How does the scheduler determine when each thread can run? Does it continuously ping the thread?
Funky9000
If all the work is done on a single thread, there could be multiple instances of stalling, thereby increasing overall time to complete the task compared to when utilizing multiple threads. Am I wrong to think that multi-threading does somewhat speeds up completion of a task?
Fantasy
Is granularity the main difference between multi-threading in a processor and context-switch in Operating System?
As I understand, the four threads in interleaved processing can be four different instructions streams (four different programs). When the OS notice a page-fault, it will do the context switch. (coarse grained) However, even if the data is in memory, the latency is still high when retrieving from main memory compared to retrieving from cache. Then, processor will do the interleaving among programs. (fine grained) Is that correct?
BensonQiu
What is the overhead of switching to a different instruction stream when faced with stall?
Khryl
@Funky9000, I think you are right about multi-threading speeds up completion of a task. Because as illustrated in class, multi-threading can utilize the time slots of stall to do other things useful towards finishing the task. It's just that compared to running a single thread(doing part of the work of the task) on the core, the completion of that thread may be delayed since the core may be occupied with other threads.
temmie
@kayvonf In lecture, you posed the question of whether interleaving processes or allowing each process to run (even with stalling) was faster per process or not. A student made an argument that one was "faster," which you corrected even though it was actually the right answer for the way you had stated the question--it's in the video around 1:10:00. (Yeah, I know this is nitpicky and you acknowledged that her reasoning was correct regardless, but I want vindication for raising my hand to "faster" too... :P)
As you both explained, with processes that can stall, non-interleaving will be faster per process because a non-interleaving approach resumes execution as soon as the program can be run again, while an interleaving approach will be busy with another process at that time and only return to the original when it hits another stall. But interleaving will typically be faster overall because we can fill some of the stalled time with work on other processes.
FarmerScrub
@potay I believe that the CPU has a list or queue of threads that are ready to run. After the old thread has the data needed, it will be listed as ready to run.
Does the threads in this core necessary needed to be in the same process? I am asking this question because I was wondering if the threads share a common TLB or have different TLB in their individual context.
arcticx
I think what @Fantasy asks is whether the 4 threads of the same core can belong to different process. My conjecture is yes, since
different threads have different context and maintain their own PC (I think the Fetch/Decode step will be repeated for each different thread)
it makes no sense that a single-threaded program will occupy a core all the time.
But what's the difference between this "thread" and the thread controlled by OS?
bojianh
@arcticx: Then each context will have to contain different %cr3 values?
arcticx
@bojianh my conjecture is yes. Haven't found and proof though.
Fantasy
@arcticx
Thanks!
To clarify my questions:
1. Can the four threads in the picture above come from different processes?
2. Are there any other differences between interleaving threads when reading from main memory and context switching when reading from disk? (except for memory vs disk)
3. Are there any other reasons to trigger threads interleaving other than hiding latency of reading from main memory?
grarawr
I think in class we talked about hiding stalls. Are there any systems/ is it possible to decrease stalls rather than just hiding it?
418_touhenying
@BensonQiu Probably the time to save/restore all necessary registers, tweak a bit of process/thread control blocks, and flush the necessary pipelines/buffers.
vincom2
@potay that sounds like it would be horribly inefficient - I would suspect something like every blocked-on-IO thread causing an interrupt to be raised whenever its IO operation completes?
memebryant
As a side note, I think the implementation of hardware threads wasn't made at all clear in lecture and is causing a lot of confusion. I'm not 100% sure that my view of them is correct, but...
It should be noted that these hardware threads likely appear as distinct cores to the operating system, with all the capabilities that brings, and context switching occurs between them without the operating system being involved. The OS can still schedule as it desires, but the hardware thread interleaving will be much finer grained and invisible.
Thinking about how tcbs, pagetables, and scheduling work via the operating system is not relevant to these threads, as the OS doesn't know that they aren't physical cores. A simple way to justify this is to consider the "stall time" of a memory access - say 1000 cycles (rather high). For the OS to be involved, in 1000 cycles, the hardware would need to throw an interrupt, be handled by the OS (perhaps 50 cycles), go through scheduling and context switching (easily 1000 cycles for a simple scheduler), save and restore some system state (perhaps another 100 cycles), and do a bit more control flow. Now we see that we'd need to do >1000 cycles to switch to thread B after thread A stalls for 1000 cycles, and we haven't even considered the cost of switching back to thread A!
It's very likely that there is some cost to switching which hardware thread is running, but I'd expect it to be <50 cycles based on the above math. If it were in the hundreds of cycles, it probably wouldn't be worth it for a stall on memory access. This also likely implies that each thread has its own branch predictor, pipelines, and all that other magical stuff for making code run faster, as that's probably too slow to save and restore constantly.
As mentioned above, I am not certain that this is correct as lecture wasn't overly clear on this topic, but it matches what I know about the relevant hardware and seems to mesh with the info given by @kayvonf.
PIC
This seems like it would only be useful for certain applications. How big is the overhead of "context switching" between hardware threads? If a thread doesn't have any cache misses for a while does that mean that the "other thread" doesn't get to run? Can this cause visible latency? Are there extra interrupts to ensure that each thread gets to run an equitable amount?
memebryant
Yes! There are applications where threading like this will be slower than only exposing a single core.
The hardware has some method to schedule the threads such that they run for about equal times. In particular, they may be able to run at the same time if they need different logic units, not just when one is stalled.
I don't believe this scheduling system should cause any interrupts, but I'm not a hardware guy.
If I'm getting this correctly, this method would potentially cause the processing time for each process to increase, while enhance the performance of the entire system, is that correct? This seems like a great way to increase the efficiency of the system, however how would the processor presume fairness between processes on a hardware level? I find this a very difficult task, since to reach maximum efficiency we would want very detailed spec of each process, but getting a thorough analysis would cost us a large overhead. Perhaps this will be covered later in the course.
ojd
There's another issue here which has become less of an issue recently, but still matters to some degree. With early implementations of hyperthreading, the L1 cache was shared. Newer cores have separate L1 caches for each thread, but the L2 cache is still shared. This can result in programs running on separate threads on the same core to have even worse thrashing than normal if both threads have a lot of memory traffic since each thread would have more cache misses than they would have had otherwise. There's also the issue of interrupts messing with the cache. From what I've heard, it's common to carefully manage thread affinity to ensure that the threads aren't going to fight with each other and for certain latency critical systems, it's common to pin event/interrupt handling threads to cores separate from data processing threads. It's probably a lot easier to pull this off with something like the first generation Xeon Phi, though, where the interleaving behavior is a good bit more predictable.
mazacar8
I am still slightly confused as to what exactly a hardware thread is. Is it that there is a temporary override on the scheduling done by the OS? Because shouldn't the OS itself schedule a different thread to run in the event of a stall?
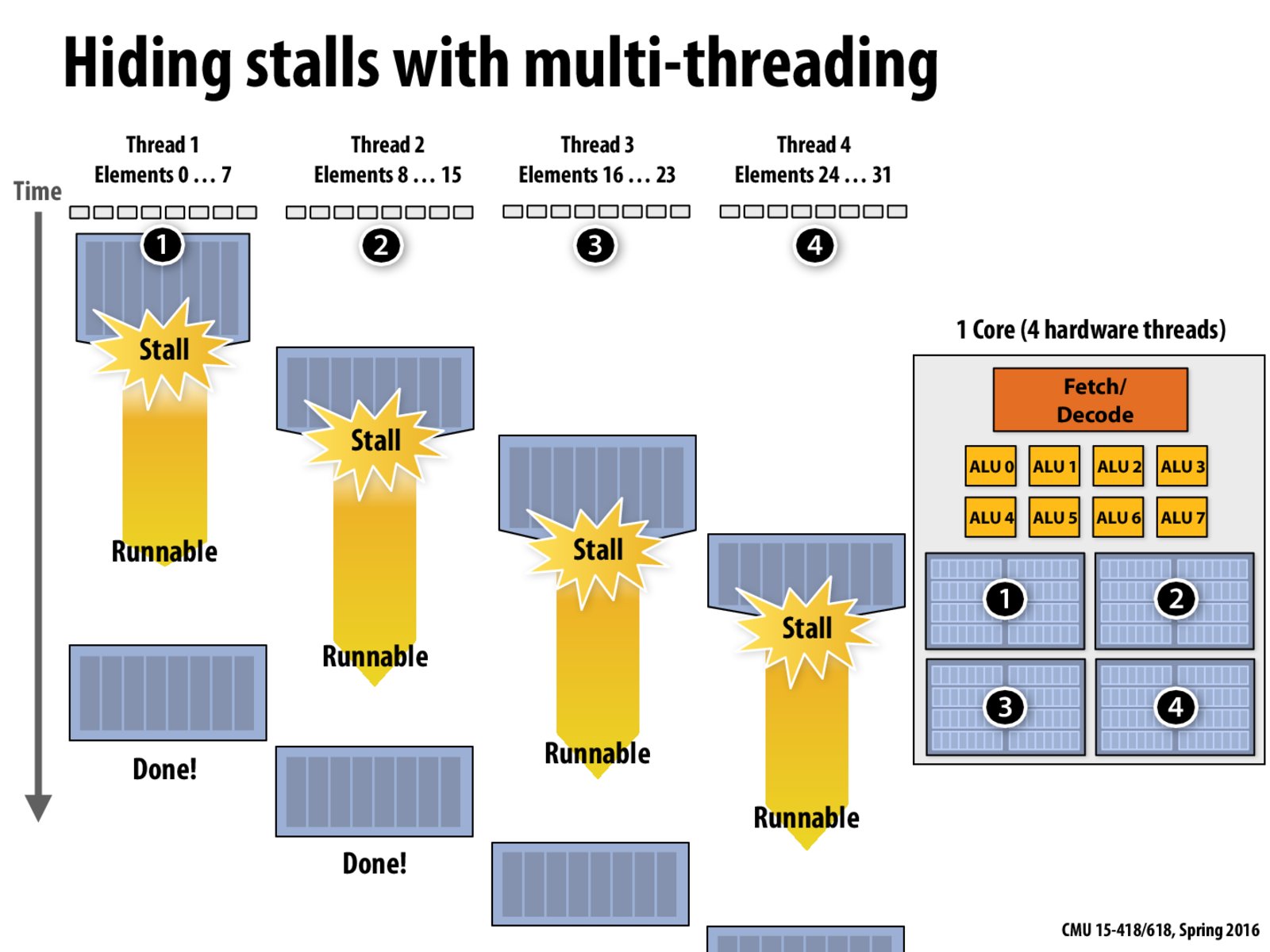
How does the scheduler determine when each thread can run? Does it continuously ping the thread?
If all the work is done on a single thread, there could be multiple instances of stalling, thereby increasing overall time to complete the task compared to when utilizing multiple threads. Am I wrong to think that multi-threading does somewhat speeds up completion of a task?
Is granularity the main difference between multi-threading in a processor and context-switch in Operating System?
As I understand, the four threads in interleaved processing can be four different instructions streams (four different programs). When the OS notice a page-fault, it will do the context switch. (coarse grained) However, even if the data is in memory, the latency is still high when retrieving from main memory compared to retrieving from cache. Then, processor will do the interleaving among programs. (fine grained) Is that correct?
What is the overhead of switching to a different instruction stream when faced with stall?
@Funky9000, I think you are right about multi-threading speeds up completion of a task. Because as illustrated in class, multi-threading can utilize the time slots of stall to do other things useful towards finishing the task. It's just that compared to running a single thread(doing part of the work of the task) on the core, the completion of that thread may be delayed since the core may be occupied with other threads.
@kayvonf In lecture, you posed the question of whether interleaving processes or allowing each process to run (even with stalling) was faster per process or not. A student made an argument that one was "faster," which you corrected even though it was actually the right answer for the way you had stated the question--it's in the video around 1:10:00. (Yeah, I know this is nitpicky and you acknowledged that her reasoning was correct regardless, but I want vindication for raising my hand to "faster" too... :P)
As you both explained, with processes that can stall, non-interleaving will be faster per process because a non-interleaving approach resumes execution as soon as the program can be run again, while an interleaving approach will be busy with another process at that time and only return to the original when it hits another stall. But interleaving will typically be faster overall because we can fill some of the stalled time with work on other processes.
@potay I believe that the CPU has a list or queue of threads that are ready to run. After the old thread has the data needed, it will be listed as ready to run.
Links:
Multithreading
Process State
Does the threads in this core necessary needed to be in the same process? I am asking this question because I was wondering if the threads share a common TLB or have different TLB in their individual context.
I think what @Fantasy asks is whether the 4 threads of the same core can belong to different process. My conjecture is yes, since
But what's the difference between this "thread" and the thread controlled by OS?
@arcticx: Then each context will have to contain different %cr3 values?
@bojianh my conjecture is yes. Haven't found and proof though.
@arcticx Thanks! To clarify my questions: 1. Can the four threads in the picture above come from different processes? 2. Are there any other differences between interleaving threads when reading from main memory and context switching when reading from disk? (except for memory vs disk) 3. Are there any other reasons to trigger threads interleaving other than hiding latency of reading from main memory?
I think in class we talked about hiding stalls. Are there any systems/ is it possible to decrease stalls rather than just hiding it?
@BensonQiu Probably the time to save/restore all necessary registers, tweak a bit of process/thread control blocks, and flush the necessary pipelines/buffers.
@potay that sounds like it would be horribly inefficient - I would suspect something like every blocked-on-IO thread causing an interrupt to be raised whenever its IO operation completes?
As a side note, I think the implementation of hardware threads wasn't made at all clear in lecture and is causing a lot of confusion. I'm not 100% sure that my view of them is correct, but...
It should be noted that these hardware threads likely appear as distinct cores to the operating system, with all the capabilities that brings, and context switching occurs between them without the operating system being involved. The OS can still schedule as it desires, but the hardware thread interleaving will be much finer grained and invisible.
Thinking about how tcbs, pagetables, and scheduling work via the operating system is not relevant to these threads, as the OS doesn't know that they aren't physical cores. A simple way to justify this is to consider the "stall time" of a memory access - say 1000 cycles (rather high). For the OS to be involved, in 1000 cycles, the hardware would need to throw an interrupt, be handled by the OS (perhaps 50 cycles), go through scheduling and context switching (easily 1000 cycles for a simple scheduler), save and restore some system state (perhaps another 100 cycles), and do a bit more control flow. Now we see that we'd need to do >1000 cycles to switch to thread B after thread A stalls for 1000 cycles, and we haven't even considered the cost of switching back to thread A!
It's very likely that there is some cost to switching which hardware thread is running, but I'd expect it to be <50 cycles based on the above math. If it were in the hundreds of cycles, it probably wouldn't be worth it for a stall on memory access. This also likely implies that each thread has its own branch predictor, pipelines, and all that other magical stuff for making code run faster, as that's probably too slow to save and restore constantly.
As mentioned above, I am not certain that this is correct as lecture wasn't overly clear on this topic, but it matches what I know about the relevant hardware and seems to mesh with the info given by @kayvonf.
This seems like it would only be useful for certain applications. How big is the overhead of "context switching" between hardware threads? If a thread doesn't have any cache misses for a while does that mean that the "other thread" doesn't get to run? Can this cause visible latency? Are there extra interrupts to ensure that each thread gets to run an equitable amount?
Yes! There are applications where threading like this will be slower than only exposing a single core.
The hardware has some method to schedule the threads such that they run for about equal times. In particular, they may be able to run at the same time if they need different logic units, not just when one is stalled. I don't believe this scheduling system should cause any interrupts, but I'm not a hardware guy.
@PIC I suspect you've seen this before (it was in a 410 lecture slide), but http://www.zdnet.com/article/hyperthreading-hurts-server-performance-say-developers/
If I'm getting this correctly, this method would potentially cause the processing time for each process to increase, while enhance the performance of the entire system, is that correct? This seems like a great way to increase the efficiency of the system, however how would the processor presume fairness between processes on a hardware level? I find this a very difficult task, since to reach maximum efficiency we would want very detailed spec of each process, but getting a thorough analysis would cost us a large overhead. Perhaps this will be covered later in the course.
There's another issue here which has become less of an issue recently, but still matters to some degree. With early implementations of hyperthreading, the L1 cache was shared. Newer cores have separate L1 caches for each thread, but the L2 cache is still shared. This can result in programs running on separate threads on the same core to have even worse thrashing than normal if both threads have a lot of memory traffic since each thread would have more cache misses than they would have had otherwise. There's also the issue of interrupts messing with the cache. From what I've heard, it's common to carefully manage thread affinity to ensure that the threads aren't going to fight with each other and for certain latency critical systems, it's common to pin event/interrupt handling threads to cores separate from data processing threads. It's probably a lot easier to pull this off with something like the first generation Xeon Phi, though, where the interleaving behavior is a good bit more predictable.
I am still slightly confused as to what exactly a hardware thread is. Is it that there is a temporary override on the scheduling done by the OS? Because shouldn't the OS itself schedule a different thread to run in the event of a stall?