How do we determine the size of each shard(how many vertices)? If I understand this correctly, the larger the better as long as it fits into memory?
Fantasy
@efficiens
Yes.
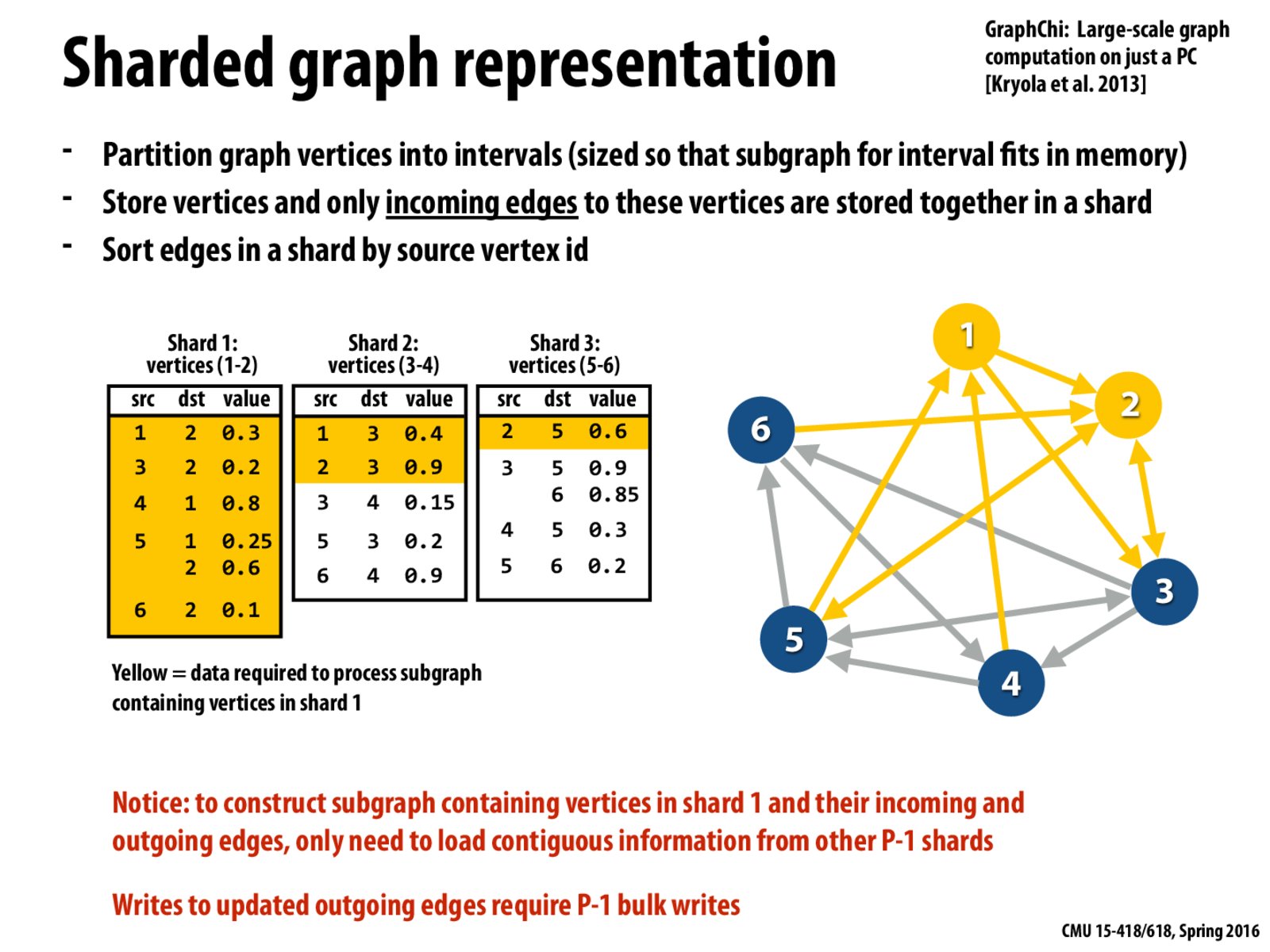
According to the rules, each shard only stores vertices and incoming edges.
For example, shard 1 stores vertices 1 and 2, so the dst part of shard one only includes vertices 1 and 2 (the edges are all incoming edges to vertices 1 and 2).
And edges are sorted by source vertex id, so the src part of shard one goes from 1 to 6.
misaka-10032
I don't think it has to fit into the memory; it's on disk, I think? And We fit as many vertices as possible into a shard. The benefit of this sorted structure is that we can collect incoming and outgoing edges from different shards streamingly. As we know, random access on disk is slow, but sequential reads are much faster.
jhibshma
As the size and degree of the graph goes up, it seems like (depending on the graph's structure) you'd need to pull data from more and more shards, eventually removing the contiguous property when looking at outgoing edges. In current, practical computer science applications does this ever become an issue, or is sharding generally a good enough technique?
ote
On the previous slide we said that our goal was to restructure graph data structure so that data
access requires only a small number of efficient bulk loads/stores from slow storage? I don't really see how this sharded graph representation is accomplishing that.
mperron
@ote Since this is a toy example the sets are very small, but a general rule for reading from persistent storage (this is more true for spinning disks than SSDs) is that it is faster to perform long sequential reads (and writes) than to randomly access data. Restructuring the data in this way on disk allows us to perform a few sequential reads (one from each shard) rather than performing a large number of small random reads as would be required in other representations.
aeu
Is there a reason why we store it with the incoming edges but not the outgoing edges? I would assume that there are valid scenarios where storing it with outgoing edges makes more sense, such as when representing grids with directional flows.
momoda
I think both store with incoming edges and outgoing edges are OK. If we redesign these three Shards to store outgoing edge, data access also requires only a small number of efficient bulk loads/store.
enuitt
@momoda Yes I think you are right. This could be why we had both types of storage representations in Assignment 3. Perhaps the representation would depend on which representation would better fit the algorithm in question?
patrickbot
With a sharded graph representation, we load contiguous chunks from all P shards. Is there another representation that can do better than this (maybe on average load from fewer than P shards)?
If we need to read data from all P shards, isn't it expensive to make P requests, especially if P is really large. Is it possible to be bandwidth bound?
How are edges sorted? In terms of src?
How do we determine the size of each shard(how many vertices)? If I understand this correctly, the larger the better as long as it fits into memory?
@efficiens Yes.
According to the rules, each shard only stores vertices and incoming edges. For example, shard 1 stores vertices 1 and 2, so the dst part of shard one only includes vertices 1 and 2 (the edges are all incoming edges to vertices 1 and 2).
And edges are sorted by source vertex id, so the src part of shard one goes from 1 to 6.
I don't think it has to fit into the memory; it's on disk, I think? And We fit as many vertices as possible into a shard. The benefit of this sorted structure is that we can collect incoming and outgoing edges from different shards streamingly. As we know, random access on disk is slow, but sequential reads are much faster.
As the size and degree of the graph goes up, it seems like (depending on the graph's structure) you'd need to pull data from more and more shards, eventually removing the contiguous property when looking at outgoing edges. In current, practical computer science applications does this ever become an issue, or is sharding generally a good enough technique?
On the previous slide we said that our goal was to restructure graph data structure so that data access requires only a small number of efficient bulk loads/stores from slow storage? I don't really see how this sharded graph representation is accomplishing that.
@ote Since this is a toy example the sets are very small, but a general rule for reading from persistent storage (this is more true for spinning disks than SSDs) is that it is faster to perform long sequential reads (and writes) than to randomly access data. Restructuring the data in this way on disk allows us to perform a few sequential reads (one from each shard) rather than performing a large number of small random reads as would be required in other representations.
Is there a reason why we store it with the incoming edges but not the outgoing edges? I would assume that there are valid scenarios where storing it with outgoing edges makes more sense, such as when representing grids with directional flows.
I think both store with incoming edges and outgoing edges are OK. If we redesign these three Shards to store outgoing edge, data access also requires only a small number of efficient bulk loads/store.
@momoda Yes I think you are right. This could be why we had both types of storage representations in Assignment 3. Perhaps the representation would depend on which representation would better fit the algorithm in question?
With a sharded graph representation, we load contiguous chunks from all P shards. Is there another representation that can do better than this (maybe on average load from fewer than P shards)?
If we need to read data from all P shards, isn't it expensive to make P requests, especially if P is really large. Is it possible to be bandwidth bound?