I believe what this slide is saying is that a scheduler assigns blocks to a core on the GPU. Each block is independent from each other, so the order at which they are run doesn't matter. This is different from the example on slide 73, where the threads are running on the same block block and thus the threads can depend on each other.
PandaX
The task assignment of CUDA program is done by hardware;
The task assignment of pthreads is done by operating system;
The task assignment of ISPC program is done by compiler;
qqkk
In one kernel function, a number of blocks of threads are invoked in random order. There's no way to synchronize between blocks in one kernel function. Any kernel function that needs synchronization between blocks should be split into multiple kernel functions.
kayvonf
@pandaX: I'd be careful here. What do you mean by task?
The mapping of CUDA thread blocks to GPU hardware resources is performed by a hardware scheduler.
The mapping of pthreads to CPU hardware execution resources is done by the OS.
The mapping of ISPC program instances to lanes in vector instructions is performed by the ISPC compiler.
I would also say the assignment of work (tasks, processing of grid elements, etc.) to CUDA threads, pthreads, etc. is typically done by the program.
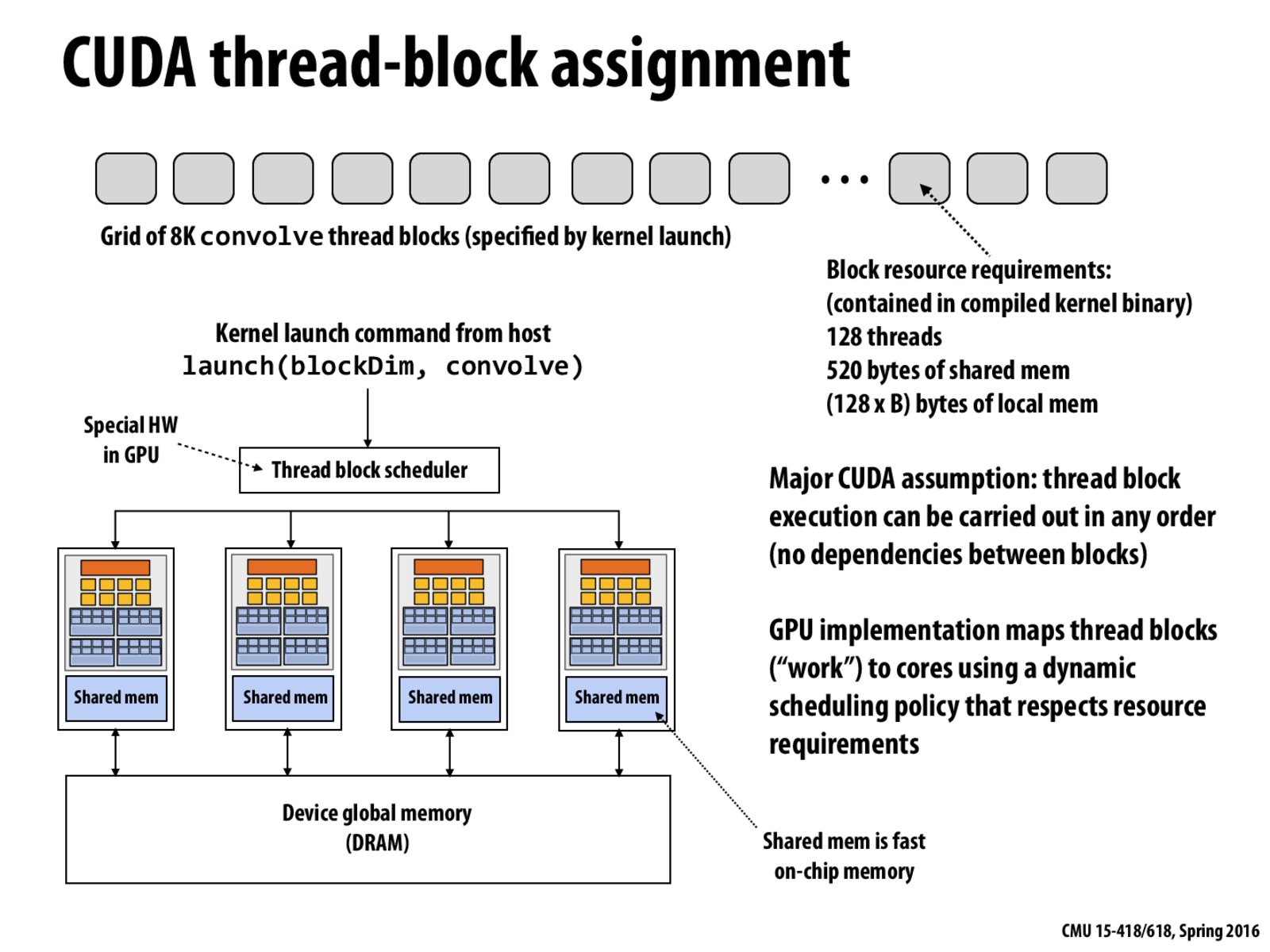
I believe what this slide is saying is that a scheduler assigns blocks to a core on the GPU. Each block is independent from each other, so the order at which they are run doesn't matter. This is different from the example on slide 73, where the threads are running on the same block block and thus the threads can depend on each other.
The task assignment of CUDA program is done by hardware;
The task assignment of pthreads is done by operating system;
The task assignment of ISPC program is done by compiler;
In one kernel function, a number of blocks of threads are invoked in random order. There's no way to synchronize between blocks in one kernel function. Any kernel function that needs synchronization between blocks should be split into multiple kernel functions.
@pandaX: I'd be careful here. What do you mean by task?
I would also say the assignment of work (tasks, processing of grid elements, etc.) to CUDA threads, pthreads, etc. is typically done by the program.