I have a question about this slide: why is it bad of "walking over B in large steps", given that the block size is chosen to let all three blocks reside in the cache?
c0d3r
I'm not entirely sure what "walking over B in large steps" means. But here's my intuition about this slide:
Although spacial locality is improved in B, we are still walking over A in tiny steps (i.e. using splat). It would be better to also vectorize the loads in A. Thus, the intuition is to restore A as A^T before the matrix multiplication (see next slide).
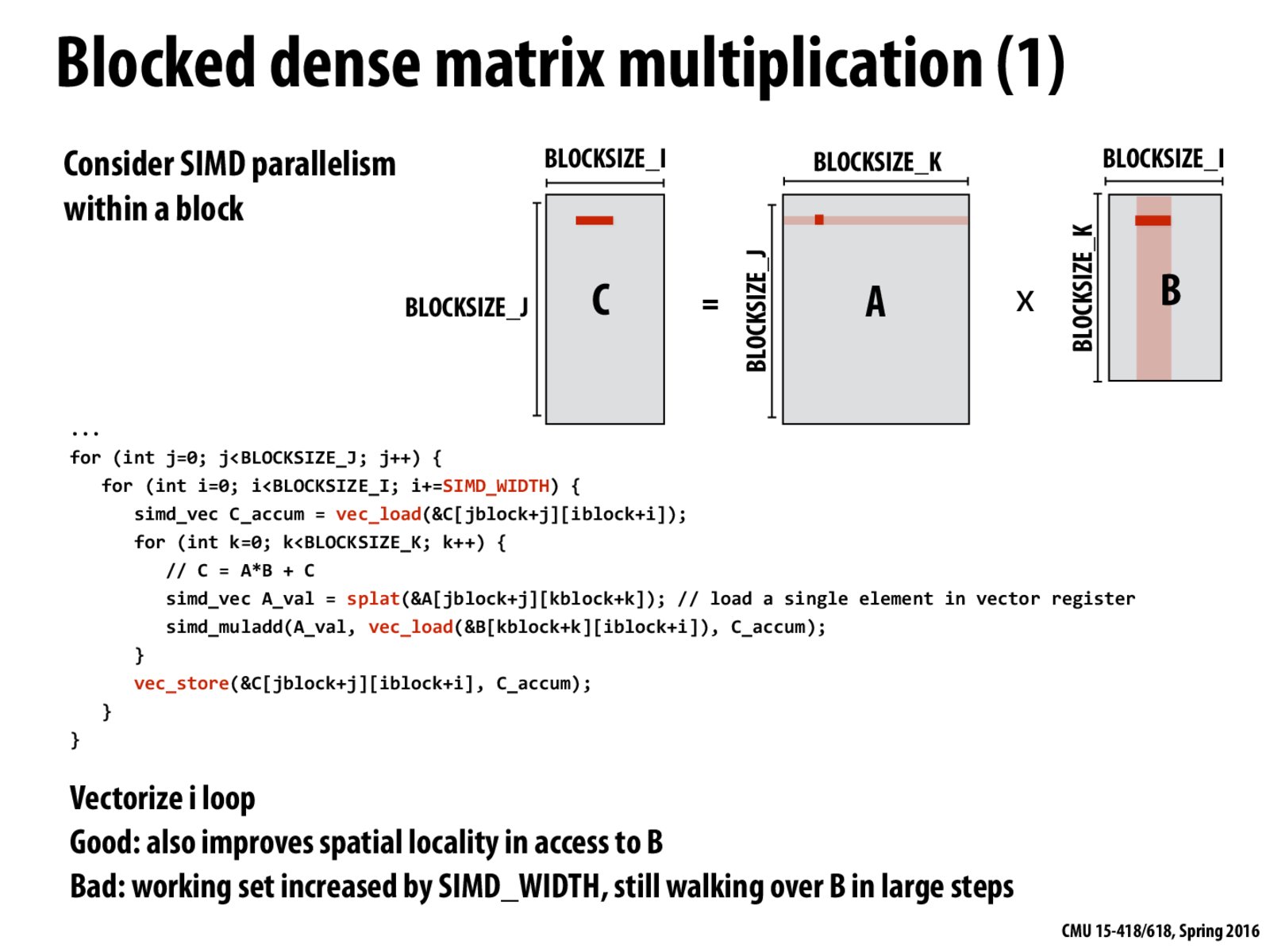
I have a question about this slide: why is it bad of "walking over B in large steps", given that the block size is chosen to let all three blocks reside in the cache?
I'm not entirely sure what "walking over B in large steps" means. But here's my intuition about this slide:
Although spacial locality is improved in B, we are still walking over A in tiny steps (i.e. using splat). It would be better to also vectorize the loads in A. Thus, the intuition is to restore A as A^T before the matrix multiplication (see next slide).