So in this case, a thread would still be able to read 18? It wouldn't be able to modify 18 because it would need a lock on 11 for that, which T0 has. But does it need to get a lock just to read from something that isn't locked, like 18?
misaka-10032
It assumes that we must traverse from the start, so that the later threads won't be able to surpass the threads ahead of them.
c0d3r
This code works even if a thread does not traverse from the start. In this case, a new thread could still read 18, but it could not delete 18 because it would need the lock on 11 to do so.
MaxFlowMinCut
It seems like hand-over-hand locking is a nice tool for any DAG data structure (i.e. trees, linked lists, etc), but not really for anything else. For example, in a cyclic graph we could run into deadlock if two threads on two different nodes try to access the other's lock at the same time.
CaptainBlueBear
@huehue I believe it was mentioned in class that both readers and writers of nodes need to hold the lock to avoid reading deallocated memory
traveling_saleswoman
It seems to me that hand-to-hand locking alleviates the problem of potential false sharing in whole-list locking, but doesn't completely solve it.
If all threads only traverse the list by going from the head, then you could have a scenario where one thread wants to modify elements at the end of the list, but needs to wait until another thread's unrelated operation on a node in the middle of the list finishes. Thus operations on elements towards the end are going to take more time for two reasons: traversal time through earlier nodes, and wait time on any threads reading/writing to earlier nodes.
randomized
@traveling_saleswoman: what do you mean by "alleviates the problem of potential false sharing"? I don't see any scope for false sharing in this scenario (I'm assuming you are talking about false sharing in caching, unless you mean something else)
traveling_saleswoman
I'm using false sharing as a more general term here to mean "we aren't fully exploiting the parallelism here". In caching, false sharing can occur when two caches need exclusive access to different memory locations that are located on the same cache line, leading to competition for the cache line when really the two processes are modifying different locations in memory.
Imagine a long linked list. T0 wants to modify a node close to the start of the list and T1 wants to modify a node at the tail of the list. If T0 starts before T1, T1 be blocked from traversing down by T0's locks. However, T1 doesn't necessarily modify those nodes - it just needs to pass through that section to get to the nodes it is modifying. This is what I meant when I said there was false sharing. T0 and T1 have separate effects, yet T1 must still wait on T0 to complete before proceeding.
It is true that in this case, T1 cannot access a section that is being modified because it might encounter a break in the list from T0's incomplete modification. However, using another construct such as transactional memory might help enable threads to pass through safely without waiting for other threads to finish their unrelated operations (see exercise 5).
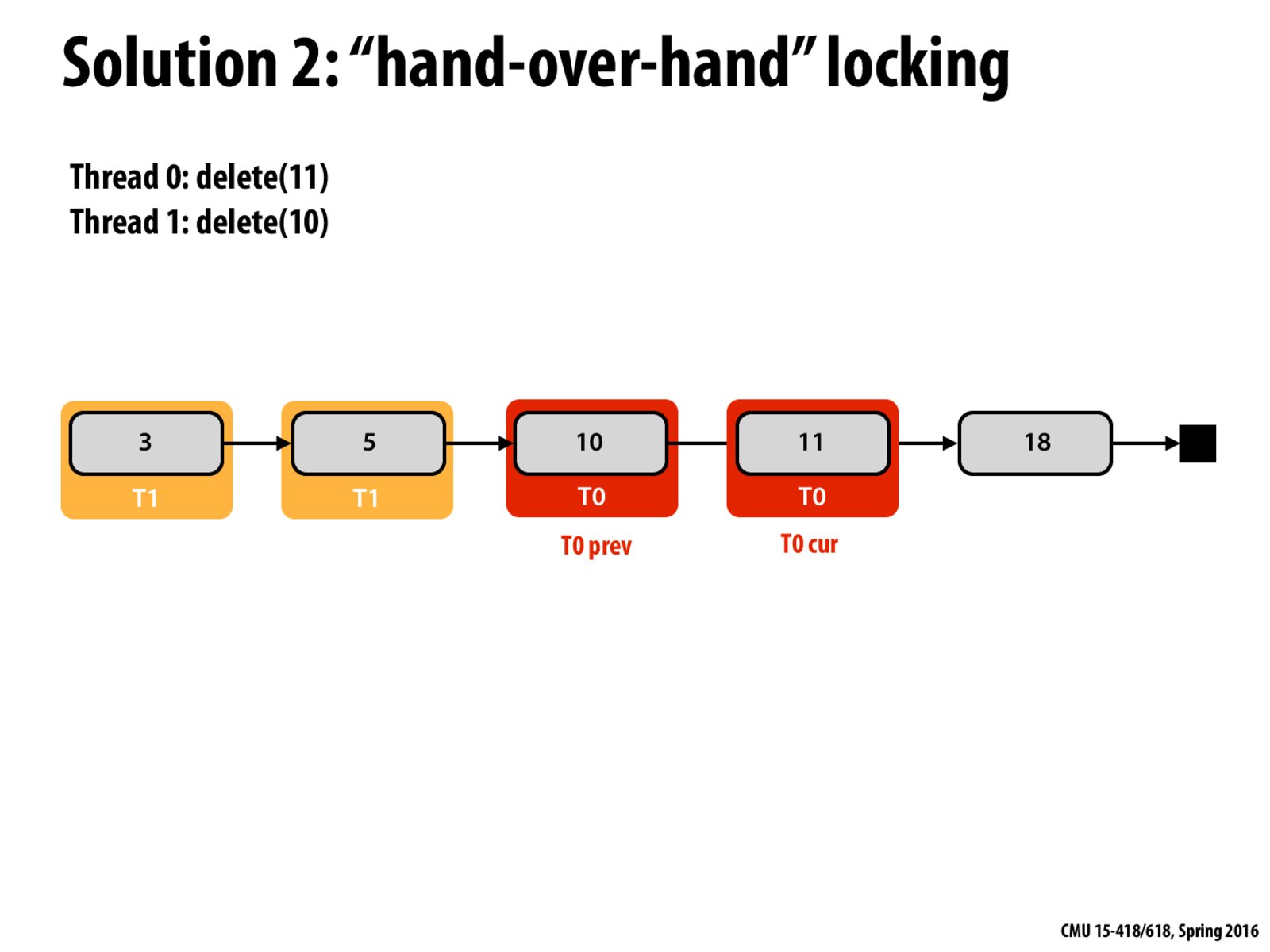
So in this case, a thread would still be able to read 18? It wouldn't be able to modify 18 because it would need a lock on 11 for that, which T0 has. But does it need to get a lock just to read from something that isn't locked, like 18?
It assumes that we must traverse from the start, so that the later threads won't be able to surpass the threads ahead of them.
This code works even if a thread does not traverse from the start. In this case, a new thread could still read 18, but it could not delete 18 because it would need the lock on 11 to do so.
It seems like hand-over-hand locking is a nice tool for any DAG data structure (i.e. trees, linked lists, etc), but not really for anything else. For example, in a cyclic graph we could run into deadlock if two threads on two different nodes try to access the other's lock at the same time.
@huehue I believe it was mentioned in class that both readers and writers of nodes need to hold the lock to avoid reading deallocated memory
It seems to me that hand-to-hand locking alleviates the problem of potential false sharing in whole-list locking, but doesn't completely solve it.
If all threads only traverse the list by going from the head, then you could have a scenario where one thread wants to modify elements at the end of the list, but needs to wait until another thread's unrelated operation on a node in the middle of the list finishes. Thus operations on elements towards the end are going to take more time for two reasons: traversal time through earlier nodes, and wait time on any threads reading/writing to earlier nodes.
@traveling_saleswoman: what do you mean by "alleviates the problem of potential false sharing"? I don't see any scope for false sharing in this scenario (I'm assuming you are talking about false sharing in caching, unless you mean something else)
I'm using false sharing as a more general term here to mean "we aren't fully exploiting the parallelism here". In caching, false sharing can occur when two caches need exclusive access to different memory locations that are located on the same cache line, leading to competition for the cache line when really the two processes are modifying different locations in memory.
Imagine a long linked list. T0 wants to modify a node close to the start of the list and T1 wants to modify a node at the tail of the list. If T0 starts before T1, T1 be blocked from traversing down by T0's locks. However, T1 doesn't necessarily modify those nodes - it just needs to pass through that section to get to the nodes it is modifying. This is what I meant when I said there was false sharing. T0 and T1 have separate effects, yet T1 must still wait on T0 to complete before proceeding.
It is true that in this case, T1 cannot access a section that is being modified because it might encounter a break in the list from T0's incomplete modification. However, using another construct such as transactional memory might help enable threads to pass through safely without waiting for other threads to finish their unrelated operations (see exercise 5).