Pretty crazy to think about what happens on the hardware as the program is running. Very cool that the CPU unpacks instructions to launch other instructions on the GPU.
kayvonf
@Oxc0ffee. Can you clarify. I'm not sure what you meant here?
monkeyking
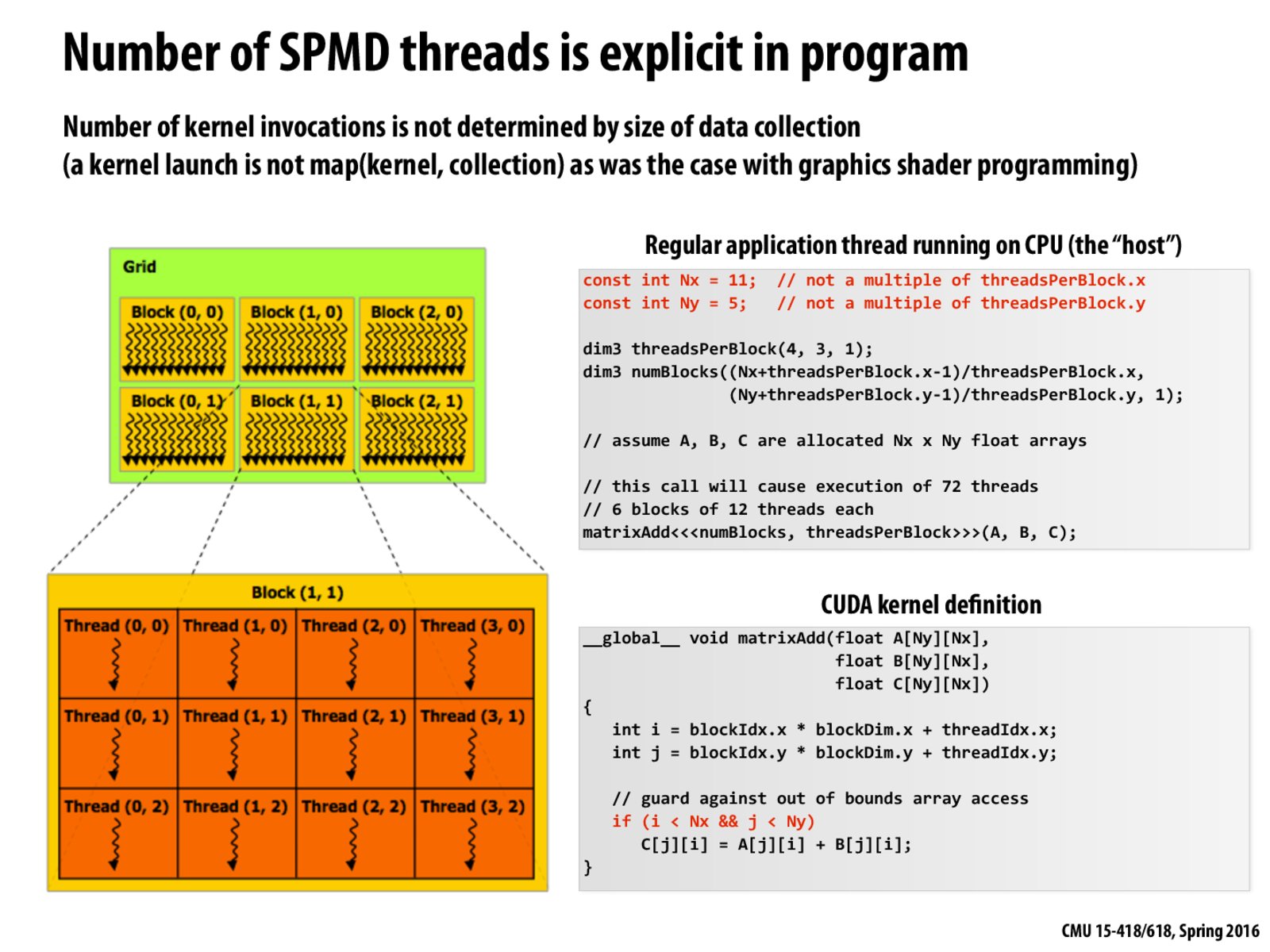
numBlocks is 2D and is (3,2), so there is a "block table" of 2 rows and 3 columns. Each cell of the "block table" is a "thread table". threadsPerBlock is also 2D and is (4,3). So the "thread table" is of 3 rows and 4 columns. We use the indices to "look up" in the "table". For example, in the program above, blockDim.x is always 4 and blockDim.y is always 3 (In my opinion, the blockDim is the dimension of threads the block, which is the dimension of the "thread table"). When blockIdx.x = 1, threadIdx.x = 1 and blockIdx.y = 1, threadIdx.y = 1, i.e. Thread(1,1) in Block(1,1), i = 1 * 4 + 1 = 5, j = 1 * 3 + 1 = 4. So we are accessing item C[4][5].
Besides, the maximum value of i is 2 * 4 + 3 = 11 and the maximum value of j is 1 * 3 + 2 = 5. That's why we need to use that "if" clause to guard against out of bounds array access.
teamG
adding on to what monkeyking said, when working on assignment 2, I see that when coding in CUDA, we can essentially treat the highlighted if statements as a loop guard, like we would embed information about the indices that want to look at in the if statement, including the starting index, ending index, and the "afterthought", like how are we modifying the index that we are looking at as we are running the for loop.
418_touhenying
So is it that, the width and height of the 2d array is arbitrary (it's the input), but the number of blocks per grid and the number of threads per block are internal features of the GPU?
Pretty crazy to think about what happens on the hardware as the program is running. Very cool that the CPU unpacks instructions to launch other instructions on the GPU.
@Oxc0ffee. Can you clarify. I'm not sure what you meant here?
numBlocks is 2D and is (3,2), so there is a "block table" of 2 rows and 3 columns. Each cell of the "block table" is a "thread table". threadsPerBlock is also 2D and is (4,3). So the "thread table" is of 3 rows and 4 columns. We use the indices to "look up" in the "table". For example, in the program above, blockDim.x is always 4 and blockDim.y is always 3 (In my opinion, the blockDim is the dimension of threads the block, which is the dimension of the "thread table"). When blockIdx.x = 1, threadIdx.x = 1 and blockIdx.y = 1, threadIdx.y = 1, i.e. Thread(1,1) in Block(1,1), i = 1 * 4 + 1 = 5, j = 1 * 3 + 1 = 4. So we are accessing item C[4][5]. Besides, the maximum value of i is 2 * 4 + 3 = 11 and the maximum value of j is 1 * 3 + 2 = 5. That's why we need to use that "if" clause to guard against out of bounds array access.
adding on to what monkeyking said, when working on assignment 2, I see that when coding in CUDA, we can essentially treat the highlighted if statements as a loop guard, like we would embed information about the indices that want to look at in the if statement, including the starting index, ending index, and the "afterthought", like how are we modifying the index that we are looking at as we are running the for loop.
So is it that, the width and height of the 2d array is arbitrary (it's the input), but the number of blocks per grid and the number of threads per block are internal features of the GPU?