DNN's evaluation (forward) process will be done multiple times and the output is needed to compute gradients, so the output of each layer should not be discarded after computation. So the data we need to fill in memory is: (parameters/weights) + (gradients on weights) + (gradient momentum) + (output)
huehue
Parallelism would be important for training for 2 reasons. First, we would be running a lot of images for 1000s of iterations, so we would like to make this faster. Second, all the weights and intermediates needed to back propagation may not fit in memory on one node, so we would have to use parallelism just to store all the data.
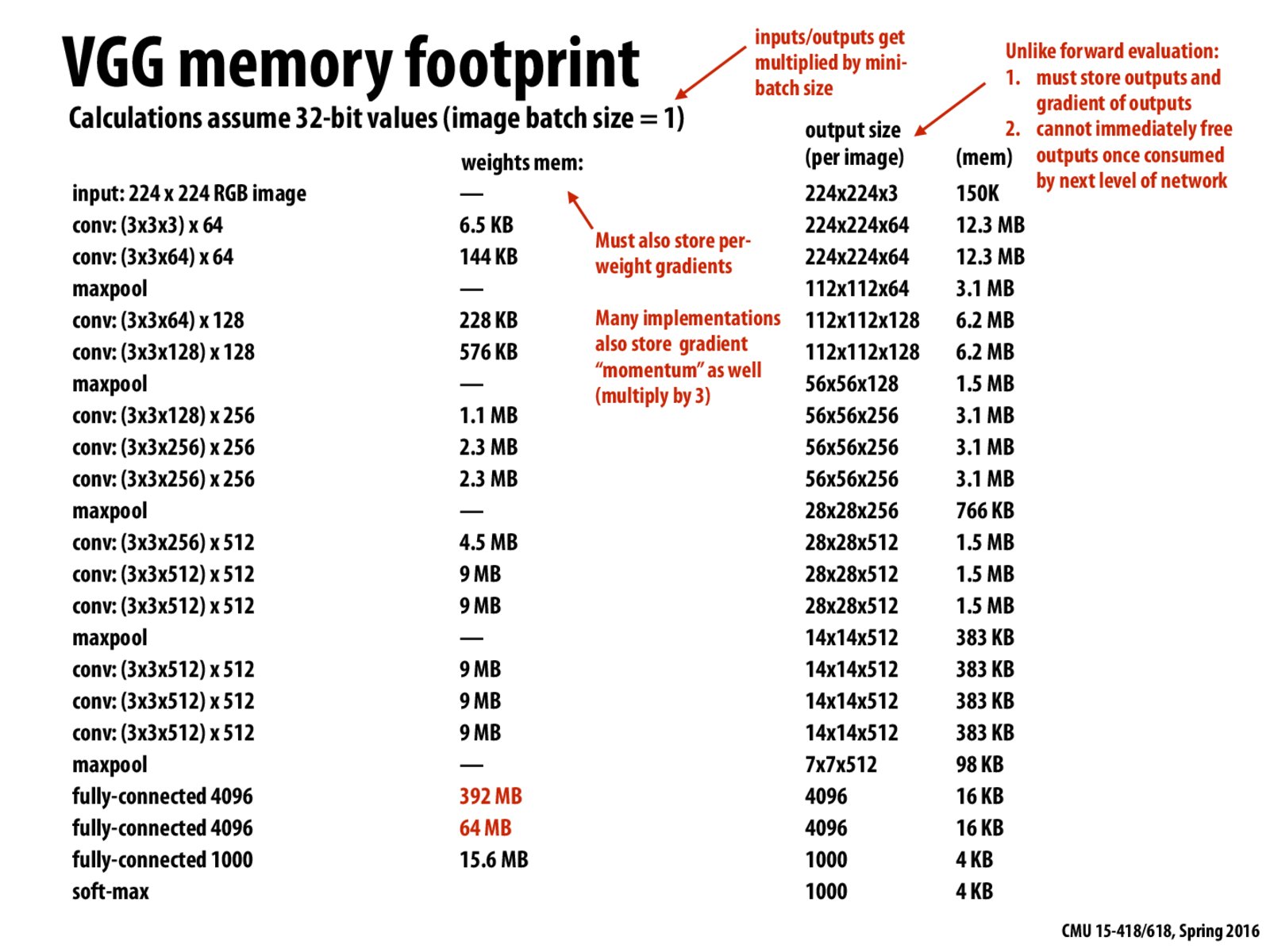
DNN's evaluation (forward) process will be done multiple times and the output is needed to compute gradients, so the output of each layer should not be discarded after computation. So the data we need to fill in memory is: (parameters/weights) + (gradients on weights) + (gradient momentum) + (output)
Parallelism would be important for training for 2 reasons. First, we would be running a lot of images for 1000s of iterations, so we would like to make this faster. Second, all the weights and intermediates needed to back propagation may not fit in memory on one node, so we would have to use parallelism just to store all the data.