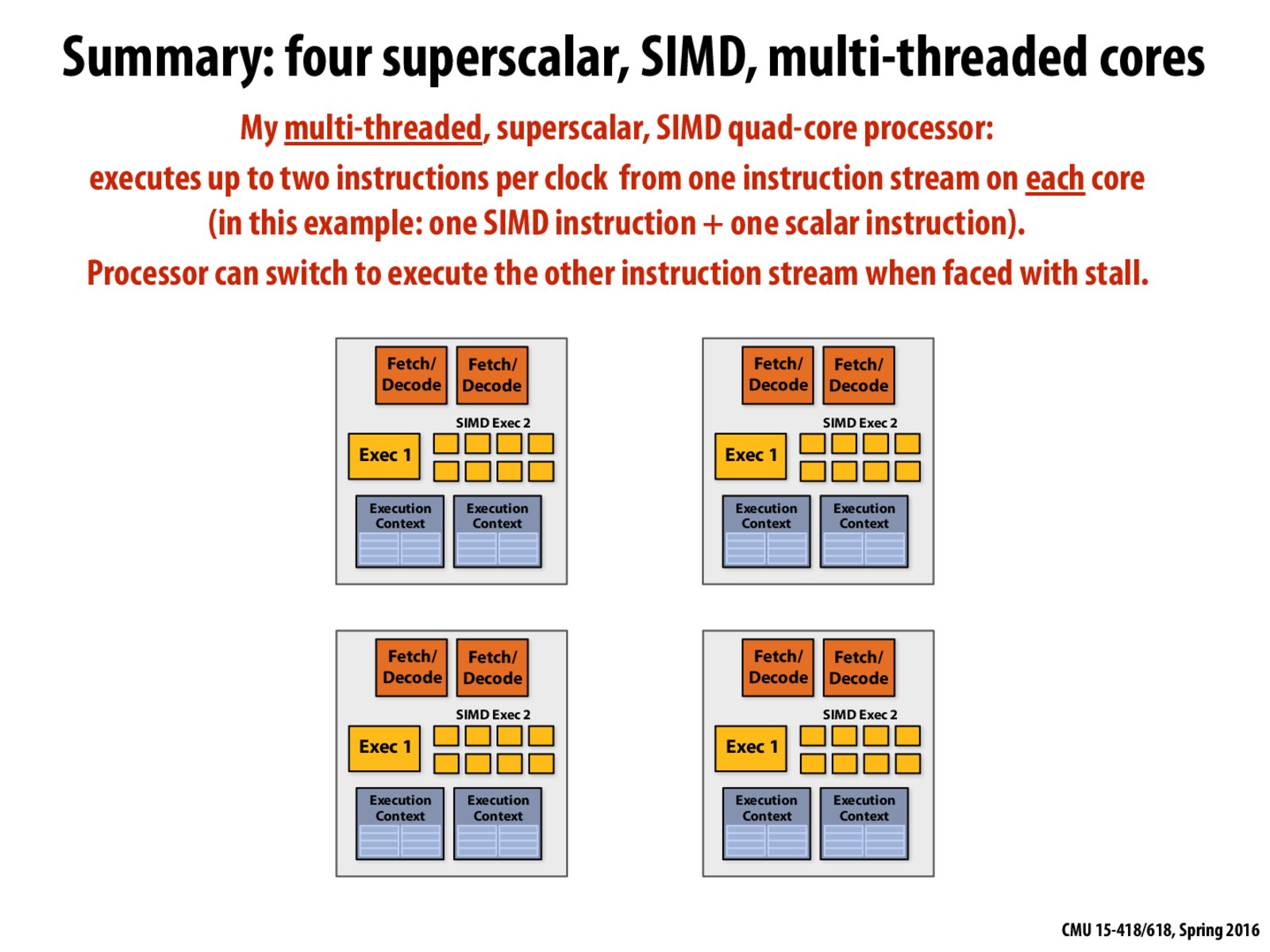
I guess in order to allow some context switching within the hardware (i.e. hardware-supported interleaving multi-threading), we need more than two sets of execution context per core, because the two functional units in each core already require two sets of context to operate.
vincom2
^ I think this is true; processors have extra sets of registers and the like so they can context switch between threads cheaply
Dracula08MS
I am assuming that Exec 1 is much more powerful than each of the Exec 2 units. However, Exec 1 can only execute 1 instruction at a time, whereas Exec 2 can perform SIMD executions. Is this correct?
mperron
@Dracula08MS I'm not 100% sure, but my guess is that they perform different kinds of operations. Consider the Pentium 4 diagram from slide 13. There are separate execution units for integer, floating point, and memory operations. It might not be a difference of "power" rather, it just does different stuff.
jsunseri
I noticed that the third bullet point at the top of the ISPC docs abbreviates "Single Program Multiple Data" as "SIMD" - is this intentional, or is it a typo? I could see it being intentional in this context, in that ISPC is mapping SPMD programs onto SIMD hardware. Thoughts?
jsunseri
Ok, I see this wasn't an abbreviation but was referring to the relationship between the abstraction (SPMD) and the implementation (SIMD) as shown in lecture 3, slide 17
huehue
If we only need to use a single instruction stream, is there any difference between using 2 cores with 1 fetch/decode, 1 execute, 1 execution context each vs. 1 core with 2 fetch/decode, 2 execute, 2 execution contexts?
doodooloo
@vincom2 After lecture 3, I realize my previous comment is not correct. If we are only able to use one ALU per core (like there is no SIMD instructions available), then we can have the context switching.
momoda
@Dracula08MS I don't think we should use "more powerful". The aim of this superscalar design is to execute SIMD instruction in parallel with none-SIMD instruction. The combination of these two different ALUs might be more efficient than only use two SIMD ALUs.
rmanne
A few important things to note here:
*) GCC can vectorize when passed in -ftree-vectorize (which is enabled by -O3
*) The Linux kernel compiles at -O2, because if for some reason, there was to be a lot of SIMD instructions used in the kernel, the kernel would end up competing for resources that it doesn't need and other processes, such as a video decoder, would benefit much more from the use of SIMD instructions.
*) In Matlab, using a parallel pool of a size equal to the number of threads you have on a HT processor, will make it take nearly twice as long to do the computation, because about half the time ends up being wasted on context switching, since both threads make use of the same type of Execution unit (whether this is the SIMD exec or not depends of the code).
Richard
Suppose we are using simultaneous multi-threading strategy on this processor. In each clock, up to 2 instructions can be executed (a SIMD one and a scalar one). These two instructions can come from: 1) the same thread; or 2) different threads. Am I right? In this case, these seems no "thread switching"...
I guess in order to allow some context switching within the hardware (i.e. hardware-supported interleaving multi-threading), we need more than two sets of execution context per core, because the two functional units in each core already require two sets of context to operate.
^ I think this is true; processors have extra sets of registers and the like so they can context switch between threads cheaply
I am assuming that Exec 1 is much more powerful than each of the Exec 2 units. However, Exec 1 can only execute 1 instruction at a time, whereas Exec 2 can perform SIMD executions. Is this correct?
@Dracula08MS I'm not 100% sure, but my guess is that they perform different kinds of operations. Consider the Pentium 4 diagram from slide 13. There are separate execution units for integer, floating point, and memory operations. It might not be a difference of "power" rather, it just does different stuff.
I noticed that the third bullet point at the top of the ISPC docs abbreviates "Single Program Multiple Data" as "SIMD" - is this intentional, or is it a typo? I could see it being intentional in this context, in that ISPC is mapping SPMD programs onto SIMD hardware. Thoughts?
Ok, I see this wasn't an abbreviation but was referring to the relationship between the abstraction (SPMD) and the implementation (SIMD) as shown in lecture 3, slide 17
If we only need to use a single instruction stream, is there any difference between using 2 cores with 1 fetch/decode, 1 execute, 1 execution context each vs. 1 core with 2 fetch/decode, 2 execute, 2 execution contexts?
@vincom2 After lecture 3, I realize my previous comment is not correct. If we are only able to use one ALU per core (like there is no SIMD instructions available), then we can have the context switching.
@Dracula08MS I don't think we should use "more powerful". The aim of this superscalar design is to execute SIMD instruction in parallel with none-SIMD instruction. The combination of these two different ALUs might be more efficient than only use two SIMD ALUs.
A few important things to note here:
*) GCC can vectorize when passed in -ftree-vectorize (which is enabled by -O3
*) The Linux kernel compiles at -O2, because if for some reason, there was to be a lot of SIMD instructions used in the kernel, the kernel would end up competing for resources that it doesn't need and other processes, such as a video decoder, would benefit much more from the use of SIMD instructions.
*) In Matlab, using a parallel pool of a size equal to the number of threads you have on a HT processor, will make it take nearly twice as long to do the computation, because about half the time ends up being wasted on context switching, since both threads make use of the same type of Execution unit (whether this is the SIMD exec or not depends of the code).
Suppose we are using simultaneous multi-threading strategy on this processor. In each clock, up to 2 instructions can be executed (a SIMD one and a scalar one). These two instructions can come from: 1) the same thread; or 2) different threads. Am I right? In this case, these seems no "thread switching"...