There is a slide that intuitively shows how gather, apply, scatter works in GraphLab, as well as GraphChi. The way GraphChi deals with the problem that the edge list cannot fit into memory is exactly like the sharding talked about in this class. In GraphiChi, different shards are processed in parallel. The sliding window in GraphChi stands for the sequential disk access required for processing each shard.
totofufu
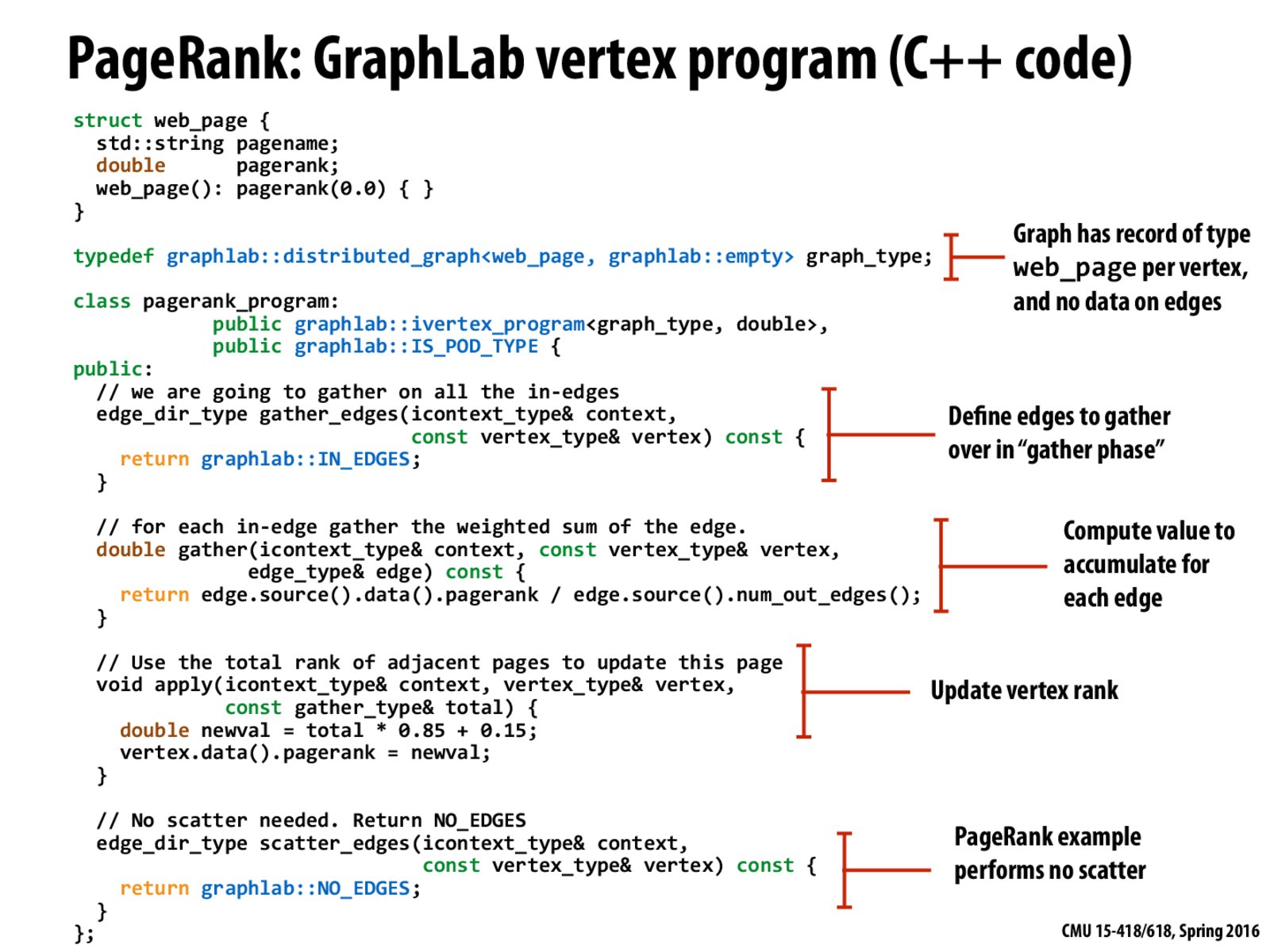
What is the high-level idea behind having two functions (gather and apply) to update the new vertex rank?
CC
@totofufu I think gather calculates the weighted sum of each in-edge that is selected by gather_edges, and then apply sums all the values from gather and produce a new rank score for the vertex.
As opposed to most graph libraries that are called by the user program. It is noted in lecture that GraphLab is a framework that is running at top-level, and calls the user-defined operations to complete computation.
momoda
In "Update vertex rank" function, why isn't 0.15 divided by number of graph vertices?
althalus
Since I was still unsure about the scatter-gather, I did a bit of reading on Wikipedia:
Gather - reads data from multiple buffers and writes to a single dota stream,
Scatter - reads data from a data stream and writes to multiple buffers,
the buffers are given in a vector of buffers.
Hope this helps anyone who forgot what these instructions did.
jsunseri
@momoda Looks like there are two versions of the algorithm (see this source for an explanation), and this slide uses version 1 (the original published version) while the previous slide uses version 2. Basically the one on the previous slide gives an actual probability of reaching a page after clicking on many links; all the PageRanks form a probability distribution over all websites. The one on this slide is the expected number of times someone would reach a website if they restarted the search procedure as many times as there are websites.
There is a slide that intuitively shows how gather, apply, scatter works in GraphLab, as well as GraphChi. The way GraphChi deals with the problem that the edge list cannot fit into memory is exactly like the sharding talked about in this class. In GraphiChi, different shards are processed in parallel. The sliding window in GraphChi stands for the sequential disk access required for processing each shard.
What is the high-level idea behind having two functions (gather and apply) to update the new vertex rank?
@totofufu I think gather calculates the weighted sum of each in-edge that is selected by gather_edges, and then apply sums all the values from gather and produce a new rank score for the vertex.
As opposed to most graph libraries that are called by the user program. It is noted in lecture that GraphLab is a framework that is running at top-level, and calls the user-defined operations to complete computation.
In "Update vertex rank" function, why isn't 0.15 divided by number of graph vertices?
Since I was still unsure about the scatter-gather, I did a bit of reading on Wikipedia:
Gather - reads data from multiple buffers and writes to a single dota stream,
Scatter - reads data from a data stream and writes to multiple buffers, the buffers are given in a vector of buffers.
Hope this helps anyone who forgot what these instructions did.
@momoda Looks like there are two versions of the algorithm (see this source for an explanation), and this slide uses version 1 (the original published version) while the previous slide uses version 2. Basically the one on the previous slide gives an actual probability of reaching a page after clicking on many links; all the PageRanks form a probability distribution over all websites. The one on this slide is the expected number of times someone would reach a website if they restarted the search procedure as many times as there are websites.