Here in Balanced Tree the overhead of fine locks is more significant when there are few processors. I guess it is because in Hash-Table the lock of the buckets are also an array that might be in the same cache line therefore we do not need to read from memory every time. However In balanced tree the location of the locks are random in the memory therefore we need to read from memory almost each time.
This comment was marked helpful 0 times.
kayvonf
@monster. I have not read the paper these results are from in detail, however I suspect the poor performance of the fine-grained locking solution for low processor count is a reflection of the complexity of a fine-grained locking solution in a balanced tree. The implementation needs to take a number of locks (think: hand-over-hand locking) to perform each operation, and under low contention (which may be the case with low processor count) the overhead of all those locks outweighs the drawbacks of serialization caused by using single global lock.
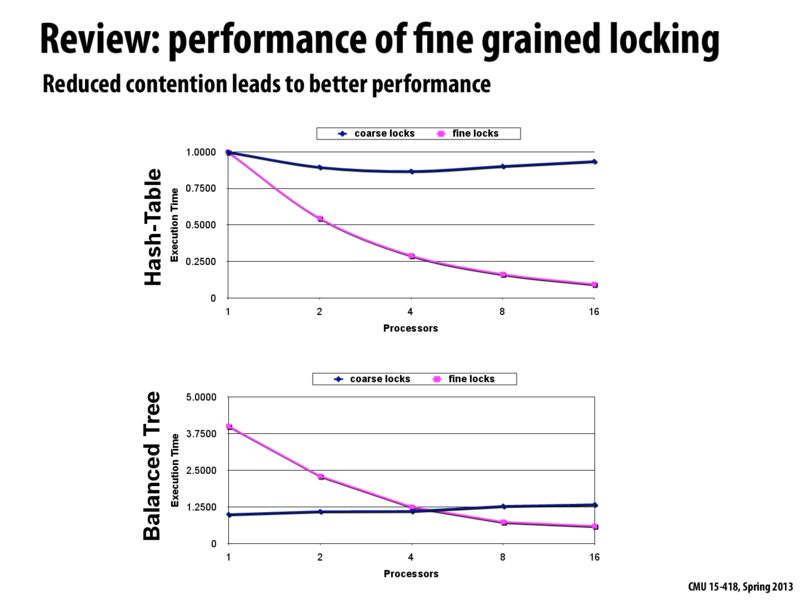
Here in Balanced Tree the overhead of fine locks is more significant when there are few processors. I guess it is because in Hash-Table the lock of the buckets are also an array that might be in the same cache line therefore we do not need to read from memory every time. However In balanced tree the location of the locks are random in the memory therefore we need to read from memory almost each time.
This comment was marked helpful 0 times.
@monster. I have not read the paper these results are from in detail, however I suspect the poor performance of the fine-grained locking solution for low processor count is a reflection of the complexity of a fine-grained locking solution in a balanced tree. The implementation needs to take a number of locks (think: hand-over-hand locking) to perform each operation, and under low contention (which may be the case with low processor count) the overhead of all those locks outweighs the drawbacks of serialization caused by using single global lock.
This comment was marked helpful 0 times.