Can someone give more examples of what the failing components can comprise of, that lead to performance scaling?
jsunseri
@stride16 I think the point was that if you expect performance scaling based on the number of nodes/CPUs/etc. and then some of those nodes fail, you get significantly worse scaling than expected even if only a few of them fail.
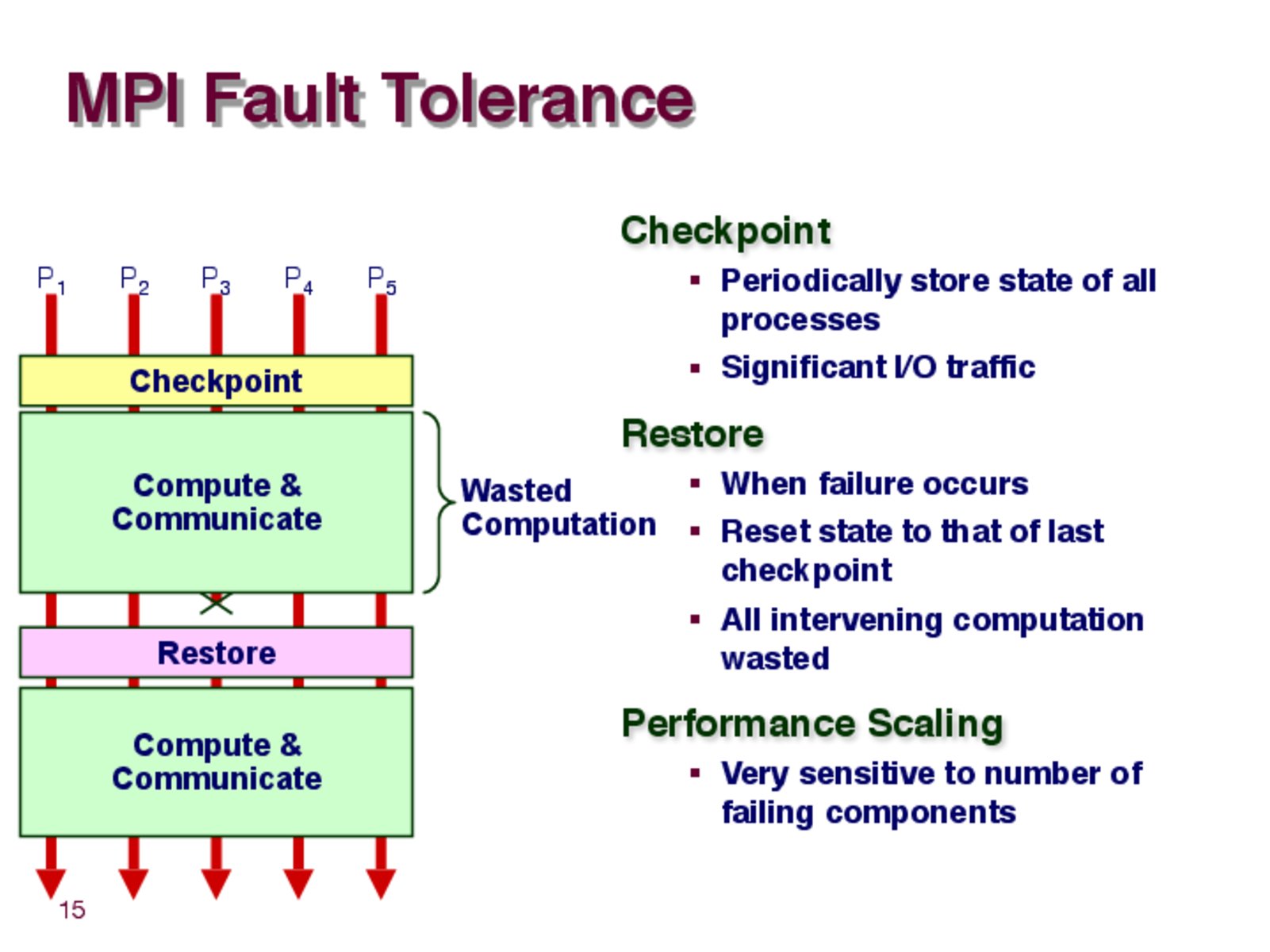
How do programmers decide when to save a checkpoint? Is it based on time or certain flags?
MPI has infrastructure for both kernel level and user defined checkpoint / restores. See here Fault tolerance for parallel MPI jobs.
Can someone give more examples of what the failing components can comprise of, that lead to performance scaling?
@stride16 I think the point was that if you expect performance scaling based on the number of nodes/CPUs/etc. and then some of those nodes fail, you get significantly worse scaling than expected even if only a few of them fail.