








Transactions are just like database queries. In fact, the bank account example is the canonical example in most introductions to database transactions. We want to make sure that it appears that the transactions are happening in the exact order specified. This is the abstraction, whereas the implementation may be vastly different. When performing writes, a batch of transactions will change memory state, but this change is only final if ALL transactions are successfully completed. If one or more fails, they all abort and state is returned to what it was before any transaction was made.
This comment was marked helpful 0 times.

Here, does isolation actually means no other transactions can observe writes before commit? If there is a program in another processor spin checking that specific memory address, it should see the written result before the transaction is committed.
This comment was marked helpful 0 times.

No one should see the change of the write before commit since everyone has to commit at the same time.
This comment was marked helpful 0 times.

Just to add, transactional memory is effective when either the program structure is too complex for the programer to implement fine-grained locking or there is not much conflict so that there isn't much rolling back.
This comment was marked helpful 0 times.



This example is not thread safe. In one possible race condition, it is possible for thread 1 to call get on an object, and shortly after thread 2 calls delete on the same object, but the get for thread 1 returns null because the delete was executed before the get by the system.
This comment was marked helpful 0 times.




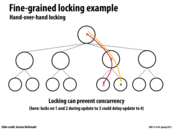
Here in Balanced Tree the overhead of fine locks is more significant when there are few processors. I guess it is because in Hash-Table the lock of the buckets are also an array that might be in the same cache line therefore we do not need to read from memory every time. However In balanced tree the location of the locks are random in the memory therefore we need to read from memory almost each time.
This comment was marked helpful 0 times.

@monster. I have not read the paper these results are from in detail, however I suspect the poor performance of the fine-grained locking solution for low processor count is a reflection of the complexity of a fine-grained locking solution in a balanced tree. The implementation needs to take a number of locks (think: hand-over-hand locking) to perform each operation, and under low contention (which may be the case with low processor count) the overhead of all those locks outweighs the drawbacks of serialization caused by using single global lock.
This comment was marked helpful 0 times.

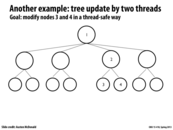

Since we are not modifying nodes 1 and 2, we do not need to acquire locks on them. Only 3 and 4 require locks as they will be updated.
This comment was marked helpful 0 times.
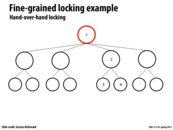
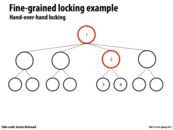
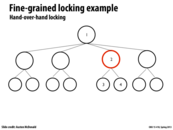
When we acquire the lock to node 2, we can unlock the lock on parent node 1, because at this point, it is safe to assume that any future operations will not modify node 1 (because we intend to modify node 3 or 4, which only potentially affects their parents).
This comment was marked helpful 0 times.
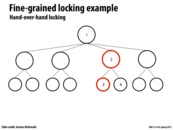
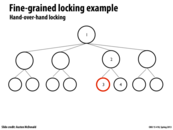

You could avoid some contention by making the locks even finer-grained in this example. Instead of locking an entire node, you can only lock specific parts of each node that will be changed. In this example, only lock the "left subtree" field of node 2 for the red path and only lock the "right subtree" field of node 2 for the yellow path.
This comment was marked helpful 0 times.

Isn't locking the parent node necessary though? In order to lock the child node, you have to have access to the parent data structure. Therefore the parent node must be locked so that you can safely lock the child and move on.
This comment was marked helpful 0 times.
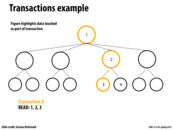
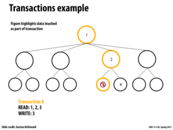
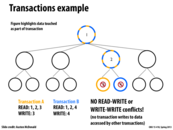
In this example, we can write to both 3 and 4 since 1 and 2 were simply read operations. This ensures atomicity without the need for a lock at each of the nodes. If we had written to 2, however, a write to 4 would not be able to proceed until after that write completed. This will scale well as long as transactions occur mostly at the leaves of the tree.
This comment was marked helpful 0 times.
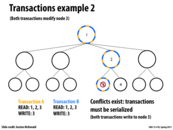


TCC stands for Transactional Coherency and Consistency, and it is a hardware-based transactional memory system.
This comment was marked helpful 0 times.

Unlike hash maps, using fine grain locks for balanced trees can have too much overhead.
This comment was marked helpful 0 times.

In the case of commit failed, program needs a way to rewind the change before it can serialize all operations.
This comment was marked helpful 0 times.


Instead of always locking based on the order of A and B, you can instead compare their memory addresses and always lock the lower memory address first to avoid this specific problem.
This comment was marked helpful 1 times.




Here mentions many advantages of TM, and it seems like TM is a life saver for us programmers. But it should be clear that TM is not suitable in cases that if the execution of a block is computational intensive and is tightly contended, TM is not supposed to use, because it would make other threads constantly discard what they have done and re-start, which wastes lots of work.
This comment was marked helpful 0 times.

transfor allows the iterations of the loop to be executed in parallel as unordered transactions, and any memory dependencies are handled by the system.
This comment was marked helpful 0 times.



This code implements a basic barrier.
Could we replace 'synchronized' with 'atomic'? No. Both threads are reading and writing a common variable. Thus it is impossible to place them within at atomic primitive.
This comment was marked helpful 0 times.
@Avesh: since both threads read/write to same variable, what would happen in a transactional memory implementation? Why isn't the result a barrier?
This comment was marked helpful 0 times.
Suppose Thread 1 makes it into the atomic block first. Since the block is atomic, Thread 1 must either execute the entire block or abort all changes that occur in the block. So Thread 1 will set flagA to true, and then wait for flagB to be set to true. However flagB will never be set to true as Thread 2's code is also in an atomic block, which it cannot execute until Thread 1 is done. The reason they cannot both execute their code at the same time is they are both reading and writing to the same variables, so we must serialize their access to the variables. So this will result in a live lock as Thread 1 will keep looping and checking if flagB is set to true.
This comment was marked helpful 0 times.

Question: What happens if a variable is being updated inside an atomic block in one thread but updated / accessed by another thread which is not in an atomic block? For example, if in the above code, there is no atomic block in thread 2. Will it still restrict thread 2 to modify the variable if thread A is inside the atomic block already?
This comment was marked helpful 0 times.
@Mayank: The answer to your question is no. In your proposed situation, (no atomic used in thread 2) thread 2 would access and update the shared data without any restrictions. This would mean that while thread 1 is in the atomic region (and even if thread 1's modifications were made visible to other threads in a transactional way), contents of the memory could change out from under thread 1 while it was executing the logic of its transaction.
This comment was marked helpful 0 times.

What the programmer intends in this code is for B to store the A->field. However, by splitting up the sequence into two atomic blocks in Thread 1, the system may decide to interleave the atomic blocks, causing ptr to be set to null, causing a null derefence when trying to set B in thread 1.
This comment was marked helpful 0 times.

Locking scheme for four CPUs is often not scalable to 64 CPUS: For example, old Linux kernel was not scalable for 48 CPUs. The reasons are basically due to the lock related implementation, such as mount table read bottleneck in high contention using spin_lock, object reference counting spin check. More details in OSDI10's paper.
This comment was marked helpful 0 times.




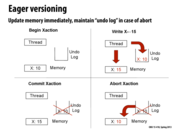

Question: Why does it need to keep undo log for each step of the same memory location instead of just keeping the original value?
This comment was marked helpful 0 times.
@TeBoring. Your suggestion is a nice potential optimization.
This comment was marked helpful 0 times.

@TeBoring: I think it depends on whether you are undoing the whole transaction (in this case your suggestion should work) or undoing the transactions partially when you see a conflict.
This comment was marked helpful 0 times.
Eager versioning is preferred when we expect fewer conflicts since it has faster commits than aborts.
This comment was marked helpful 0 times.

This is very much like a lower level (memory level) implementation of the distributed system logging mechanisms. In distributed systems, logging involves rather complicated issues like role back, when commits fail. I imagine it would be very expensive to implement this kind of operation in memory level.
This comment was marked helpful 0 times.

Does eager versioning allow other processors to see the values set during this transaction? For instance, if CPU 1 initiates a transaction and writes to A, then CPU 2 reads A, will it receive the old or new value of A?
This comment was marked helpful 0 times.
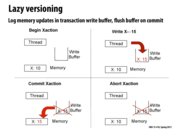
Lazy versioning makes it really easy to do an abort since memory is not changed until commit.
This comment was marked helpful 0 times.

Eager versioning has the probability that the undo-log will get lost after write but before the commit.
This comment was marked helpful 0 times.

Lazy versioning seems like it might deal better with high contention, since more aborts will be necessary.
This comment was marked helpful 0 times.



Question: In case 2 is it possible to deadlock in the following scenario:
X0: Writes A, Reads B
X1: Writes B, Reads A
In this case, it looks like both X0 and X1 will stall. How is this resolved?
This comment was marked helpful 0 times.
Is case 4 an example of livelock?
This comment was marked helpful 0 times.
@Mayank: In conflict detection, stalling may lead to deadlock. T0 reads X, T1 reads Y, T0 tries to write Y, stalls on T1, while T1 tries to write X, and stalls on T0. To make stalling practical, deadlock avoidance techniques are needed. The Greedy algorithm uses two rules to avoid deadlock: First, if T1 has lower priority than T0, or if T1 is waiting for another transaction, then T1 aborts when conflicting with T0. Second, if T1 has higher priority than T0 and is not waiting, then T0 waits until T1 commits, aborts, or starts waiting (in which case the first rule is applied).
This comment was marked helpful 1 times.
@fanyihua: Yes it is an example of livelock!
This comment was marked helpful 0 times.

Question In case 4, why do the processes only perform a "check" after 2 operations? The previous slide says that a check happens after every load and store.
This comment was marked helpful 0 times.

@mschervi Since the the operations "rdA, wrA" happened on the same processor, it will not incur conflicts, it only need to do one check when all load/store operations are done on one processor.
This comment was marked helpful 0 times.

In case 2, if X0 makes many more updates to A (before committing) while X1 is stalling, does X1 need to issue the "rd A" command again when it comes out of its stalled state? I think it does, otherwise it would be working with a very outdated copy of the A variable.
This comment was marked helpful 0 times.

Question: In case 4, why the read&write; operation on X1 will restart the transaction on X0?
If the conflict is detected by X1 and X1 is restarted, X0 will proceed and finally commit. No live lock will happen then.
I think it also sounds more reasonable to abort X1 because it comes later than X0.
This comment was marked helpful 0 times.
@lazyplus: Either aborting X1 or aborting X0 can work. Because it uses lazy versioning here, X1 cannot see X0's write. Thus, continue X0 can be correct. Besides, rd wr is atomic. Therefore, X1 didn't check after rd.
This comment was marked helpful 0 times.


Optimistic detection could be bad when there is high contention because we don't want processors to do all the work until committing point to realize there is contention and undo/restart their work.
This comment was marked helpful 0 times.
Optimistic detection is good, however, because someone is guaranteed to be able to commit changes. When there is high contention, its best to use a lock since there will always be work which one operator does which will be rolled back.
This comment was marked helpful 0 times.

Question: For Case 3 of Pessimistic detection, X0 restarts and reads updated A value. However, it seems to me that Case 3 of Optimistic detection (this slide) does not have X0 "reread" A to get updated value written by X1. So, do they result in different "state"?
This comment was marked helpful 0 times.
I think serialization of commit does not guarantee a particular order.
This comment was marked helpful 0 times.
Question: If X1 has two writes to A, can X0 commit? What if X0 reads the value of A between two writes?
This comment was marked helpful 0 times.
Question: In optimistic detection, the transaction wants to commit may have read some value of another transaction that hasn't been committed. If the transaction to commit always wins the conflict, how can this be correct?
This comment was marked helpful 0 times.
@raphaelk and @TeBoring (2nd question): Let's consider case 3 above.
Processor 0 reads A, then does some more work (presumably wring other values) and then commits its transaction. Everything is great since no other transactions committed during this time. Remember that no effects of Processor 1 are seen until its transaction commits, and it hasn't at this point)
Processor then then commits. It does not need to roll back since there have been no changes to the inputs of the transaction while it was going on. Everything is safe. Processor 0 read value A in the middle of processor 1's transaction, but that is fine. The read didn't impact Processor 1.
At the end of case 3, even though the transactions were carried out in parallel, the system is in a state that is consistent a serialized order: processor 0 executing its transaction, and then processor 1 executing its transaction.
This comment was marked helpful 0 times.
@TeBoring's first question: I believe you are referred to case 3. If so, the answer is yes. Processor 0 is performing a transaction. As long as no transaction that writes to A commits while processor 0 is in the middle of its transaction, processor 0 can commit. The system was in a consistent state when it began its transaction, and since there are no committed writes to A, processor 0 is free to commit.
Had processor 1 committed it's write prior to Processor 0 committing, then, just as a in case 2, processor 0 would have to role back since the value of A would have changed in the middle of the transaction.
This comment was marked helpful 0 times.
Question On the previous slide it says that we give priority to the committing transaction, but what about the following case?
Instructions for X0: write A, do something else, write A
Instructions for X1: read A
Then the following execution takes place: X0 writes to A, X1 reads A, X1 tries to commit
If the commit succeeds and then X0 writes to A again later on in its transaction, then this violates atomicity since X1 will have a value for A that is from the middle of X0's transaction. If we restart X0 and let the commit succeed then we have the same problem. It seems like in this case the correct thing to do is restart X1, the one that was trying to commit.
This comment was marked helpful 1 times.
@mschervi: Note that this is "lazy" data versioning. So all X0's writes are stored in buffer and not visible to X1. When X1 reads A, it sees the value before any of X0's write is visible (committed from buffer to memory)
Thus, I think an "Eager optimistic" scheme will have this problem.
This comment was marked helpful 3 times.
@Mayank. Thanks Mayank. Good answer. This slide assumes a lazy versioning scheme. Note that later in slide 51 I describe eager, optimistic as an impractical scheme to implement due to the concerns @mschervi raises.
This comment was marked helpful 0 times.
For case 3 in particular, it's important to remember that each thread does not see changes of the other thread until it commits regardless of the actual interleaving of the pre-commit operations.
Also for case 3, if the green commit occurred before the blue commit, the blue thread would have to restart since it read A, which was written to and committed by the green thread.
This comment was marked helpful 0 times.


Just to recap, pessimistic detection thinks that conflicts are very likely to happen, so whenever there's a read or a write, it will check with another thread to see if there are conflicts with their actions.
Optimistic detection is the opposite, where you think "things are going to be just fine", so you do the entire transaction, then all the checks at the end. A benefit of this is if things really are fine, you didn't unnecessarily slow anything down by doing checks with every action.
This comment was marked helpful 1 times.

Basically, pessimistic detection assumes that their going to cause a conflict and thus checks before doing the work. This undos less work, but does not guarantee something gets done and can cause more aborts. Optimistic detection assumes that their is not going to be a conflict and thus does all the work and checks afterwards. This can cause fairness problems, but guarantees that something gets done.
A real-world example is having a shared bank account with your family (with a low balance) and trying to buy groceries. Pessimistic detection would have you check your account balance before you start shopping and calling all of your family members to ensure that they are also not buying anything so that you don't get an overdraft fee. Optimistic detection would have you get all of the groceries, and then check the balance and call the family right before check out.
This comment was marked helpful 0 times.

Base -> Bad? Words -> Worlds?
This comment was marked helpful 0 times.

Haskell and Clojure appear to have built-in support for STM.
https://en.wikipedia.org/wiki/Concurrent_Haskell
https://en.wikipedia.org/wiki/Software_transactional_memory#Clojure http://clojure.org/refs
I think, from a little searching, that Haskell's implementation is lazy (not surprising) and optimistic. Not sure how Clojure does it.
This comment was marked helpful 0 times.

As shown by this slide, there really isn't any consensus with respect to which implementation of transactional memory is best. This is because the answer to that question is very workload dependent. For example, the contention around the transaction plays a big role in whether an optimistic or pessimistic approach is better. I imagine that this makes it extremely difficult to implement any sort of transactional memory that be used by a programmer at a high level and will give peak performance in most programs.
This comment was marked helpful 0 times.

There are tradeoffs between software TM and HTM. Software TM is more flexible than HTM and it doesnt require specific hardware support (other than a few atomic operations). However, it has a bigger performance overhead than HTM (cache operations are fast). On the other hand, HTM requires specific design to implement it in a system, and is contrained physically, for example by the size and performance of the cache. It therefore makes sense that a lot of systems use a hybrid model.
This comment was marked helpful 0 times.
Also, doing logs within the cache can be bad for performance of the rest of the system. If your transactions are large enough to fill up cache lines, you may need to dump your cache to disk in order to both preserve the log and allow other threads to continue their work.
This comment was marked helpful 0 times.


I'm a little confused here. How does the cache keep track of which operating system thread is running and making a transaction? In other words, how does the cache know who's read/write bits are being set? These caches are per core/per processor, so I'm not sure how you would be able to save all of the read/write bits per cache line every context switch.
This comment was marked helpful 0 times.
@fkc9001: It doesn't look like you need to know who actually did the writes and reads. If there is a conflict detected, then all read/write bits on all cached data is cleared, and I assume that the thread doing the conflicting transactions are dealt with in software.
This might change from policy to policy. I'm not sure how lazy versioning and eager versioning would differ in this example. Since all writes and reads are logged as bits, the undoing of a log would be to clear these bits. Maybe its a difference in cache coherency?
This comment was marked helpful 0 times.

Question: Before commit, does cache need to launch BusRd and BusRdX?
This comment was marked helpful 0 times.
@TeBoring: I think BusRdX will not be launched because in Lazy Versioning, writes will be put into write buffer and committed together when commit.
This comment was marked helpful 0 times.
@TeBoring: I think we can archive cache coherency by just supporting transactional memory. For example, the TCC paper claims that given all the memory operations are in transactions, TCC can
completely eliminates the need for conventional snoopy cache coherence protocols
So, we do not need to have MSI or MESI protocols to ensure cache coherency. BusRd and BusRdX is used in MSI and MESI style coherence protocol and is not needed in TM. There should be some other protocols to implement TM.
This comment was marked helpful 1 times.

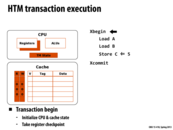
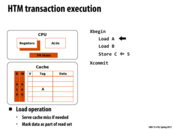
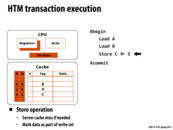

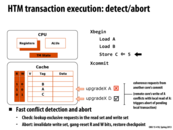


xabort will abort all the way to the outermost transaction in a nested set of transactions.
This comment was marked helpful 0 times.

Declarative: do these things. I don't care how you do it. Imperative: do exactly these things and do it as the way I told you to.
This comment was marked helpful 0 times.
In the WSP assignment we used
with possibly some other options. This is declarative: we are telling the program what to do (do this loop in parallel with dynamic scheduling), but not how to do it.
This comment was marked helpful 0 times.