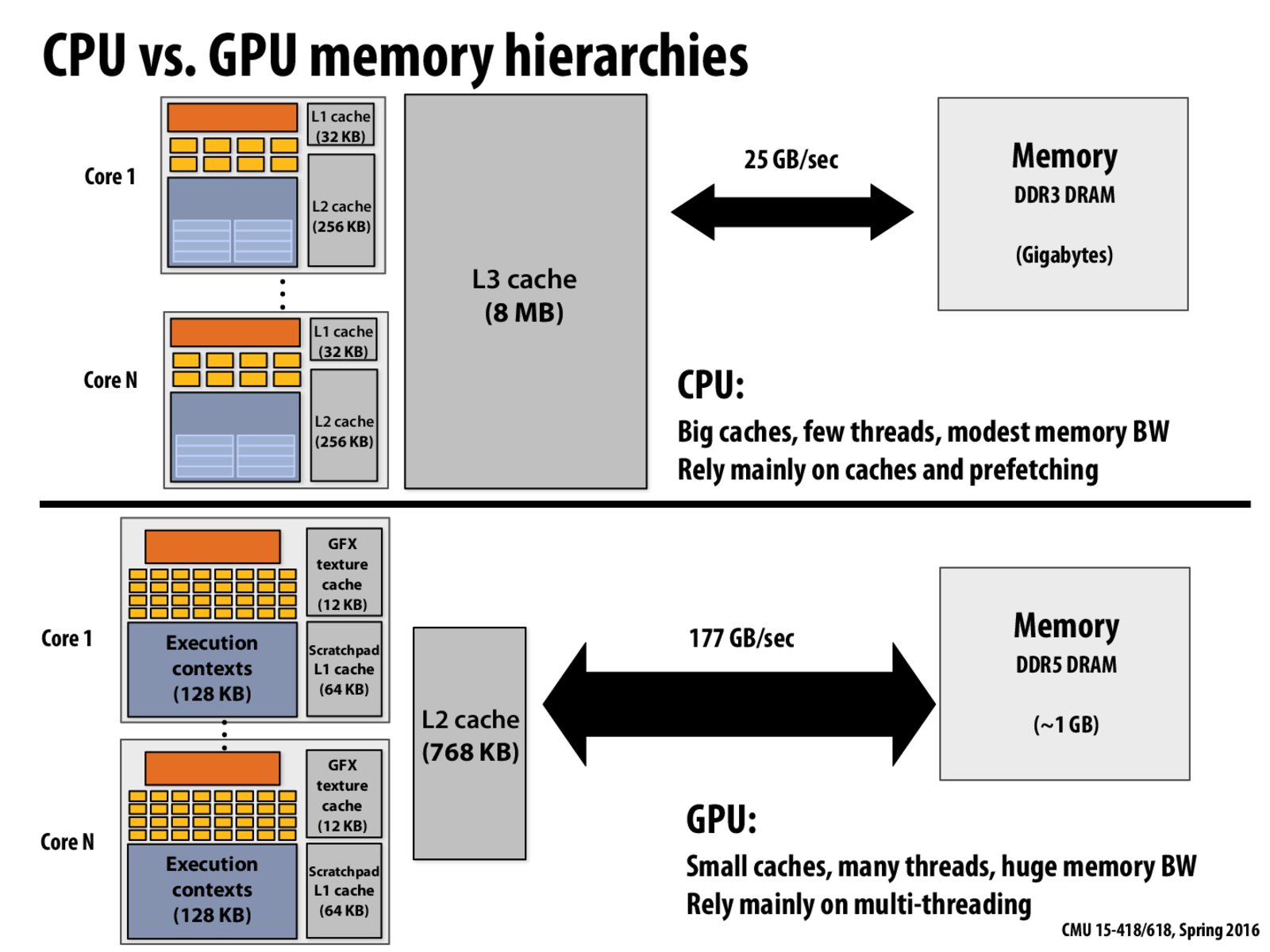
I don't think this was explicitly mentioned in lecture, but if you want more threads, you need more execution contexts, correct?
Also, is the number of threads a core can run limited by the number of execution contexts?
What exactly is stored in the execution context? Does it correspond to our idea of 'the stack' for separate threads?
Elmur_Fudd
We need more "execution contexts", but they don't necessary have to be stored on the chip. If you take a look at the tasks running on a PC, there are thousands of threads running at once. It's the responsibility of the operating system to store execution contexts of inactive threads (in memory, not on the chip) and switch them in and out of the processor when we want to run those threads.
PandaX
@0xc0ffee
Each threads correspond to an execution context to store register values, condition codes, etc. So the answer to the first question is YES.
However, like @Elmur_Fudd mentioned, execution contexts don't necessary have to be stored on the chip. You can think context storage as just another level of 'cache'. The execution contexts are actually stored in memory. So the answer to the second question is NO. The examples we are using is used to illustrate that if your context storage is big enough to hold more execution context, then you will have a better latency hiding ability.
Execution context stores register values, condition codes, etc.
Correct me if I am wrong.
krillfish
So, the more active threads we want running, the more physical execution contexts we need? Or can the threads still be active despite the number of execution contexts? (ETA: responded after Panda, so nvm)
I did a little bit of digging, and what I gleaned is that an execution context provides what a process or thread need at the minimum, so that probably means an address space, a stack, registers, etc.
zvonryan
Compared to CPU, GPU is often used in a less diversed and predictable manner, for example, we would typically have 32 threads working together in CUDA. Thus I think the memory accesses for GPU would be different from CPU. Then I learned about memory coalescing. This is intended for cutting down the number of memory accesses to elevate GPU performance.
I don't think this was explicitly mentioned in lecture, but if you want more threads, you need more execution contexts, correct?
Also, is the number of threads a core can run limited by the number of execution contexts?
What exactly is stored in the execution context? Does it correspond to our idea of 'the stack' for separate threads?
We need more "execution contexts", but they don't necessary have to be stored on the chip. If you take a look at the tasks running on a PC, there are thousands of threads running at once. It's the responsibility of the operating system to store execution contexts of inactive threads (in memory, not on the chip) and switch them in and out of the processor when we want to run those threads.
@0xc0ffee
Each threads correspond to an execution context to store register values, condition codes, etc. So the answer to the first question is YES.
However, like @Elmur_Fudd mentioned, execution contexts don't necessary have to be stored on the chip. You can think context storage as just another level of 'cache'. The execution contexts are actually stored in memory. So the answer to the second question is NO. The examples we are using is used to illustrate that if your context storage is big enough to hold more execution context, then you will have a better latency hiding ability.
Execution context stores register values, condition codes, etc.
Correct me if I am wrong.
So, the more active threads we want running, the more physical execution contexts we need? Or can the threads still be active despite the number of execution contexts? (ETA: responded after Panda, so nvm)
I did a little bit of digging, and what I gleaned is that an execution context provides what a process or thread need at the minimum, so that probably means an address space, a stack, registers, etc.
Compared to CPU, GPU is often used in a less diversed and predictable manner, for example, we would typically have 32 threads working together in CUDA. Thus I think the memory accesses for GPU would be different from CPU. Then I learned about memory coalescing. This is intended for cutting down the number of memory accesses to elevate GPU performance.
There are some useful links about this subject: Memory Coalescing Techniques, Situations Where Memory Coalescing Might Be Not Applicable