Are the values next to the labels indicating the percentage likelihood of a particular trait? Out of curiosity, when labeling, what happens if all the possible labels report the same likelihood? Does the algorithm have no choice but to arbitrarily pick a label at that point while training?
cmusam
@totofufu Yes, I think so. The algorithm would output Nerdy. If multiple labels share the highest likelihood, we'll need tie-breaking. Arbitrarily picking one could work. I think the situation is highly unlikely though.
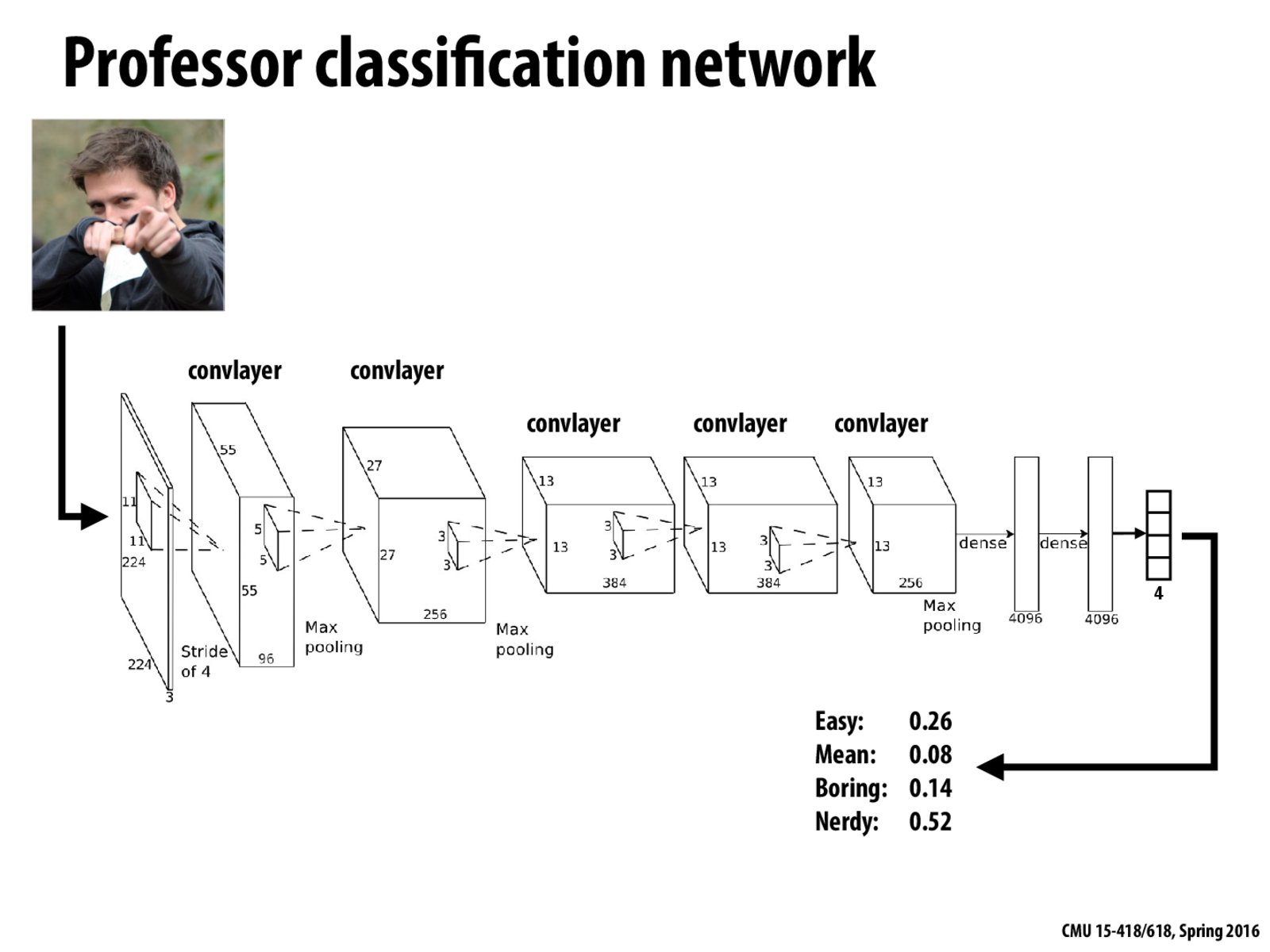
Is this a ground truth label LOL?
Are the values next to the labels indicating the percentage likelihood of a particular trait? Out of curiosity, when labeling, what happens if all the possible labels report the same likelihood? Does the algorithm have no choice but to arbitrarily pick a label at that point while training?
@totofufu Yes, I think so. The algorithm would output Nerdy. If multiple labels share the highest likelihood, we'll need tie-breaking. Arbitrarily picking one could work. I think the situation is highly unlikely though.