Would it be possible to have multiple sizes of contexts on the same chip for different processes (i.e. two large ones for 'high priority' processes and two small ones for 'low priority' processes)? Furthermore, could you dynamically reallocate the same chunk of memory to more or fewer processes to deal with varying amounts of processes?
jhibshma
Dynamically allocating sounds like a cool idea @wcrougha. I'm sure it's possible, though if I recall correctly, the memory chunks are partitioned at the hardware level (is that true?); in that case, you might need a lot of hardware redesign.
I'm curious: What happens if, for example, we have just one of the cores shown above and we want to run 5 threads? Is one thread's context stored somewhere in an L2 cache? If so, does it get swapped out with another context before running?
PID_1
@jhibshma Yep, that's exactly what happens, it's called a context switch (https://en.wikipedia.org/wiki/Context_switch). The kernel keeps a track of the contexts for each running process/thread in a portion of RAM that is protected from access by user programs. But it is part of RAM, so it could end up in a hardware cache at some point. That's not a detail the kernel author would have to deal with manually.
To switch to a new process/thread, the kernel simply writes the existing context to memory and then loads up a stored one.
bysreg
Following up on @jhibshma & wcrougha,
In addition to the size, can context be split? so for jhibshma example, can the processor just create another context provided that there is enough unused space ?
skylake
IMO Designing a chip that allows dynamic allocation for contexts, or priority based allocation would make the chip rather complicated and thus they may not be the norm. However, if you remember the intel chip diagram - they had separate compute portions for Float, integer and load store operations. Thus designing separate contexts for various workloads/computations may not be tough. Yet, this would be a static rather than dynamic.
Need someone to help me know if this would work !!
hofstee
@skylake this is similar to how Hyper-threading works. At a very basic level it tries to group independent instructions in a way that will utilize as many of the resources at once as possible.
The separation between the compute and load/store is most likely for pipelining.
Dynamic allocation for contexts is certainly possible, but is also probably very logic heavy. I'm not sure if anybody does this (answer is probably they don't). Some older Intel processors had hardware support for context switching, and it would save all the general purpose registers, and only the general purpose registers, making it potentially more inefficient.
lol
What does a large context add over a small context?
The core data (PC, ESP, etc) should be same size. Is it thread local memory?
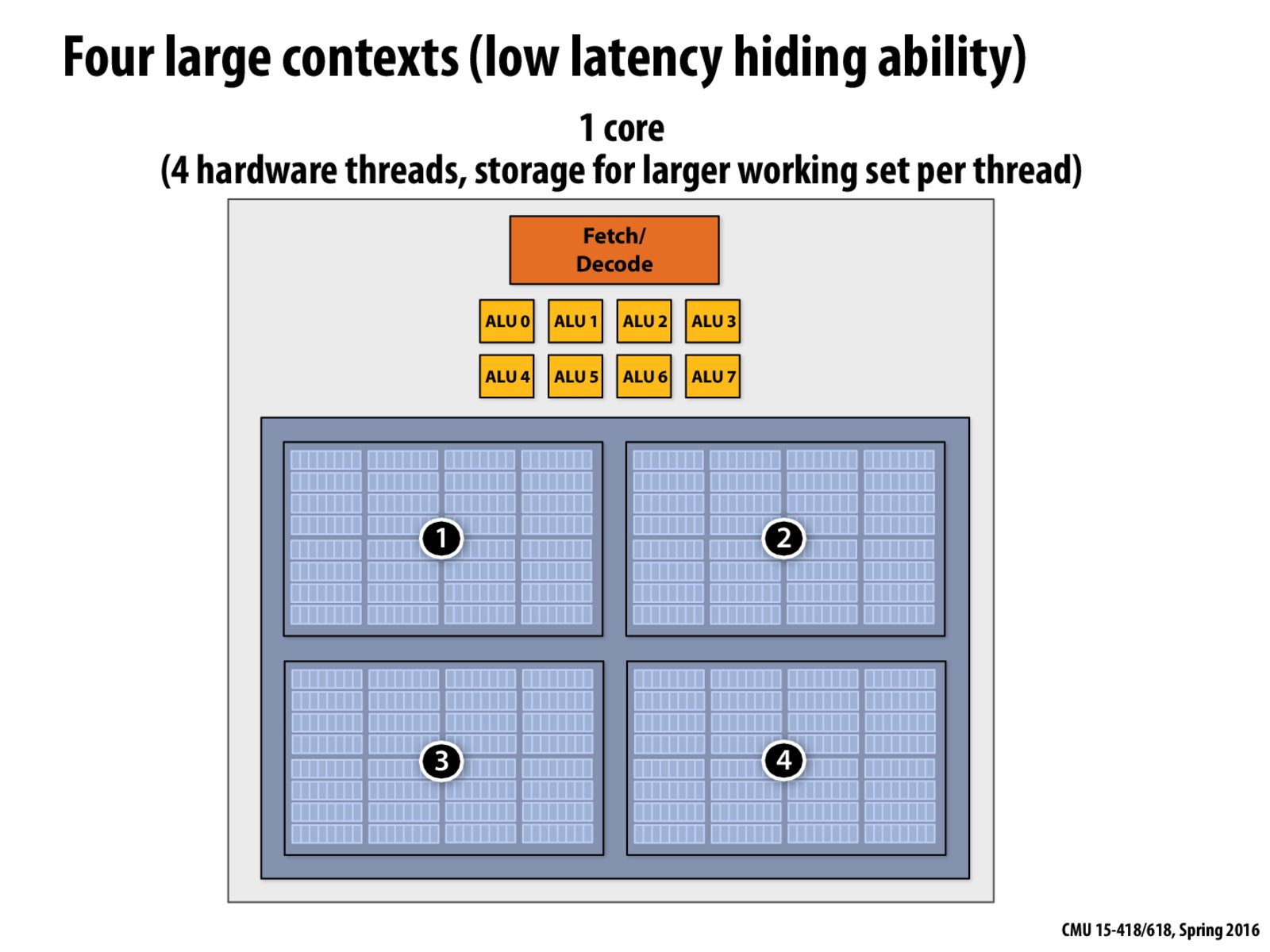
Would it be possible to have multiple sizes of contexts on the same chip for different processes (i.e. two large ones for 'high priority' processes and two small ones for 'low priority' processes)? Furthermore, could you dynamically reallocate the same chunk of memory to more or fewer processes to deal with varying amounts of processes?
Dynamically allocating sounds like a cool idea @wcrougha. I'm sure it's possible, though if I recall correctly, the memory chunks are partitioned at the hardware level (is that true?); in that case, you might need a lot of hardware redesign.
I'm curious: What happens if, for example, we have just one of the cores shown above and we want to run 5 threads? Is one thread's context stored somewhere in an L2 cache? If so, does it get swapped out with another context before running?
@jhibshma Yep, that's exactly what happens, it's called a context switch (https://en.wikipedia.org/wiki/Context_switch). The kernel keeps a track of the contexts for each running process/thread in a portion of RAM that is protected from access by user programs. But it is part of RAM, so it could end up in a hardware cache at some point. That's not a detail the kernel author would have to deal with manually.
To switch to a new process/thread, the kernel simply writes the existing context to memory and then loads up a stored one.
Following up on @jhibshma & wcrougha, In addition to the size, can context be split? so for jhibshma example, can the processor just create another context provided that there is enough unused space ?
IMO Designing a chip that allows dynamic allocation for contexts, or priority based allocation would make the chip rather complicated and thus they may not be the norm. However, if you remember the intel chip diagram - they had separate compute portions for Float, integer and load store operations. Thus designing separate contexts for various workloads/computations may not be tough. Yet, this would be a static rather than dynamic.
Need someone to help me know if this would work !!
@skylake this is similar to how Hyper-threading works. At a very basic level it tries to group independent instructions in a way that will utilize as many of the resources at once as possible.
The separation between the compute and load/store is most likely for pipelining.
Dynamic allocation for contexts is certainly possible, but is also probably very logic heavy. I'm not sure if anybody does this (answer is probably they don't). Some older Intel processors had hardware support for context switching, and it would save all the general purpose registers, and only the general purpose registers, making it potentially more inefficient.
What does a large context add over a small context?
The core data (PC, ESP, etc) should be same size. Is it thread local memory?