QUESTION:In what scenario exactly do we achieve 1/8 peak performance? And what do we mean here by saying peak performance?
jerryzh
When one branch is significantly longer than the other branch and it is only executed in 1 of 8 ALUs, we will achieve approximately 1/8 peak performance. Because if we fully utilize the ALUs, we'll be using 8 out of 8 ALUs rather than 1 out of 8. I think peak performance can be viewed as utilization rate.
dhua
It seems that we can avoid conditional branching in certain cases by using sign bits:
// Branching code
if (x >= y) {
x = f1(x);
} else {
x = f2(x);
}
// Non-branching code
float s = get_sign_bit(y - x); // 1 if x >= y, 0 otherwise
x = s * f1(x) + (1 - s) * f2(x);
In practice, are there any benefits for using the non-branching version of the code?
TomoA
@dhua I'm not sure that we would benefit from using sign bits in that way, since we move from having useless ALU's to having computations that do the work of both functions f1 and f2. In terms of the above graph, the vertical height of each column would still be the same, except that now the return values for all the ALU's will matter and we will need additional post-processing.
jerryzh
@dhua, branches are necessary since functions(or instructions in different branches) will have effects, such as memory operation or exceptions, and executing both of them will alter the meaning of the program.
makingthingsfast
On a separate note, it was interesting to learn that SIMDs have shared instruction streams while multicores can do different sets of instructions. I actually was curious to know, can we calculate how much longer the code block needs to be in one branch in order to reach a certain peak performance?
monkeyking
I agree with jerryzh that peak performance can be viewed as utilization rate. Suppose there are two branches, the first one runs in $a$ clocks while the second one runs in $b$ clocks. And there are $x$ elements go to the first branch while there are $y$ elements go to the second one. The the utilization rate is :
$$
\frac{ax+by}{8(a+b)}
$$
When y = 1, that is, when there is only one element goes to branch two, the utilization rate is:
$$
\frac{ax+b}{8(a+b)} = \frac{\frac{a}{b}x+1}{8(\frac{a}{b}+1)}
$$
If $b \gg a$, the right hand side is approximately $\frac{1}{8}$. This is the situation that only one element of input goes to the second branch and the execution time of the this branch is much longer than another one.
yimmyz
@monkeyking Thanks for the formalization of utilization!
An easy way to understand the fraction $\frac{ax+by}{8(a+b)}$ above: Imagine each clock of each ALU as a cell in a matrix. In total there are $8(a+b)$ such cells, and the ones put into use are $a$ runs of Branch A and $b$ runs of Branch B, totaling to $(ax+by)$ units of work.
Thus, the util rate is as given above.
arcticx
Is this still SIMD? I think SIMD is just a technique to decode once and process multiple data. And "decode" here means decoding a single instruction. However, in this case, the SIMD seems able to decode multiple instructions at the same time (because ALUs are doing different instructions).
althalus
I think it is possible to use SIMD instruction and output a vector if 1s and 0s based on the conditional and take the correct output based on the vector. This way, all the ALUs will be doing useful work all the time (smilier to a mask).
kipper
@arcticx, I'm under the impression that it's still SIMD, because all ALUs execute the same instructions, but here's the catch: if an ALU is executing instructions that don't apply to its particular element (e.g., say, in the diagram, ALU 3 is executing code for the if branch, whereas it actually wants to execute code from the else branch), then its output is masked / ignored. In this way, all ALUs are executing the same instruction stream, but the results of certain instructions are ignored when they are not applicable. I believe Kayvon says in lecture that the compiler is responsible for applying the masks in the right place to guarantee correctness.
karima
@kipper correct.
@arctix, check out the ISPC user's guide here
which explains how the compiler uses masks when executing if statements:
"...the program counter steps through the statements for both the "true" case and the "false" case, with the execution mask set so that no side-effects from the true statements affect the program instances that want to run the false statements, and vice versa.
However, a block of statements does not execute if the mask is "all off" upon entry to that block. The execution mask is then restored to the value it had before the if statement."
note the optimization of not executing a block of statements if the mask is all off for that block.
TanXiaoFengSheng
I think it makes more sense to refer it as Peak Utilization than Peak Performance, since the performance of a program is intuitively limited by the structure of program itself
nramakri
The performance of SIMD instructions highly depends on the type of input being processed. If a larger chunk of the instructions is executed by only one ALU then we will have very poor utilization of resources. Thus, it is the programmer's job to write a program that ensures the resources will be utilized, either by distributing instructions between both if and else blocks evenly, or by making sure the input isn't skewed in a way that creates the worst-case scenario.
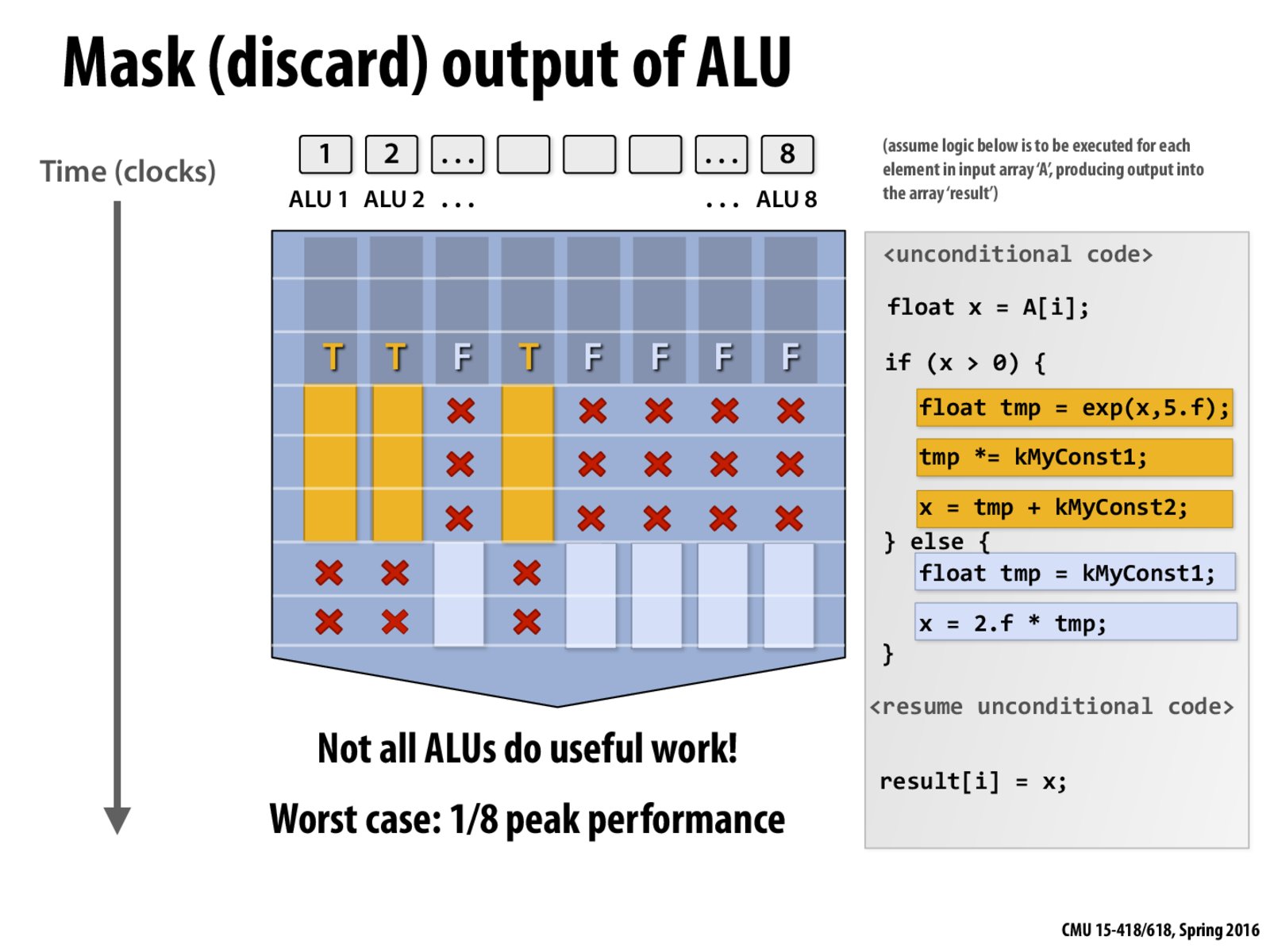
QUESTION:In what scenario exactly do we achieve 1/8 peak performance? And what do we mean here by saying peak performance?
When one branch is significantly longer than the other branch and it is only executed in 1 of 8 ALUs, we will achieve approximately 1/8 peak performance. Because if we fully utilize the ALUs, we'll be using 8 out of 8 ALUs rather than 1 out of 8. I think peak performance can be viewed as utilization rate.
It seems that we can avoid conditional branching in certain cases by using sign bits:
In practice, are there any benefits for using the non-branching version of the code?
@dhua I'm not sure that we would benefit from using sign bits in that way, since we move from having useless ALU's to having computations that do the work of both functions f1 and f2. In terms of the above graph, the vertical height of each column would still be the same, except that now the return values for all the ALU's will matter and we will need additional post-processing.
@dhua, branches are necessary since functions(or instructions in different branches) will have effects, such as memory operation or exceptions, and executing both of them will alter the meaning of the program.
On a separate note, it was interesting to learn that SIMDs have shared instruction streams while multicores can do different sets of instructions. I actually was curious to know, can we calculate how much longer the code block needs to be in one branch in order to reach a certain peak performance?
I agree with jerryzh that peak performance can be viewed as utilization rate. Suppose there are two branches, the first one runs in $a$ clocks while the second one runs in $b$ clocks. And there are $x$ elements go to the first branch while there are $y$ elements go to the second one. The the utilization rate is : $$ \frac{ax+by}{8(a+b)} $$ When y = 1, that is, when there is only one element goes to branch two, the utilization rate is: $$ \frac{ax+b}{8(a+b)} = \frac{\frac{a}{b}x+1}{8(\frac{a}{b}+1)} $$ If $b \gg a$, the right hand side is approximately $\frac{1}{8}$. This is the situation that only one element of input goes to the second branch and the execution time of the this branch is much longer than another one.
@monkeyking Thanks for the formalization of utilization!
An easy way to understand the fraction $\frac{ax+by}{8(a+b)}$ above: Imagine each clock of each ALU as a cell in a matrix. In total there are $8(a+b)$ such cells, and the ones put into use are $a$ runs of Branch A and $b$ runs of Branch B, totaling to $(ax+by)$ units of work.
Thus, the util rate is as given above.
Is this still SIMD? I think SIMD is just a technique to decode once and process multiple data. And "decode" here means decoding a single instruction. However, in this case, the SIMD seems able to decode multiple instructions at the same time (because ALUs are doing different instructions).
I think it is possible to use SIMD instruction and output a vector if 1s and 0s based on the conditional and take the correct output based on the vector. This way, all the ALUs will be doing useful work all the time (smilier to a mask).
@arcticx, I'm under the impression that it's still SIMD, because all ALUs execute the same instructions, but here's the catch: if an ALU is executing instructions that don't apply to its particular element (e.g., say, in the diagram, ALU 3 is executing code for the if branch, whereas it actually wants to execute code from the else branch), then its output is masked / ignored. In this way, all ALUs are executing the same instruction stream, but the results of certain instructions are ignored when they are not applicable. I believe Kayvon says in lecture that the compiler is responsible for applying the masks in the right place to guarantee correctness.
@kipper correct.
@arctix, check out the ISPC user's guide here which explains how the compiler uses masks when executing if statements:
"...the program counter steps through the statements for both the "true" case and the "false" case, with the execution mask set so that no side-effects from the true statements affect the program instances that want to run the false statements, and vice versa.
However, a block of statements does not execute if the mask is "all off" upon entry to that block. The execution mask is then restored to the value it had before the if statement."
note the optimization of not executing a block of statements if the mask is all off for that block.
I think it makes more sense to refer it as Peak Utilization than Peak Performance, since the performance of a program is intuitively limited by the structure of program itself
The performance of SIMD instructions highly depends on the type of input being processed. If a larger chunk of the instructions is executed by only one ALU then we will have very poor utilization of resources. Thus, it is the programmer's job to write a program that ensures the resources will be utilized, either by distributing instructions between both if and else blocks evenly, or by making sure the input isn't skewed in a way that creates the worst-case scenario.