




In this demo, first we had one person sum up ~14 numbers, which took around 34 seconds. We then had two people far away from each other sum up half the numbers each, but only allowing communication through the passing of a sheet of paper. It took around 18 seconds for the partial sums to be computed, but a total of ~30 seconds for the final sum to be called out due to the "communication time" of passing the paper.
Even though we had double the "processors", the speedup was not 2 because of the overhead from communication.
This comment was marked helpful 2 times.

Some potential solutions to this issue were also discussed. We could attempt to reduce latency in communication of the "processors" by moving them closer together or improving their communication speed, analogous to positioning silicon and reducing memory latency IRL. Alternatively, this job could be performed serially, as the overhead of parallelism is not worthwhile for such small jobs.
This comment was marked helpful 1 times.


Is there any other motivation for using parallelism? Namely, is there any problem we can solve using parallelism but can't using a single process, given infinite time and finite space(or whatever other measures).
This comment was marked helpful 0 times.

One answer is that the ability to solve problems faster due to parallel execution has made some tasks which were previously not possible, possible. People are now attempting to do what they never considered in the past. For example, real-time ray-tracing with massively parallel graphics processors.
If we ignore the above answer, then what you mention is essentially right. Given infinite time, a single processor is capable of doing what a multi-processor can do. But even in a CPU system, the CPU is not the only processing element in the computer. There was always a small micro-controller embedded to handle hard-disk or some logic to handle I/O.
Another motivation for parallelism is power (as mentioned in class). If you finish some work in half the time with 2 core processor, you can shut-down the device. You might think that 2 processors in half the time will consume same power - and you are right. But the 2 processors also share other resources like memory system, hard-disk, display screen of the computer. Shared resources are powered-up if any of the processor is working. So, when task finishes in half the time, you save power by powering down these shared resources. You don't have to do that as a user, unused parts of a systems power down themselves without users knowing about it.
Some systems have parallelism for fault tolerance. They perform the same computation on replicas of same hardware and then compare the results to make sure things were correct. This can be done at fine granularity, such as replicating and ALU or some other sub-unit of a processor core. This is a whole research area.
This comment was marked helpful 3 times.

One more example for the eager need of speedup: If the weather predicting program needs one day to get the next day's prediction from today's data, then the result would be meaningless. Because once we got the answer, the "next day" was already yesterday.
This comment was marked helpful 0 times.


How good/bad are communication times?
This comment was marked helpful 0 times.

In this demo, four students who were adjacent to each other computed partial sums, and could only communicate by writing on a single sheet of paper with one pen. However, one student had only 1 number to sum, another had around 7, and the other two had around 3 each. The student with 1 obviously finished first, while the student with 7 took far longer. During that time, the 3 students with fewer numbers added their partial sums on the paper, similar to the idea of not wasting cycles idling and instead taking useful work.
Even though we had four "processors", the speedup was not 4. I can't remember exactly, but it took perhaps around 22 seconds for the final sum to be returned (not including the time taken to sum the partial sums, since in theory it should take the same amount of time to sum two-digit numbers as single-digit numbers).
A way to better distribute the tasks to prevent idling would be to have a pile of jobs, and after computing your current sum, grab another number (slip of paper) to add to your already computed partial sum, and then combine them once the pile runs out.
This comment was marked helpful 1 times.

It also looked to me like some of the students had to wait to write their part of the sum while the other students used the pen. Since there was only one pen, students had to wait for this "shared resource" before they could write down their sum on the shared paper. The pen was also needed to compute the intermediate sums. It might not have made a big difference in this example because they had to wait for the last student to add his numbers anyway, but I think the effect of waiting for the pen would have been more visible if students had two sets of numbers to add and they had to write down the first sum before starting to add the second one.
This comment was marked helpful 4 times.

@mschervi I think an interesting parallel can be drawn between the pen and a bus in a multi processor system. The pen, in this case, serialized the "writes" to a shared resource(the paper). If everyone had tried to write to the same resource at the same time, things might have gotten messy.
Similarly, a bus, in certain multi-processor systems, is used to determine the total serial order of writes to a given memory location. Cache controllers can "snoop" for these writes to achieve cache coherence.
This comment was marked helpful 1 times.

Manish, you're getting quite ahead of us in the course. That's lecture 10. ;-)
This comment was marked helpful 1 times.
I couldn't resist! It was staring me in the face :)
This comment was marked helpful 1 times.


Work imbalance can result in a significant performance loss; for example, if only one processor had a lot of work, this would be similar to having a large sequential fraction and result in speedup loss based on Amdahl's law. Instead appropriate assignment of work between processors (for example, using work queues as we see in later lectures) can result in improved speedup.
This comment was marked helpful 0 times.


In this demo, all the students were asked to collaborate and compute the total CS courses taken by everyone in the class. An interesting thing I observed in the demo was in the initial few seconds, everyone calculated local sums (sums of courses taken by neighboring students), then one of student from each group communicated the sum to other groups in the same row. This resulted in row-wise sum and which led to addition of sums from different rows. I think the last sum calculated was between the front half and back half of the class (~130 + ~140). Following things can be observed from this demo:
- Locality helps and hence natural instinct was to calculate local sums first (and not between 2 people in different corners)
- A leader (master) was chosen (although arbitrary in this case ... the person was more likely to be in the middle of the row / class ) for communicating the group sum to the next group.
- As we progressed in the computation, more and more number of "threads" (students) were idle and in fact there was a lot more noise due to idle students which might have hindered communication.
This comment was marked helpful 3 times.

A point brought up in another part of the lecture slides claimed that some students were not paying attention which caused them to spend more time calculating their answers. This alludes to some threads that could exist in a program that are estimated to take a certain amount of time to finish the work but perhaps spend more time performing the operation because of idle behavior or other circumstances that could randomly occur. As we could see in the demo, this hindered the ability for the class to efficiently get a correct answer to the problem.
This comment was marked helpful 1 times.


In demo 3, Kayvon asked us to figure out how many computer science courses we were all taking (count the number of 15-XXX courses taken by all students in 15-418). Without any specific direction, it seemed that the majority of the class tried to get a number for his or her row, and then combine with the rest of the rows in the room. This worked for individual rows, but the combining steps were messy and it was pretty unclear as to which rows had already been added when combining larger sections. This was one of the best 'real world' examples I have seen to explain communication costs between threads / processes. This also demonstrated how difficult it can be sometimes to determine the best way to write the 'combine step' in a parallel program.
This comment was marked helpful 5 times.

Also: A central coordinator or at least an agreed plan-of-action would have helped a ton.
This comment was marked helpful 0 times.

Another interesting point to consider is that some of the students were not paying attention and ended up taking a while to answer the question.
From a parallel computing perspective, this is equivalent to some subunit taking much longer than expected to complete computation on its workload. Therefore, an important thing to keep in mind for parallel computing is load balancing - there may exist data sets for which initially assigning an apparently "equal" amount of work to each sub-unit is not the fastest or most efficient way to complete the task. That is, either more analysis or some degree of dynamism may be required.
This comment was marked helpful 6 times.

Also, we observe that in the process of getting the sum of a single row, most students tried to summing from both the leftmost and the rightmost, and then the students in the middle can add the two parts up. And in the combining steps, the last combining step also happens in the middle of class. From computing perspective, this is like the case that some machines are connected "closely" and the communications between them are quick while some would take a long time to communicate.(Like Demo 2 in class). Then, sometimes we might make use of the particular style of networks to design efficient algorithms.
This comment was marked helpful 3 times.

Yes, the lack of organization definitely cost quite a bit of time. Our programs won't have to "figure out" how to combine data, since that would have to be explicitly managed by the code. So, at least there's some variance in human vs. cpu communication overhead, but serves to make the same point.
The posts above raise many good points. Even if a program is written to take "perfect" advantage of the hardware it's being run on, there are still outside factors that would detract from the performance. In particular, rarely is just one thing running on a computer. To make an extreme example, suppose a program is optimized to run on 4 cores (e.x. spawn 4 threads each with 1/4 of the work), but another process is already fully utilizing one core. So, 3 run immediately and the 4th has to wait.
This comment was marked helpful 2 times.


Is there a point where scaling the number of processors will not achieve much speedup? Is there a number of processors where the distribution and re-combination of work among them takes so long that using a smaller fraction of them would be faster? Basically I'm wondering if there is a limit to how much we can scale the number of parallel processors.
This comment was marked helpful 0 times.

Yes, if there are fifteen million operations and you have fifteen million cores each would do a single operation (finishing everything in one clock cycle), adding any more wouldn't yield any increased speedup because you couldn't give that core anything to do and you can't really do something faster than one clock cycle.
Yes, say for example you wanted to add 4 numbers together, if each add takes a clock cycle then this would finish in 3 cycles on one core, but if we had 2 cores then one would add the first two numbers and the second core would add the second two at the same time, and then the first could add the two partial sums. If passing data took no time then this would get done in 2 cycles, but likely it would take at least a few cycles to get the info from the second core into the first so it is entirely possible that using two cores for such a simple task would actually be slower.
This comment was marked helpful 0 times.

- (erm, 3) Even if we don't consider putting an exact number on the amount of data to be processed, as the amount of work increases, the assumption that data sharing can be done near-instantaneously will begin to break down. Just as single processor computation is limited by how dense circuits can be packed, the performance of multi-processors is limited by how dense the processors can be packed. This means that resources will have to be shared in more clever ways.
This comment was marked helpful 0 times.


It's important to understand the hardware implementation of the machine you are programming on in order to understand the most efficient way to implement your program. Referring back to the demos in class, it makes a huge difference whether the processor:
- shouts the answer
- passes the answer on a sheet of paper
- mails the answer
- gets jiggy with the answer
The machine characteristics should influence the implementation of your parallel program.
This brings up the question of - how portable are parallel programs?
This comment was marked helpful 1 times.
Speaking of portability- one way to parallelize, as discussed in class, is through SIMD (discussed later), implementation of which relies upon the processor's instruction set. Note the disparity in support for one such group of instructions between manufacturers, Intel and AMD, and Operating systems: http://en.wikipedia.org/wiki/Advanced_Vector_Extensions#Operating_system_support
This comment was marked helpful 0 times.


What is the maximum possible speedup of a parallelized program? Ideally, we would expect the speed-up from parallelization to be linear. However, most of them could not have a near-linear speed-up when the processors number grows large. The potential speed-up of an algorithm on a parallel computing platform is given by Amdahl's law. It states that a small portion of the program which cannot be parallelized will limit the overall speed-up available from parallelization. In other words, the speed-up of a program from parallelization is limited by how much of the program can be parallelized. For example, if 80% of the program can be parallelized, the theoretical maximum speed-up using parallel computing would be 5x no matter how many processors are used.
Reference: wikipedia -- Amdahl's law. http://en.wikipedia.org/wiki/Amdahl's_law
This comment was marked helpful 0 times.
Is 2x speedup on 10 processors a good result? It depends on what your program does.
The example given in class was a 2x speedup on 6 processors for a computer game. If it had previously been running at 15 fps, the speedup would be significant in this situation, since it would render the game playable.
This comment was marked helpful 0 times.

@lkung "It depends on what your program does"
My initial thought is that it has nothing to do with what the program does, and everything to do with what is the associated cost of scaling to 10 processors. Does it require a significant refactoring of code? How large are the energy / hardware costs for the extra processors?
10s -> 5s, 1hr -> 30 min, and 2 days -> 1 day is always a win. The question is simply "at what cost?"
This comment was marked helpful 0 times.
@bscohen Yes, I think that's a better way to phrase it. "It depends on the cost." Of course, the cost depends on what your program does. For example, it would be worth the high cost of refactoring to make a game run faster, and therefore playable. However, the same refactoring cost may not be worth it for another program that doesn't have the same constraints.
This comment was marked helpful 0 times.

Efficiency of communication between processors should be counted on both software level and hardware level. In general, there are many works on hardware design to improve it, such as processor affinity. But when I look at new technology, such as MapReduce, it mostly depends on the software to complete it. What has the hardware supplied, or what can the hardware supply for synchronization/communication? What degree can it supply compared to the software?
This comment was marked helpful 0 times.






Just as a note, the non-trivial prizes were actually given out last time. NVIDIA gave out GPUs and Intel gave out solid state disks.
This comment was marked helpful 0 times.
They also gave out a couple of books - Programming Massively Parallel Processors and CUDA Application Design and Development.
So, yeah, bring your A game guys! Also, check out some of last year's projects.
This comment was marked helpful 0 times.

Uh... Anyone want to go out on a date with me for the first assignment?
This comment was marked helpful 3 times.

Oh, LATE days.
This comment was marked helpful 0 times.
I'm leaving this typo in the slides because it's so awesome.
This comment was marked helpful 1 times.
This has been changed to 38% Assignments 28% Exams 28% Projects 6% Participation
This comment was marked helpful 0 times.



During the good old times, from the 1980's to early 2000's, people cared less about parallelizing their code than they do now. The hardware vendors that put lots of effort in multi-core machines pretty much all lost on the market. The whole industry is driven by Moore's law: the clock frequency and the number of transistors doubles for every 18 months, which translates to doubled single- thread performance. The thinking was... why even bother to write parallel programs if the serial versions get faster with future CPUs?
After 2000, people figured out that there were too many transistors put on a fixed small area that they were too dense for the heat sink to dissolve the heat. The net result was high power consumption and high heat density. Did you know that the Pentium 4 was originally designed to operate at 5 GHz? We only saw Pentium 4 processors max (with normal air cooling) at around 3 GHz. This was because the engineers at Intel later figured out the chip would simply melt away at such high frequency. However, the design was optimized at 5 GHz and running at lower frequencies could not fully unleash its power . In terms of performance, Pentium 4 series was beaten by AMD's same generation chips: Athlon64 (64-bit machine) and Athlon64x2 (2 Athlon cores). Athlon64x2 was the landmark that we were entering the new multicore era, because now the single thread performance stopped increasing (as the clock frequency stuck at 3GHz), the only way to make the computer run faster is to put more cores in it (as the number of transistors still doubles for every 18 months). As a result, programmers are now incentivized to learn how to write parallel programs... that's why we are all here sitting in Kayvon's class.
Enjoy the rest of the class. Peace out.
This comment was marked helpful 0 times.

Transistor count wasn't the main problem, in fact transistor count is still following Moore's Law. The real problem is the clock speed driving those transistors, as hxin mentioned. Energy is consumed every time a transistor switches from on to off and viceversa. So higher clock speed causes larger dissipation of heat. Here you can find an more thorough explanation between transistor count and clock speed.
This comment was marked helpful 0 times.

Could someone give a high level description of what a transistor does?
This comment was marked helpful 1 times.

Transistors are the basic units of everything in a CPU, cache, ALU, branch predicter etc. Typically, as it says in lecture 1, slide 12, more transistors means larger cache, smarter control and faster computations. And the switching speed of transistor is related with clock rate, as @Xiao says.
This comment was marked helpful 0 times.

transistors are basic units that provides either 1 or 0 (high or low voltage). now intel use 3d-gate transistors in ivy-bridge cpus (http://en.wikipedia.org/wiki/Trigate_transistors#Tri-gate_transistors). It needs less power to sustain and be able to performance stably. The revolution of transistors helps significantly in CPU performance. Not only they are made smaller, they also focus on power consumption (getting the same performance with less current going through ). In addition, as power awareness is growing to be a problem. Intel's next generation cpu (haswell and skylake) puts a lot efforts in heat dissipation.
This comment was marked helpful 0 times.
As people have pointed out. The reason is that the frequency stopped scaling. Although Moore's law is all about the number of transistors for unit area, however, in the past, smaller transistors typically also enables higher frequency. As a result, David House, Intel ex-CEO extended Moore's law as "who predicted that period for a doubling in chip performance (being a combination of the effect of more transistors and their being faster)" .
Now, the more transistor part keeps on, however, the being faster part has halted. As I and Xiao pointed out above, it's because of high energy consumption. Then the question is: throughout all the years from 1980s to early 2000s, why we have not run into the energy wall? Why we could keep increasing frequency while maintaining a roughly constant power through out those year but we no longer be able to do it now?
To understand this problem, let's first look at the transistor itself. Transistor is a micro electrical switch. Internally, it is a capacitor, a static well. The transistor is an open circuit if the well is empty and is a closed circuit if the well is full filled. In order to switch on and off the transistor, we need electrical energy to fill and drain the static inside the transistor's capacitor. As a result, here is the relation ship: bigger transistor, bigger capacitor, more energy to operate. Smaller transistor, smaller capacitor, thus less energy to operate.
If you think of shrinking transistor, we are shrinking them in 3 dimensions. scaling the transistor in every dimension means shorter length, width and lower height of the transistor. Although it is not exactly the case, but the you can envision it as the capacity of the transistor and hence the energy required to operate the transistor scales cubically with a smaller length in each dimension. If the scaling factor of the transistor in each dimension is S, then the reduction of energy is $ E_{single \space operation \space new} = S^{3} \times E_{old}$
However, as the transistors are laid out on a two-dimension plane, the number of transistor increase inverse quadratically with a smaller dimension. The number of transistors scales as $ N_{number \space of \space transistor \space new} = 1/S^{2} \times N_{old} $ .
Let us now assume the frequency of the processor is $ f $, which is the frequency we fill and drain the processor, and the previous generation of technology manufactures chips with $ N_{old} $ transistors while each transistor consumes $ E_{old} $. As a result, the chip power consumption of the whole chip is $ P_{old} = f_{old} \times N_{old} \times E_{old} $.
With a scaling factor S, the new chip's power consumption is: $ P = f_{new} \times N \times E = f_{new} \times 1/S^{2} \times N_{old} \times S^{3} \times E_{old} = f_{new} \times S \times P_{old} $.
From the equation above, we can observe that we can keep the power roughly the same while increase the frequency by a factor of $ 1/S $ (S is smaller than 1). This is why in the past, we can increase both the frequency of the chip and the number of transistors of the chip.
However, this is no longer the case. After we have scaled down the transistor smaller than 1 micrometer, the operating energy of a single transistor stopped to scale as much as they used to. In another word, $ E_{new} = S^{2} \times E_{old} $ now instead of $ E_{new} = S^{3} \times E_{old} $. There are two causes: first, the transistor is so small such that the capacitor inside the transistor is only a few layers of molecules thick and the capacitance now is determined by the physical property of the $SiO_{2}$ rather than the geometry of the capacitor; second, because the capacitor is so think now, it is no longer considered as a good insulation. The thin capacitor is now leaking a lot of energy and the chip have to constantly fill up the transistor, increasing the static energy consumption.
The no longer perfect scaling energy consumption of a single transistor is the cause of the power wall, which is presented as the frequency stopped scaling.
This comment was marked helpful 1 times.


Other reasons for processor performance improvement : Improving bandwidth of FSB (Front side bus) ,Improving Cache Memory
This comment was marked helpful 0 times.

Even though superscalar processors silently take advantage of ILP and provide speed ups without users needing to know what's happening underneath the hook, programmers can willingly increase the ILP of their programs to increase the effectiveness of these processors. Increasing ILP is often times easier to do compared to program-wise parallelism. Small modifications to existing programs could increase performance significantly. One example technique is loop unrolling, which is explained in the 213 book (chapter 5). This paper gives another detailed explanation between ILP and loop unrolling for those interested.
This comment was marked helpful 1 times.
@Xiao: I think usually these types of optimizations are best left to the compiler. Your source code doesn't have much resemblance to the assembly that is output by sophisticated compilers, and they actively look for these opportunities.
This comment was marked helpful 0 times.
I believe that ILP is part of the micro-architecture. So exploit of parallelism using techniques such as branch predictor, out-of-order execution underneath doesn't effect programmer level interface. And there are many techniques that programmer can use including loop unrolling as @xiao says.
This comment was marked helpful 0 times.
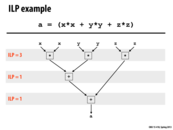

We mentioned how it wasn't really possible for a compiler to maintain such a DAG for an entire C program. One language feature of C that would be extremely difficult to account for is computed pointers; for example, the fact that function A's 0xDEADBEEF must reference the same memory location as function B's 0xDEADBEEF, even if there is there is essentially no symbolic relationship between A and B. What are other large obstacles to automatic generation of such DAGs for full C programs?
This comment was marked helpful 0 times.

I may be wrong here, but I'll give it a stab - One problem with generating a DAG for a full C program might come up if the C program were a JIT compiler for another language. JITs (I think?) often exhibit the behavior of taking bytecode input, writing machine code out to a page in their address space, and then executing the machine code that they've just written. It seems like it would be impossible to generate a full DAG at compile-time for a program where part of the code depends on unknown user input and will not be generated until runtime.
This comment was marked helpful 0 times.

This example is showing that the computing xx, yy and z*z are all independent instructions(ILP = 3), and can be computed in parallel using superscalar execution. After this, you add any two of them, while the third one remains idle. There is no way to do more than this step at the same time, so the ILP = 1. And finally, we add the third one to the sum of the other two.
This comment was marked helpful 0 times.

This graph plots the speedup achieved (for single-threaded workloads) as the instruction-issue capability of a superscalar processor is increased. The number of instructions the processor can issue in a single clock is varied along the X-axis. Notice that additional instruction-issue capability does not translate into substantially better performance once the design goes beyond an issue capability of about four. On average, real-world programs simply do not have enough instruction-level parallelism (a.k.a., sufficiently many independent instructions) to saturate the "wide-issue" capabilities of the designs plotted toward the right of the graph.
This comment was marked helpful 0 times.

As an aside discussed in class, the processor can only "look" at narrow windows of the program for superscalar execution. It cannot look at the whole program and identify independent instructions since in this case, the processor would do more work detecting the independent instructions rather than executing them.
This comment was marked helpful 0 times.

Are there any good papers/sources explaining some of the research related to instruction level parallelism?
This comment was marked helpful 0 times.
@i_lick_batteries As professor Kayvon mentioned in class, a lot of the research is done from the computer architecture perspective, as superscalar performance depends also on how the instruction pipeline and instruction fetching is designed. This paper provides a good study on the inherent ILP of many well known programs/benchmarks, without digging too deep into the details of computer architecture. Also googling ILP and superscalar computing yields many more interesting articles.
This comment was marked helpful 2 times.

Question: You'll often hear people incorrectly state that "Moore's Law" says processor performance doubles every two years, but Gordon Moore wasn't specifically talking about performance in his famous quote. What is the real Moore's Law? How does it relate to the curves on this slide? Does Moore's Law still apply today?
This comment was marked helpful 0 times.

Moore's Law states that the number of transistors on a chip will double every two years, which relates to the green curve on the graph. Moore's Law still applies today and is evident in the technologies used in our phones, laptops, and other consumer electronics. Intel is constantly inspired by it.
This comment was marked helpful 2 times.
For the curious, Cramming More Components is the actual paper from where Moore's law comes.
This comment was marked helpful 1 times.

TDP is short for "thermal design power" (or "thermal design point"). This is the amount of power that a cooling system must dissipate, provided by the chip manufacturer*. This is important because fast chips consume a lot of power and, through conservation of energy, turn that power into heat. If the chip isn't cooled properly, it's going to fail and you will be sad.
* This can vary. AMD defines TDP to mean the maximum current the CPU can draw, at the default voltage, under the worst-case temperature conditions. Intel publishes TDPs that are the average power that the processor can dissipate (to be used for processor thermal solution design targets).
This comment was marked helpful 1 times.
Regarding the equation, it was said in class that we can reason, "To push frequency higher, there is a non-linear power cost."
This comment was marked helpful 0 times.

I think it's interesting to note the relatively tiny TDP values of mobile phone processors. Phones are uniquely limited in that their usefulness is dependent on their battery capacity and physical size. Since it appears that advances in processors are coming much faster than advances in battery capacity, phone processor designers have to pay extra close attention to power usage since it's not feasible to just increase the sizes of batteries for more power-hungry processors. This issue isn't as limiting (yet?) with GPUs for example, since high-end GPUs can still be accomodated by using PSUs with higher ratings.
This comment was marked helpful 0 times.

An increase in frequency leads to an increase in voltage. So, in terms of the equation, an increase in frequency leads to a non-linear increase in power. That is why there seems to be a frequency ceiling of around 4 GHz for today's CPUs. Even Intel's top of the line i7 processors have a stock frequency of around 3.5 GHz.
This comment was marked helpful 0 times.

The industry seems to have fully embraced this, with Intel desktop CPUs having lower TDPs every year or every other year: quad core Nehalem CPUs typically had TDPs of 95w or 130w, quad core Sandy Bridge CPUs typically had TDPs of 95w, and quad core Ivy Bridge CPUs typically have TDPs of 77w.
Another contributing factor to this decrease in TDPs on Intel's part is that Intel wants to improve efficiency for various reasons, especially mobile.
This comment was marked helpful 0 times.

The power wall is important from everything from mobile phones to supercomputers. For supercomputers, heat generated is heat that needs to be removed via air conditioning systems, which have their own power cost associated with them. Mobile phones need to not build up heat because no one wants to hold a burning brick in their hands or next to their ear.
This comment was marked helpful 0 times.
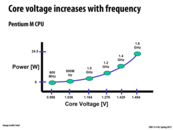


This graph shows that even though Moore's law seems to be holding for transistors, the factors relevant to speed of computation (Clock Speed and ILP usage) are plateauing this. And this is because the power usage for increasing clock speed results in an exponential increase in the power used by the computer. These factors are pushing the burden of improving speeds from the hardware architects to the software developers. Rather than simply waiting a year or two for a faster computer to come out making our code faster, we must instead be able to write code that will scale with more processors, allowing it to be faster.
This comment was marked helpful 0 times.
As multi-core processors become the de facto standard, isn't it possible that the OS might reserve a core for itself and other programs might be given exclusive control of their cores.
Without all the processes sharing the same core, your code will get a natural speed boost.
This comment was marked helpful 0 times.
@joe: I think the CUDA model is kind of what you described. Because the workload in CUDA model is usually computation bounded, exclusive access to the cores would offer speed boost.
However, The workload on general CPU would be more of processes dealing with I/O device such as keyboard, mouse or disk. Exclusive access to some cores often lead to spin wait and do nothing. This is what general OS tried to avoid and I think this is why we need an OS to switch among so many processes.
This comment was marked helpful 0 times.

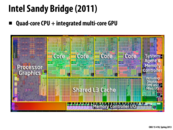

This diagram is of an Intel Sandy Bridge microchip. As Kayvon explained yesterday, Sandy Bridge is a 2011 microarchitecture, which has since been superseded by 2012's Ivy Bridge (which in turn will be superseded by the upcoming Haswell microarchitecture). Even though some Sandy/Ivy Bridge chips (like the one above) only have 4 physical cores, many of them also utilize hyper-threading, which allows each core to run two threads simultaneously. This means that these kinds of chips will have an additional 4 logical cores, and are capable of running up to 8 threads simultaneously. It's pretty amazing too they're able to offer so much raw processing power while still offering pretty decent integrated graphics performance. Intel's also promising much improved processor graphics with Haswell.
This comment was marked helpful 1 times.

Even GPUs are implementing multi-core technology in order to exploit parallelism. NVIDIA's Kepler GPU also uses something called dynamic parallelism. It simplifies GPU programming by allowing programmers to easily accelerate all parallel nested loops – resulting in a GPU dynamically spawning new threads on its own without going back to the CPU.
This comment was marked helpful 0 times.


NVIDIA recently unveiled their upcoming Tegra 4 SoC for mobile devices at CES 2013, which will have a quad-core ARM CPU and 72 custom GPU cores, giving it 6x more graphics power than the current Tegra 3. The Tegra 3 is already in use in a variety of mobile devices such as phones, tablets, and notably the Microsoft Surface RT. The Tegra 4 will unfortunately not have support for CUDA, but it is anticipated that a future Tegra will. See NVIDIA's site for more information on it.
This comment was marked helpful 0 times.

Also note that Tegra 4 is one of the first SoCs that features quad-core ARM Cortex A15 cores on-board, which is a multicore ARM architecture processor providing an out-of-order superscalar pipeline ARM v7 instruction set. ARM has confirmed that the Cortex A15 core is 40 percent faster than the Cortex-A9 core (used in Nvidia's Tegra 3 SoC) with the same number of cores at the same speed. In addition, Tegra 4 continues the 4-plus-1(low power core) design, which efficiently reduces power without having to sacrifice performance.
This comment was marked helpful 0 times.
Question: We're getting way ahead of ourselves in the course, but can anyone describe what the "4+1" design that @kailuo mentions is, and why architects might have chosen to do that?
This comment was marked helpful 0 times.
The 4-PLUS-1 design is: in addition to the four main "quad" cores which handle the majority of high intensity computation, a fifth CPU core (the "Battery Saver core") is included onto the board. This core is built using a special low power silicon process that executes tasks at low frequency for active standby mode, music playback, and even video playback. Simply put, this fifth core exists to handle (mostly) background tasks (e.g. email syncs when your phone is in standby state) using much less power.
This comment was marked helpful 1 times.
@Xiao you've worked on power management for Tegra 3, any insights?
This comment was marked helpful 0 times.

It is also interesting to note that the 5th "Battery Saver" core is OS transparent. i.e, the OS and the applications are not aware of this core but automatically take advantage of it specially during the active standby state (when the user is not actively interacting with the device).
By using a 5th core during the active standby state, the power consumption is minimized, therefore improving the battery life significantly.
Reference: The Variable SMP whitepaper.
This comment was marked helpful 0 times.


Question: In 15-213's web proxy assignment you gained experience writing concurrent programs using pthreads. Think about your motivation for programming with threads in that assignment. How was it different from the motivation to create multi-threaded programs in this class? (e.g., consider Assignment 1, Program 1)
Hint: What is the difference between concurrent execution and parallel execution?
This comment was marked helpful 0 times.
Threads are about latency (responding quickly); parallel execution is about minimizing total time. These two metrics are totally independent.
Edit: A previous version of this comment said "work" instead of "time" (because I forgot "work" was a technical term at CMU), prompting some of the comments below.
This comment was marked helpful 0 times.
I've always liked the way these slides explain it; concurrency is about splitting a program up into tasks that can communicate and synchronize with each other, whereas parallelism is about making use of multiple processing units to decrease the time it takes for a program to run.
This comment was marked helpful 3 times.
The thing is that there's an overhead to splitting up data or tasks to take advantage of multiple processing units -- it's a tradeoff. The parallel implementation is actually more total work (in terms of total instructions executed), but your task gets done quicker (if you did a good job writing your code). Though I guess you might save energy by not having a bunch of cores idling while one core crunches away at a serial task...
This comment was marked helpful 2 times.
To further elaborate on concurrency: it is about doing things simultaneously, and includes not only the division of a single program. Concurrent execution was important before multi-core processors even existed. I suppose you could call scheduling multiple tasks on a single CPU "false" concurrency, as from the CPU's perspective they are not concurrent, but nonetheless to the users they looked simultaneous and that is important. Often times, the user prefers progress on all tasks rather than ultimate throughput (assuming single CPU). This goes back to the proxy example mentioned by professor Kayvon. Even if our proxy was running on a single-core machine, the concurrency would still be very useful as we do not wish to starve any single request.
This comment was marked helpful 4 times.
@jpaulson: When talking about parallelism, its useful to talk about work and span. Work is the total amount of instructions across all threads. Span is the length of the longest chain of dependent instructions (the ones that must be executed sequentially). There is a pretty good writeup on the basics of parallelism available from Intel. Note that by definition, parallel programs cannot reduce work.
This comment was marked helpful 1 times.
If you, like me, were wondering what it means to be parallel without being concurrent, check out page 23 of the the Haskell slide deck that gbarboza linked. This is apparently known as deterministic or pure parallelism.
Concurrent but not parallel: OS or a server on a single core
Parallel but not concurrent: SQL queries
(Also, shouldn't we just be programming in Haskell? =P )
This comment was marked helpful 1 times.
Concurrency is about dividing program into pieces that can be done simultaneously.
Parallelism is about making use of multiple processing units.
Concurrency can solve two kinds of problems:
1) Non-deterministic control flow: Take the web proxy as an example. If three threads (A, B, C) are waiting for response from internet. Responses for B and C come first, the one for A comes later. If not using concurrency, B and C needs to wait for the response to A. If using concurrency, B and C can terminate first. On one hand, this decreases the latency for B and C. One the other hand, throughput is increased since the total time decreases from time for A and B and C to time for A only.
2) As Xiao said, concurrency can guarantee progress on all tasks rather than ultimate throughput.
Parallelism can solve one problem:
As alex said, parallelism can decrease the total time from the time for work to the time for span, while the best time for concurrency is the time for work.
The last thing to mention is to when solving problem with parallelism, concurrency is also used. Because parallelism needs to know what things can be done at the same time. Therefore, when using parallelism, the problems solved by concurrency are also solved.
This comment was marked helpful 1 times.
Can someone clarify a little more about performance and efficiency? I know performance can be measured by speedup, but it may still be not efficient. Can someone give me a more concrete example? Thanks.
This comment was marked helpful 0 times.
In my view, performance indicates how good the execution of the work is, while efficiency means whether it uses the minimal cost of effort to perform the best possible manner.
For example, at one time, the program needs 1 hour to finish its work. To solve problems quickly, we use parallelism technology now. As a result, it is run on 10 processing elements instead of 1, and uses only 30 minutes to complete.
The running time of the program(performance) reduces from 1 hour to 30 minutes, which is 2x speedup. The utility of computing resources(efficiency) becomes 20% of original one, because it uses 10x processor elements and achieves 2x speedup.
lecture 1, slide 12 gives some explanation on it, too.
This comment was marked helpful 1 times.