Interestingly, the "threads" in CUDA are numbered in a two-dimensional space. This means that instead of being given a "threadID," they are given an x and y location corresponding to where they are with regards to the blocks and such.
In this example 72 threads are launched and in doing the calculation of i and j, the program is essentially specifying that each thread should perform the computation on that specific element in the matrix.
This is interesting because instead of simply doing a "for_all" as we did with ISPC, we are now only defining the behaviour of a single thread in the kernel (matrixAdd), and then telling the GPU to do this computation on all of the elements by calling it on a bunch of different threads.
As we'll see later in the lecture, the number of threads can far exceed the number of execution units on the chip and the chip will actually schedule tasks to get it done efficiently with the available resources.
kipper
@rohan, can you clarify what exactly it means that the threads have x and y dimensions? I don't really understand how it works.
the threads id in CUDA can be up to 3-dimensional. You can find relation between the index of a thread and its thread ID in chapter 2.2 in
CUDA C programming guide.
This multi-dimensional hierarchy provides a natural way to invoke computation across the elements in a domain such as a vector, matrix, or volume.
kayvonf
@momoda, @kipper: Not a big deal, but worth noting: it's also easier to convert a 2-D index (x,y) to a 1D (linearized) offset, than so the other way: convert a 1D index to 2D indices (x,y). The former (shown below) requires only adds and multiplies, the later would require a divide.
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int 1d_offset = y * IMAGE_WIDTH + x;
temmie
Why was 3 dimensions in particular chosen as the limit? Couldn't they have allowed for any finite number (well, within hardware limits) of dimensions on thread IDs? Did they just figure 3D would cover most applications?
kayvonf
@temmie. It's hardware supported, and everything in HW is finite. But yes, stopping at 3D was probably determined to be a reasonable idea since it covers a large space of applications, particularly those in graphics, where we work on 2D grids (images) and 3D grids (voxels in a volume).
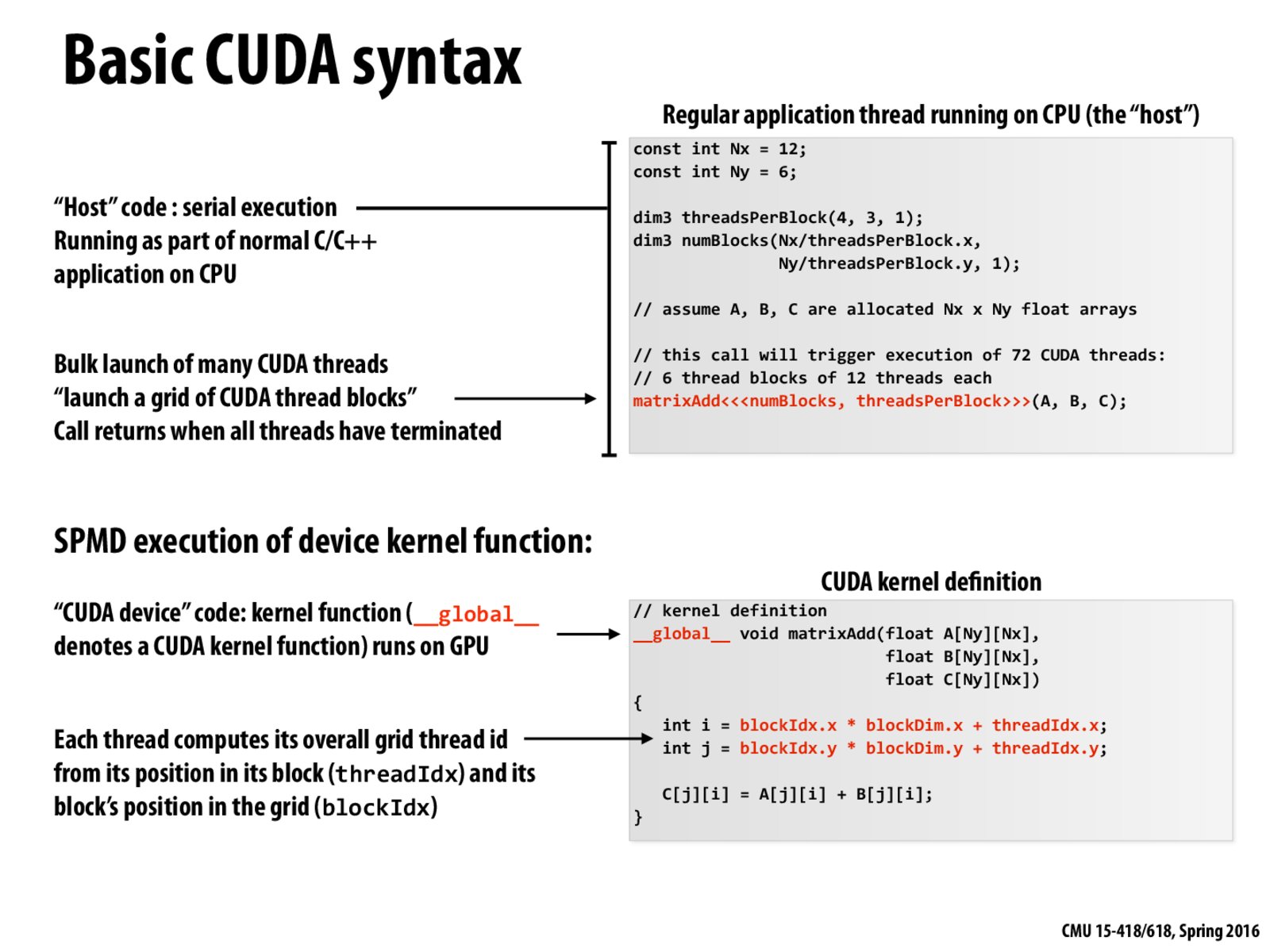
Interestingly, the "threads" in CUDA are numbered in a two-dimensional space. This means that instead of being given a "threadID," they are given an x and y location corresponding to where they are with regards to the blocks and such.
In this example 72 threads are launched and in doing the calculation of i and j, the program is essentially specifying that each thread should perform the computation on that specific element in the matrix.
This is interesting because instead of simply doing a "for_all" as we did with ISPC, we are now only defining the behaviour of a single thread in the kernel (matrixAdd), and then telling the GPU to do this computation on all of the elements by calling it on a bunch of different threads.
As we'll see later in the lecture, the number of threads can far exceed the number of execution units on the chip and the chip will actually schedule tasks to get it done efficiently with the available resources.
@rohan, can you clarify what exactly it means that the threads have
xandydimensions? I don't really understand how it works.@kipper. As shown in lecture 5, slide 37,
the threads id in CUDA can be up to 3-dimensional. You can find relation between the index of a thread and its thread ID in chapter 2.2 in CUDA C programming guide.
This multi-dimensional hierarchy provides a natural way to invoke computation across the elements in a domain such as a vector, matrix, or volume.
@momoda, @kipper: Not a big deal, but worth noting: it's also easier to convert a 2-D index (x,y) to a 1D (linearized) offset, than so the other way: convert a 1D index to 2D indices (x,y). The former (shown below) requires only adds and multiplies, the later would require a divide.
Why was 3 dimensions in particular chosen as the limit? Couldn't they have allowed for any finite number (well, within hardware limits) of dimensions on thread IDs? Did they just figure 3D would cover most applications?
@temmie. It's hardware supported, and everything in HW is finite. But yes, stopping at 3D was probably determined to be a reasonable idea since it covers a large space of applications, particularly those in graphics, where we work on 2D grids (images) and 3D grids (voxels in a volume).