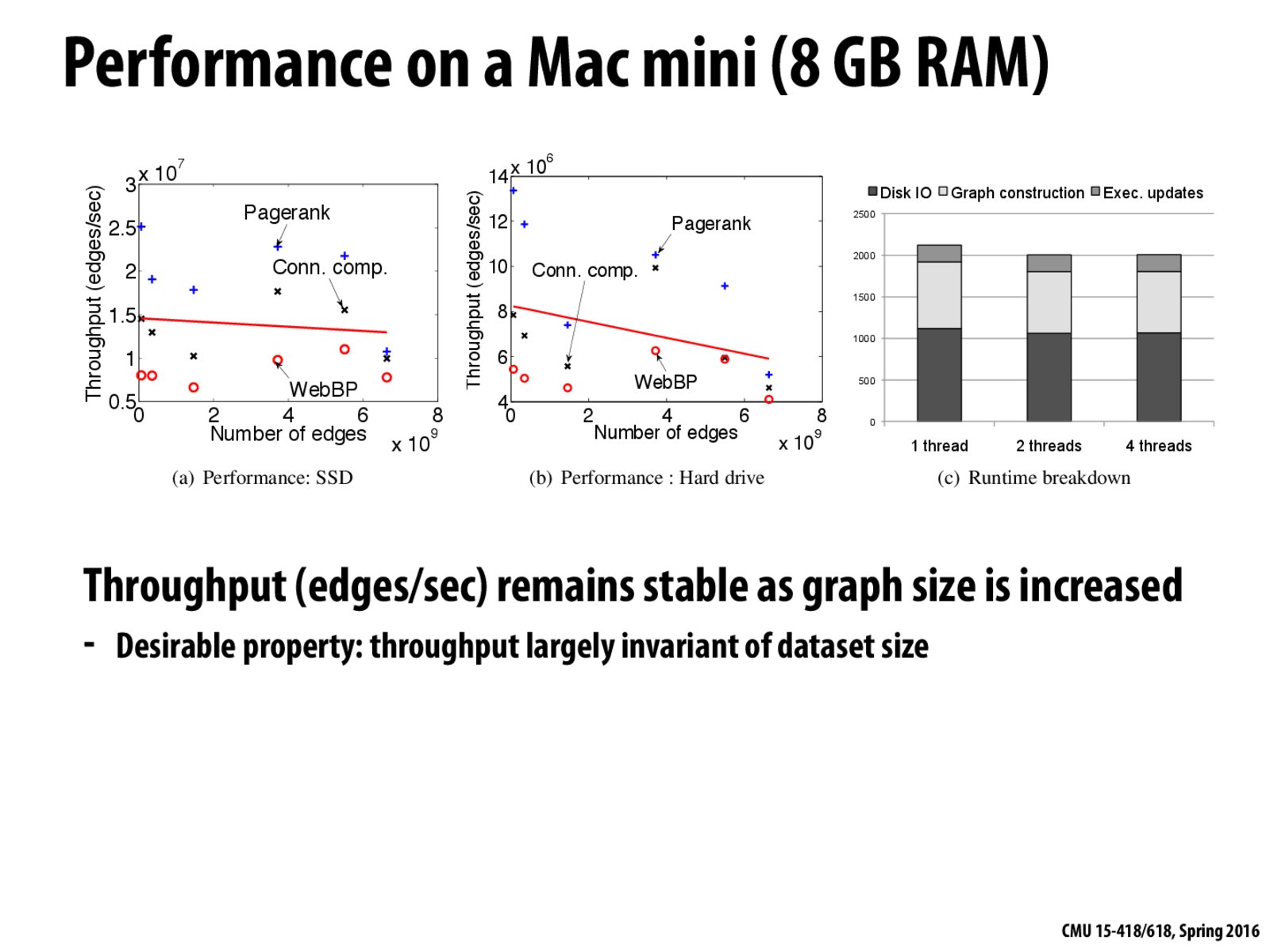
Just making sure I understand the third graph here:
- In the case that the dataset does not fit in memory, the partitioning technique could hide the disk io time by prefetching data for next iteration, and thus the program's runtime breakdown will consist of the graph construction and exec. updates time, and the reduced disk io time.
- In the case that the dataset does fit in memory, this technique will only be worse because of the graph construction overhead (which is about 5-10x slow down).
PID_1
@taylor128 The partitioning technique keeps throughput stable not by prefetching, but by doing all necessary computation on a working set that small enough to fit in memory. We load the working set once, do all computation on it, and then never load that data again. This prevents us from going to disk multiple times for the same piece of data, which is very costly.
(Prefetching to hide latency is an additional optimization mentioned on slide 36)
ArbitorOfTheFountain
If prefetching was used, the disk IO would shrink as disk IO latency would be overlapped with computation and graph construction.
Just making sure I understand the third graph here: - In the case that the dataset does not fit in memory, the partitioning technique could hide the disk io time by prefetching data for next iteration, and thus the program's runtime breakdown will consist of the graph construction and exec. updates time, and the reduced disk io time. - In the case that the dataset does fit in memory, this technique will only be worse because of the graph construction overhead (which is about 5-10x slow down).
@taylor128 The partitioning technique keeps throughput stable not by prefetching, but by doing all necessary computation on a working set that small enough to fit in memory. We load the working set once, do all computation on it, and then never load that data again. This prevents us from going to disk multiple times for the same piece of data, which is very costly.
(Prefetching to hide latency is an additional optimization mentioned on slide 36)
If prefetching was used, the disk IO would shrink as disk IO latency would be overlapped with computation and graph construction.