It seems like the idea of lock-free is not so practical: it not only depends on the particular data structure, but also depends on the operations. Are there any real applications of lock-free data structures? Or are they purely academic?
bpr
@pavelkang, I know that real operating systems use lock-free stacks; however, that is the only example that I am aware of.
KnightsLanding
Why does producer/consumer perform worse than random operations?
jhibshma
Are all data structures capable of being written in a lock-free manner, or are some intrinsically impossible? It seems that this is both a theoretical CS/math question and a question based on what atomic operations your hardware supports. Maybe you can indeed create a lock-free version of data structure x if given a host of atomic operations; however, as atomic ops become "larger," do they start slowing down the system, just like locks do?
kayvonf
Many of Java's concurrent data structures are implemented using lock-free techniques.
@jhibshma - I found this paper which addresses your question:
http://dl.acm.org/citation.cfm?doid=62546.62593
The short answer seems to be: every algorithm can be written in a "wait-free" manner, if you're given certain theoretical atomic operations.
(Wait-free means no individual operation is starved indefinitely - apparently it's the strongest lock-free progress guarantee you can make).
The paper constructs a heirachy of objects. If object X is at level i, a "wait-free" version of X cannot be built with any combination of objects at level i-1 or below.
What's kind of neat is that some algorithms / data structures are, in a theoretical sense, easier to make lock-free than others. For example, adding a peek operation to a queue moves it up a level in the heirachy.
memebryant
@0xc0ffee, I can't access the paper right now, but if the results work the way I'd expect it does, it would be insanely expensive to do anything more than a level or two up on the hierarchy. Even an implementation of MCAS using CAS (Harris has a paper on this) is too expensive to do on a modern machine. Sounds like a neat proof though!
@pavelkang, lockfree stuff tends to be used in the intersection of when performance is important and multiple cores will be contending for the same data. The Linux kernel has a decent amount of lockfree code - there's a decent paper on it if I recall. HFT uses a lot of lockfree stuff, though I get the impression it's simpler stuff - bounded queues, etc.
It's quite difficult to create and prove correctness of a lockfree data structure, but it's probably not much harder to implement an existing design than implementing the "smart" locking systems discussed in class - naively locked data structures are much more prone to deadlock than you may think! Lockfree data structures might not be the first tool you should look for, but they're common enough that I'd say you should have them in your toolbox to solve scaling issues with concurrent code.
Perpendicular
A reason why fine grained locking is worse is because While traversing the list we have to acquire the lock O(n) time compared to once in a course grained. This means we are doing O(n) writes while acquiring lock which leads to a proportional increase in cache coherence traffic because of invalidations. Fine grained is ideal for data structures where different threads work on different parts of the data structure. More the number of threads the probability of them colliding on a particular node increases and their advantage diminishes.
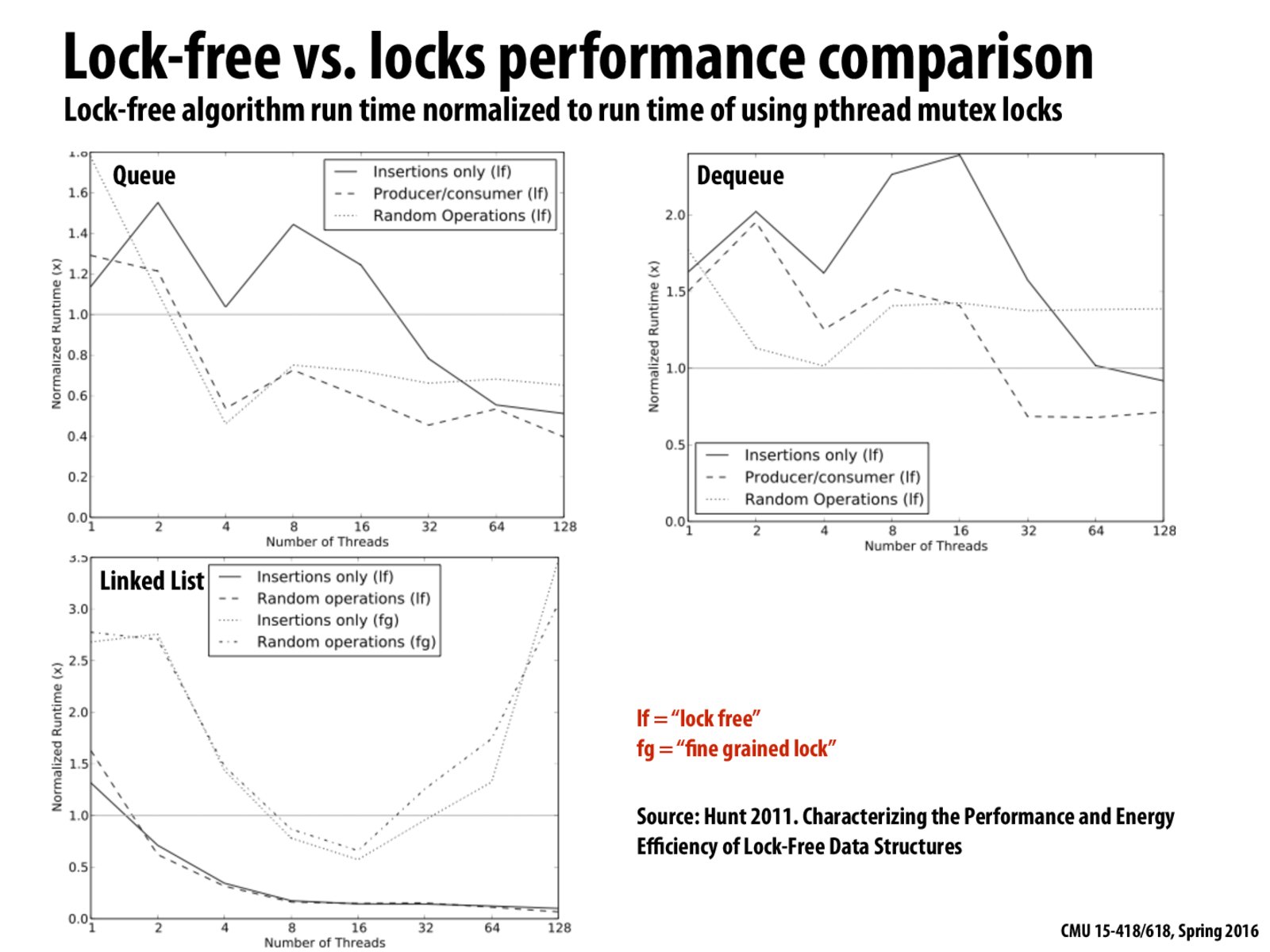
This benchmark was done on an 8-core hyperthreaded system (http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5936698), so it appears that it is oversubscription that really slows down fine-grained locking.
It seems like the idea of lock-free is not so practical: it not only depends on the particular data structure, but also depends on the operations. Are there any real applications of lock-free data structures? Or are they purely academic?
@pavelkang, I know that real operating systems use lock-free stacks; however, that is the only example that I am aware of.
Why does producer/consumer perform worse than random operations?
Are all data structures capable of being written in a lock-free manner, or are some intrinsically impossible? It seems that this is both a theoretical CS/math question and a question based on what atomic operations your hardware supports. Maybe you can indeed create a lock-free version of data structure x if given a host of atomic operations; however, as atomic ops become "larger," do they start slowing down the system, just like locks do?
Many of Java's concurrent data structures are implemented using lock-free techniques.
e.g.,
ConcurrentLinkedQueue,ConcurrentSkipListMap...Here's a good list someone made on Quora: https://www.quora.com/Are-there-any-non-blocking-lock-free-concurrent-data-structure-libraries-for-Java
@jhibshma - I found this paper which addresses your question:
http://dl.acm.org/citation.cfm?doid=62546.62593
The short answer seems to be: every algorithm can be written in a "wait-free" manner, if you're given certain theoretical atomic operations.
(Wait-free means no individual operation is starved indefinitely - apparently it's the strongest lock-free progress guarantee you can make).
The paper constructs a heirachy of objects. If object X is at level i, a "wait-free" version of X cannot be built with any combination of objects at level i-1 or below.
What's kind of neat is that some algorithms / data structures are, in a theoretical sense, easier to make lock-free than others. For example, adding a peek operation to a queue moves it up a level in the heirachy.
@0xc0ffee, I can't access the paper right now, but if the results work the way I'd expect it does, it would be insanely expensive to do anything more than a level or two up on the hierarchy. Even an implementation of MCAS using CAS (Harris has a paper on this) is too expensive to do on a modern machine. Sounds like a neat proof though!
@pavelkang, lockfree stuff tends to be used in the intersection of when performance is important and multiple cores will be contending for the same data. The Linux kernel has a decent amount of lockfree code - there's a decent paper on it if I recall. HFT uses a lot of lockfree stuff, though I get the impression it's simpler stuff - bounded queues, etc. It's quite difficult to create and prove correctness of a lockfree data structure, but it's probably not much harder to implement an existing design than implementing the "smart" locking systems discussed in class - naively locked data structures are much more prone to deadlock than you may think! Lockfree data structures might not be the first tool you should look for, but they're common enough that I'd say you should have them in your toolbox to solve scaling issues with concurrent code.
A reason why fine grained locking is worse is because While traversing the list we have to acquire the lock O(n) time compared to once in a course grained. This means we are doing O(n) writes while acquiring lock which leads to a proportional increase in cache coherence traffic because of invalidations. Fine grained is ideal for data structures where different threads work on different parts of the data structure. More the number of threads the probability of them colliding on a particular node increases and their advantage diminishes.