid or Snoop invalid?
This comment was marked helpful 0 times.

Both ANDing and ORing solutions are logically equivalent. However, implementation wise they could be different. For example, one catch might be the behavior under faulty situation. If a open circuit occurs from one CPU, is the line connecting to that CPU more likely to be on or off? Would you prefer the system to make progress under such situation or deadlock? Another problem you might consider is which logic gate takes the larger number of transistors.
This comment was marked helpful 0 times.


Evicting a cacheline requires two bus transactions: flushing dirty data back to memory, and reading the new data into the cache. A write-back buffer is based on the notion that, while both operations are necessary, only the read is time-critical: thus, by eliminating its dependency on the write, we can hide latency and make the operation more efficient. In terms of implementation, this means storing the dirty data in a temp buffer (no bus transaction) before using the bus to load the new data; then, when the processor is idle, issuing a write to memory.
This comment was marked helpful 2 times.
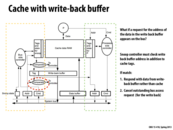
If the request will modify the cache line, you can skip the write-back since the cache line is now in another cache with the dirty bit set, still waiting to be written to memory.
This comment was marked helpful 0 times.
All green staff here deal with logic to serve request from processors.
All yellow staff here deal with logic to serve request from the bus.
This comment was marked helpful 0 times.

Question I have a question with terminology here. What does 'outstanding bus request' mean?
This comment was marked helpful 0 times.

@danielk2: I think that request is the write back request for the dirty line.
When the processor wants to flush the dirty line, it issues a request to write back. Because of the write back buffer, the processor can continue without the request been granted to process. Instead, the dirty line comes into the buffer. But the request is still outstanding. When the request is granted to process, the write back buffer will flush the dirty line to the bus.
This comment was marked helpful 0 times.
@lazyplus is correct.
This comment was marked helpful 0 times.
One interesting thing I read about is that the writes from processor to write-back buffer is often less than the writes from write-back buffer to memory. This is because if a dirty line sit in write-back buffer when another processor request a write to the very same line, we can forward this line from the write-back buffer to the new processor, and remove it from the write-back buffer. The responsibility of flushing the dirty line back is now transferred to the new processor.
This comment was marked helpful 0 times.

My guess is
If processor A can get dirty-lines from another processor B's write back buffer, processor B has to invalidate that cache line (or at least take dirty bit off). If two processors have dirty bit on on same cache line, there could be coherence issues and if the line is not invalidated, processor B is reading on a line that is not reflected to all processors.
This comment was marked helpful 0 times.


Here is the deadlock that is occurring:
Processor 1 has the shared resource of the bus.
Processor 2 needs the bus, so it idles waiting for the bus.
However, processor 1 needs the 'resource' of processor 2 to invalidate cache line A.
Thus, deadlock.
This comment was marked helpful 0 times.

Suppose processor P1 and P2 suppose to write to the same cache line A simultaneously, and they are both in S state. Both processors want to write more or less at the same time. What's going to happen?
Suppose you allow P1 to go first then P1 "wins" bus access and sends BusUpg. What about P2? P2 is waiting for bus access and P2 must invaliate its line A when it receives BusUpg message. Now P2 does not have the cache line A since it is invalidated. Then P2 must change its pending BusUpg request to a BusRdx.
A cache must be able to handle requests while waiting to aquire bus AND be able to modify its own outstanding requests, otherwise there might be a deadlock. Here P1 has the bus resource and P2 needs the bus resource. P1 needs the resource in P2 to invaliate its cache line, but P2 has made a mistake and has changed its request state, so we have a situation that both processors are half-way through some transactions, and they need what the other processor has in order to make progress. It's just like an intersection example. This is an example of deadlock since things are not atomic.
This comment was marked helpful 2 times.


Why does a write-back buffer not cause this problem?
I think that a write-back buffer don't enable processor to run arbitrarily, but it can help accelerate the execution. First, it continues the operations of processor on other memory locations. Secondly, it can help to recover the contention, if any on the cache line, and resume the correct execution.
Is that right?
This comment was marked helpful 0 times.

Why does it violate coherence?
Coherence requires write serializability (all processors should observe a global order of writes for variable X). Assume P1 writes to X (updates cache) but does not issue BusRdX. Another processor P2 might also write to X (since, it does not know anything about P1's write yet). In this case P1 sees its own write before P2's write and P2 sees its own write before P1's write, thus violating write serializability.
Why does write buffer does not violate coherency?
Note that in case of write buffer, we still have the requirement that any processor wanting to write to value X should shout out BusRdX.
Lets assume that P1 has X in its write buffer.Slide 24 point out that cache controller checks both the cache and the write buffer when it snoops a BusRdX for X. Thus, when P2 wants to write, it shouts out BusRdX. P1 snoops this and realizes that it has the value in write buffer. It sends this value to P2 and cancels its request to write back (also deletes/invalidates the value X from write buffer). This ensures that the value in any processor's write buffer is visible to all other processors. Also, this would also ensure that only one valid copy of X is present across all the write buffers (the processor who was the last to send BusRdX).
This comment was marked helpful 3 times.

This is similar to the example race condition discussed before two slides ago. The deadlock happens because P1 cannot flush its cache line B, because while P1 is waiting for bus to issue BusRdX on cache line, it cannot process BusRd for B. There will be progress only when the bus is granted to P1 after it handles BusRd for B which isn't happening in this example.
This comment was marked helpful 0 times.

In this example, P1 and P2 are always busy. But in fact, there are no progress. Neither processor finishes writing.
This comment was marked helpful 0 times.

On slide 22, two options are given for when snoop results should be reported. By adding requirements, such as completing a write before releasing exclusive ownership, waiting a fixed number of clocks becomes less feasible. This is because time will have to be added to allow a processor to make a write before responding.
This comment was marked helpful 0 times.


Priority-based settings can also cause starvation to occur (though it could be somewhat unlikely). Consider the case where each processor has different priority. If one processor with the highest priority continually issues reads which are not in its cache, its possible for all other, lower priority processors, to never receive bus access.Though this might be a case where the developer has a program which does not utilize the cache effectively, it could also mean that one processor is doing more memory intensive applications.
This comment was marked helpful 0 times.
One classic way to solve @tpassaro's problem is to bump up everyone's priority if they have been in line for a while. Then everyone will (eventually) get a chance to run, even if it's not entirely fair to all parties.
This comment was marked helpful 0 times.

exponential back-off can also cause starvation. Suppose P0 and p1 are contending for some resources, and p0 loses and backs off for some time. During this time, p2,p3..pi comes in and does their work on the resource and leaves. Therefore, the back-off scheme has bias on new comers, which continuously causes starvation on p0.
This comment was marked helpful 0 times.


A simple example of deadlock with threads can be the following situation, where we have 2 threads running:
Thread 1 takes lock on mutex for resource B
Thread 2 takes lock on mutex for resource A
Thread 1 tries to take lock on resource A, but Thread 2 has it
Thread 2 tries to take lock on resource B, but Thread 1 has it
At this point, thread 1 and 2 are deadlocked.Since neither can grab the locks they need, they will be descheduled by the kernel until one or the other gives up a mutex, which they cannot. Neither thread makes any progress
This comment was marked helpful 0 times.
The necessary conditions for deadlock are: 1. At least one shared resource can only be used by one process at one time. 2. Hold and wait. 3. No Preemption. 4. Circular Wait. (Can be a circular among N processors, N > 1)
This comment was marked helpful 0 times.
And as a result, if we are able to guarantee that one of the conditions must not happen, we can be sure that our code does not have a deadlock.
This comment was marked helpful 0 times.