The negative outcomes about this approach is that it increases the amount of memory consumption and also decreases the arithmetic intensity by the large number of loads.
misaka-10032
Is it really an implementation of modern convolution, I guess not? I guess there would be some smarter indexing tricks?
maxdecmeridius
How would these matrices change as the "topography" of the neural network changes? Say, if the neural network was convolving sparse elements vs. dense elements.
c0d3r
@misaka-10032, I think that turning convolution into matrix multiplication and using the blocking method described in earlier slides would make this computation optimal. Is that what you meant by smarter indexing?
misaka-10032
@c0d3r I don't know actually. I just thought it's a waste of storage to make such an unrolled matrix. There might be some techniques that make better use of producer-consumer locality, and make a smaller intermediate matrix to do the convolution.
xingdaz
It is actually how caffe does it. https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo. The author was under a bit of a deadline and he decided to not be clever with the convolution and just use what is in the tool box.
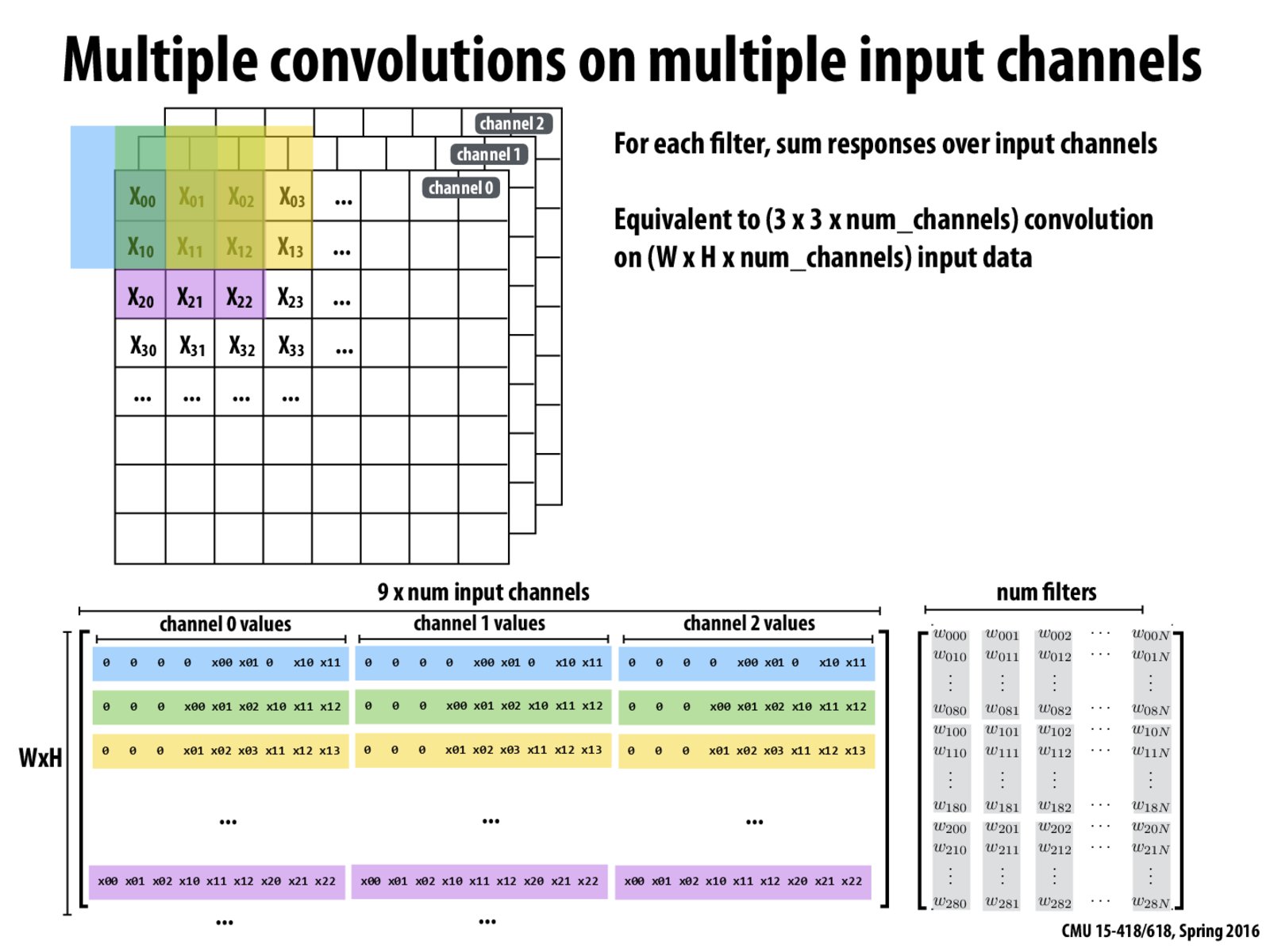
The negative outcomes about this approach is that it increases the amount of memory consumption and also decreases the arithmetic intensity by the large number of loads.
Is it really an implementation of modern convolution, I guess not? I guess there would be some smarter indexing tricks?
How would these matrices change as the "topography" of the neural network changes? Say, if the neural network was convolving sparse elements vs. dense elements.
@misaka-10032, I think that turning convolution into matrix multiplication and using the blocking method described in earlier slides would make this computation optimal. Is that what you meant by smarter indexing?
@c0d3r I don't know actually. I just thought it's a waste of storage to make such an unrolled matrix. There might be some techniques that make better use of producer-consumer locality, and make a smaller intermediate matrix to do the convolution.
It is actually how caffe does it. https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo. The author was under a bit of a deadline and he decided to not be clever with the convolution and just use what is in the tool box.