If links are under high contention, the cut-through routing will reduces to store-and-forward.
For example, if the second red link is bus for some reason, all the four packets will wait in previous buffer until this link is available, just lie store-and-forward.
Allerrors
Since cut-through flow control is based on packet granularity, then does the packet buffer have less utilization since there might be only one packet slice in 4 slots?
lol
@Allerrors I think the utilization is the same, in terms of unused buffer spaces, for this example.
In the store-and-forward case, there are 4 buffer spaces we don't use each timestep (each timestep 1 link is reserved, so 2 buffers). Hence total of 4 * 12 = 48 spaces over the entire route.
In the cut-through flow, we use (2,3,4,4,3,2) buffers over the 6 timesteps. Hence we don't use (4,8,12,12,8,4) spaces, which is a total of 48.
This is a very rough calculation, and in general it depends on the buffer size, packet size, length of route, and other routing traffic.
Allerrors
@lol I'm not quite understand the calculation in store-and-forward case. Transfer one packet we use 8 buffer spaces and 4 are unused and there are only 3 hops, so basically the unused buffer should be 4 * 3 = 12, why is 4 * 12?
lol
Each transfer takes 4 timesteps, and 4 are unused for each of those timesteps.
Allerrors
@lol I got it. Thanks.
yimmyz
To generalize a bit, using store-and-forward, the total latency is of order $O($"size of packet" * "distance traveled"$)$; using cut-through, it is proportional to $O($"size of packet" + "distance traveled"$)$. Apparently, the effect can be huge when either the packet size or distance of travel becomes large.
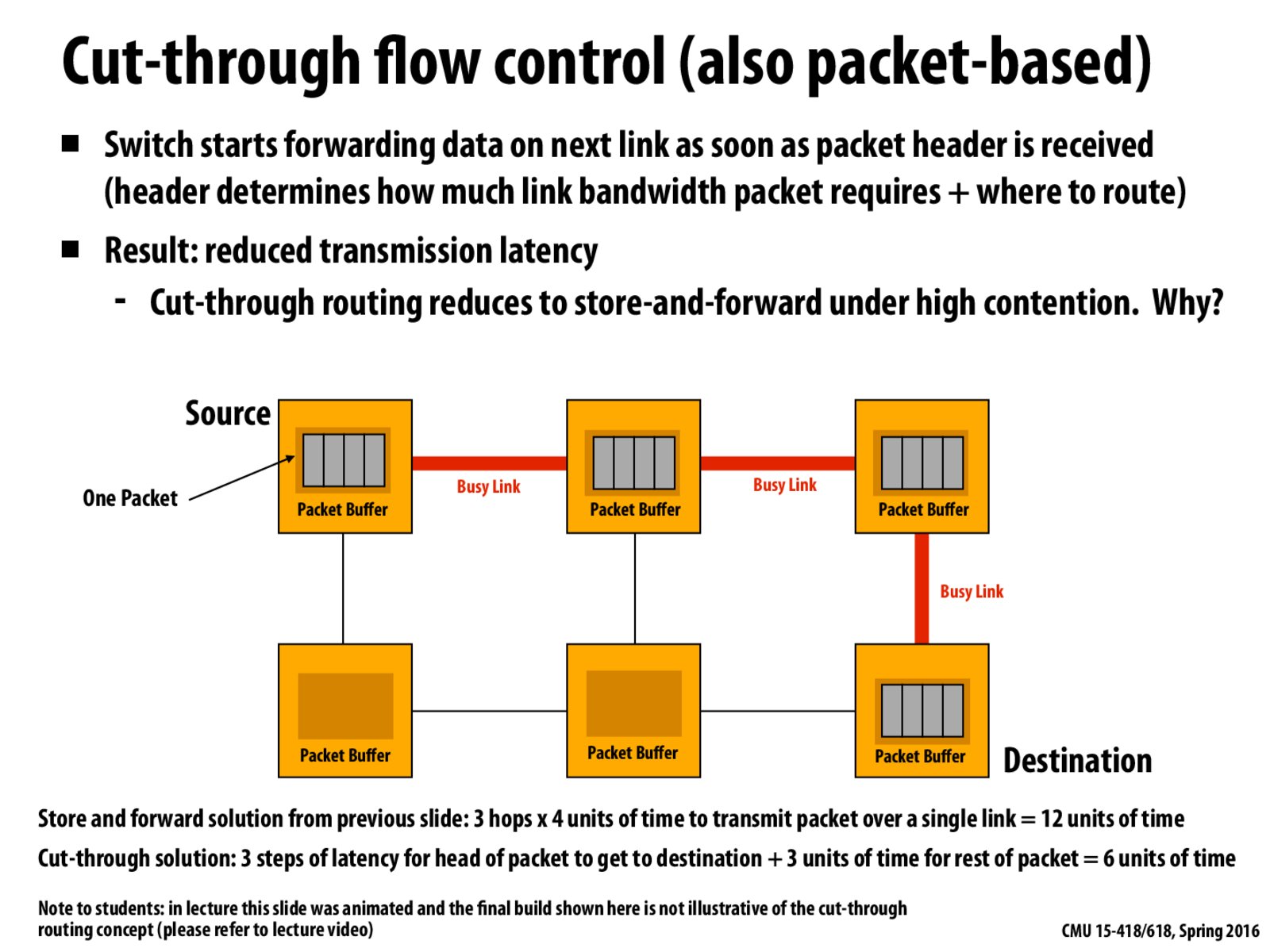
If links are under high contention, the cut-through routing will reduces to store-and-forward. For example, if the second red link is bus for some reason, all the four packets will wait in previous buffer until this link is available, just lie store-and-forward.
Since cut-through flow control is based on packet granularity, then does the packet buffer have less utilization since there might be only one packet slice in 4 slots?
@Allerrors I think the utilization is the same, in terms of unused buffer spaces, for this example.
In the store-and-forward case, there are 4 buffer spaces we don't use each timestep (each timestep 1 link is reserved, so 2 buffers). Hence total of 4 * 12 = 48 spaces over the entire route.
In the cut-through flow, we use (2,3,4,4,3,2) buffers over the 6 timesteps. Hence we don't use (4,8,12,12,8,4) spaces, which is a total of 48.
This is a very rough calculation, and in general it depends on the buffer size, packet size, length of route, and other routing traffic.
@lol I'm not quite understand the calculation in store-and-forward case. Transfer one packet we use 8 buffer spaces and 4 are unused and there are only 3 hops, so basically the unused buffer should be 4 * 3 = 12, why is 4 * 12?
Each transfer takes 4 timesteps, and 4 are unused for each of those timesteps.
@lol I got it. Thanks.
To generalize a bit, using store-and-forward, the total latency is of order $O($"size of packet" * "distance traveled"$)$; using cut-through, it is proportional to $O($"size of packet" + "distance traveled"$)$. Apparently, the effect can be huge when either the packet size or distance of travel becomes large.