In backpropagation, the amount of error from an input value in the training set is used to modify the weights of the nodes in the hidden layers to decrease the amount of error.
althalus
@jaguar, could you explain what you mean by "the amount of error...is used to modify the weight"?
jaguar
Each node in an ANN is a function like a perceptron, which has a weight assigned to it that is used to compute the output of the node given some input value.
When sending training examples through the ANN, the correct output is compared to the actual output and used to compute the error at the output units. Backward propagation is used to generate the error at each of the hidden nodes. Using gradient descent, the weight of each of the neurons is modified accordingly to the gradient based on the error.
Note that gradient descent is not guaranteed to find the global minimum - it may only find a local minimum depending on the starting values and granularity.
rmanne
as jaguar said, we may not find the global minimum, so usually, training is repeated over and over again with random initial weights (in the hope that, one set of random values will give us a really good approximation for the global minimum).
Perpendicular
The max(relu) function also forces Sparse activation: For example, in a randomly initialized network, only about 50% of hidden units are activated (having a non-zero output) and Efficient gradient propagation: No vanishing gradient problem or exploding effect. So they basically speedup the gradient computation and also reduce data transfer.
stride16
Is it right for me to understand that the only benefit of backpropagation is to use the error from the input value (within the training set), to modify the weights of the nodes amongst the hidden layers and thus decrease our total error? Are there any other benefits to it?
bmperez
@stride16 That about sums it up. You can think of backpropogation as being analogous to a feedback loop in a control system. The purpose then of backpropogation is to adjust the output of the system to follow the desired value closer. It does this by looking at the error, or the difference between the desired value, and the value that was actually outputted. This can then be used to update the weights, which brings us closer to convergence with the desired behavior. This will stabilize the response of the network to these input values, reducing the overall error.
cyl
So... what's the different between back-propagation and chain rule?
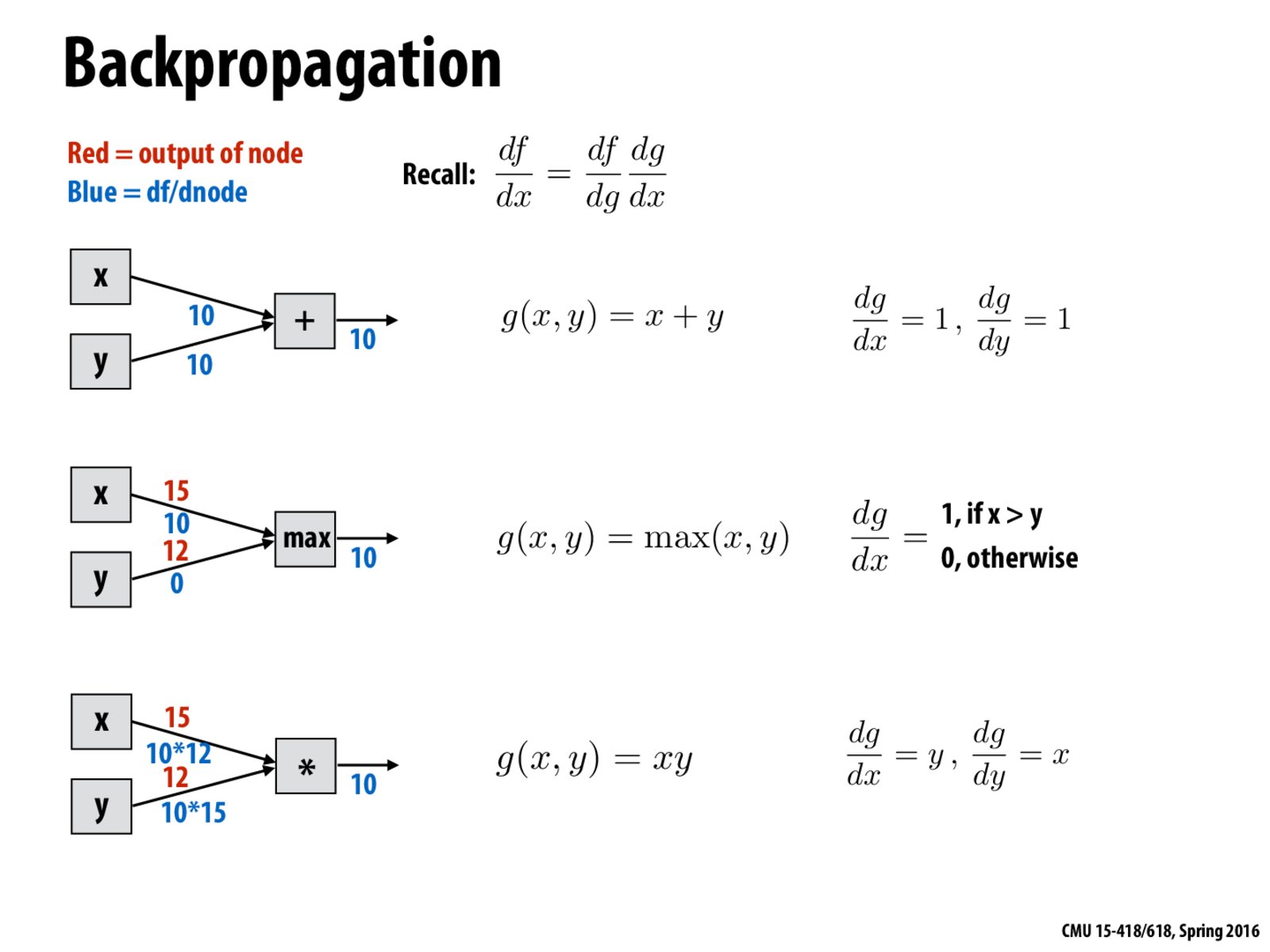
In backpropagation, the amount of error from an input value in the training set is used to modify the weights of the nodes in the hidden layers to decrease the amount of error.
@jaguar, could you explain what you mean by "the amount of error...is used to modify the weight"?
Each node in an ANN is a function like a perceptron, which has a weight assigned to it that is used to compute the output of the node given some input value. When sending training examples through the ANN, the correct output is compared to the actual output and used to compute the error at the output units. Backward propagation is used to generate the error at each of the hidden nodes. Using gradient descent, the weight of each of the neurons is modified accordingly to the gradient based on the error. Note that gradient descent is not guaranteed to find the global minimum - it may only find a local minimum depending on the starting values and granularity.
as jaguar said, we may not find the global minimum, so usually, training is repeated over and over again with random initial weights (in the hope that, one set of random values will give us a really good approximation for the global minimum).
The max(relu) function also forces Sparse activation: For example, in a randomly initialized network, only about 50% of hidden units are activated (having a non-zero output) and Efficient gradient propagation: No vanishing gradient problem or exploding effect. So they basically speedup the gradient computation and also reduce data transfer.
Is it right for me to understand that the only benefit of backpropagation is to use the error from the input value (within the training set), to modify the weights of the nodes amongst the hidden layers and thus decrease our total error? Are there any other benefits to it?
@stride16 That about sums it up. You can think of backpropogation as being analogous to a feedback loop in a control system. The purpose then of backpropogation is to adjust the output of the system to follow the desired value closer. It does this by looking at the error, or the difference between the desired value, and the value that was actually outputted. This can then be used to update the weights, which brings us closer to convergence with the desired behavior. This will stabilize the response of the network to these input values, reducing the overall error.
So... what's the different between back-propagation and chain rule?