Can someone explain the middle part of left bottom figure. Why an automatically generated schedule without autotuning can beat a 3-day autotuning schedule? I don't think it is coincidence (for there are 3 days for tuning).
kayvonf
It's a tiny benchmark, so that's noise in measurement (the benchmark completes in a very small amount of time). The two data points would be the same if the measurement harness ran the two codes for longer. I cannot recall the specific measurement details but this slide shows preliminary results that were recorded via average (or min) of (I think) 5 runs.
dhua
Is the reason why the auto-scheduled versions of LOCAL_LAPLACIAN and CAMERA are worse than the human versions the same as the reason why the humans were able to beat the auto-scheduler in MAXFILTER on the next slide? (I.e. the auto-scheduler hasn't implemented an optimization that the human has done.)
I'm also curious about what the auto-scheduler did that makes LOCAL_LAPLACIAN run slower on 12 threads than it does on 6 theads.
randomized
Is the preprint of this paper available somewhere?
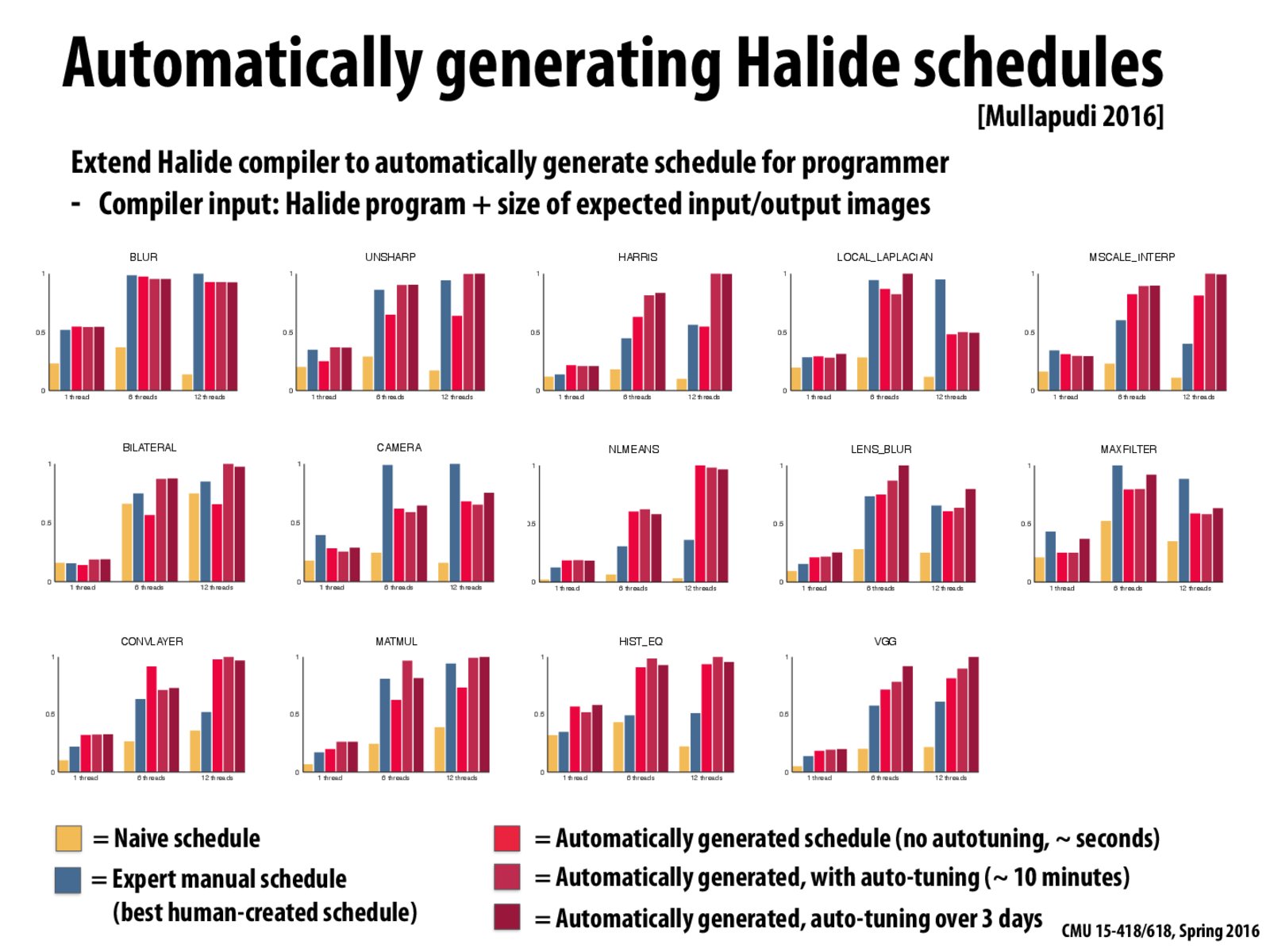
Can someone explain the middle part of left bottom figure. Why an automatically generated schedule without autotuning can beat a 3-day autotuning schedule? I don't think it is coincidence (for there are 3 days for tuning).
It's a tiny benchmark, so that's noise in measurement (the benchmark completes in a very small amount of time). The two data points would be the same if the measurement harness ran the two codes for longer. I cannot recall the specific measurement details but this slide shows preliminary results that were recorded via average (or min) of (I think) 5 runs.
Is the reason why the auto-scheduled versions of
LOCAL_LAPLACIANandCAMERAare worse than the human versions the same as the reason why the humans were able to beat the auto-scheduler inMAXFILTERon the next slide? (I.e. the auto-scheduler hasn't implemented an optimization that the human has done.)I'm also curious about what the auto-scheduler did that makes
LOCAL_LAPLACIANrun slower on 12 threads than it does on 6 theads.Is the preprint of this paper available somewhere?
Yes, it's now available here:
http://graphics.cs.cmu.edu/projects/halidesched/