Why caches also provide high bandwidth data transfer to CPU?
hofstee
@monkeyking because they are on the same die as the CPU. Memory is connected to the CPU via a bus (usually 240-pin or so) and isn't terribly fast (~12GB per chip of DDR3). Since the caches are on the same silicon as the chip, we get to bypass all the overhead of talking to DDR3, and instead have our much smaller overhead of however we manage the cache. On the core i7/Xeon 5500 series, an L1 cache hit was ~4 cycles. At 3.2GHz that is (3.2GHz/4cycles*64 bytes) = 0.41Tb/s or roughly 50GB/s per core. Modern CPUs are faster still. On an FPGA if you use onboard block RAMs you can hit transfer rates in the range of a couple TB/s.
Running a quick test on the machines we're using I get around 165 GB/s memory bandwidth from the L1 cache when reading data with 8 threads, and roughly 1 cycle of latency.
vincom2
@hofstee how does one run such tests?
hofstee
I just did this by creating an array small enough to fit entirely in L1, spawning some pthreads and reading the memory several times and timing the total amount. Varying thread counts, data sizes, and repetitions will give you enough data points that you can plot them and see general trends. In my case there was a dead flat line at 165GB/s using 8 threads over 50 tests of varying data sizes. There are a number of benchmarking suites that you could probably find as well.
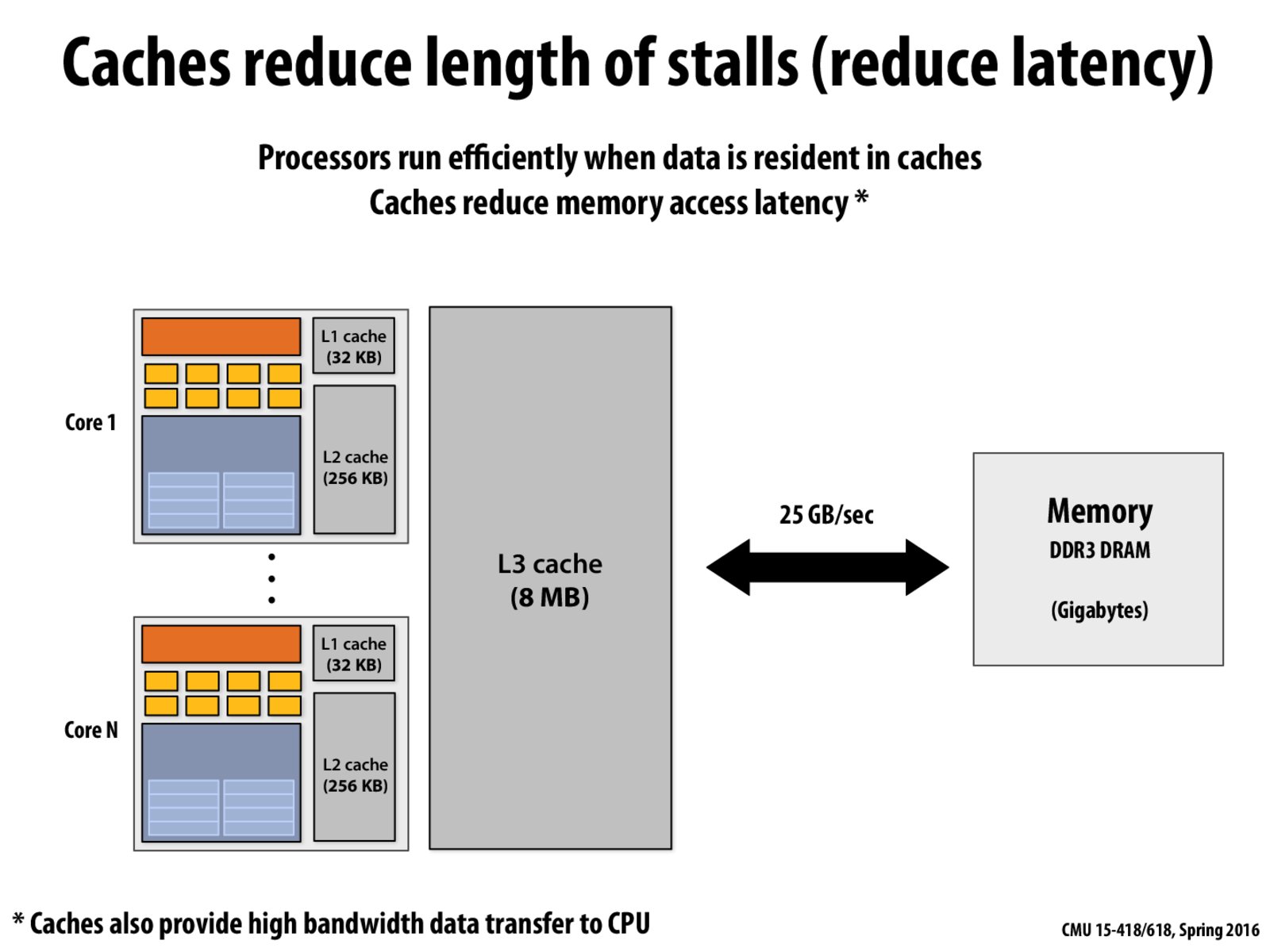
Why caches also provide high bandwidth data transfer to CPU?
@monkeyking because they are on the same die as the CPU. Memory is connected to the CPU via a bus (usually 240-pin or so) and isn't terribly fast (~12GB per chip of DDR3). Since the caches are on the same silicon as the chip, we get to bypass all the overhead of talking to DDR3, and instead have our much smaller overhead of however we manage the cache. On the core i7/Xeon 5500 series, an L1 cache hit was ~4 cycles. At 3.2GHz that is (3.2GHz/4cycles*64 bytes) = 0.41Tb/s or roughly 50GB/s per core. Modern CPUs are faster still. On an FPGA if you use onboard block RAMs you can hit transfer rates in the range of a couple TB/s.
Running a quick test on the machines we're using I get around 165 GB/s memory bandwidth from the L1 cache when reading data with 8 threads, and roughly 1 cycle of latency.
@hofstee how does one run such tests?
I just did this by creating an array small enough to fit entirely in L1, spawning some pthreads and reading the memory several times and timing the total amount. Varying thread counts, data sizes, and repetitions will give you enough data points that you can plot them and see general trends. In my case there was a dead flat line at 165GB/s using 8 threads over 50 tests of varying data sizes. There are a number of benchmarking suites that you could probably find as well.