As discussed in lecture, when distributing the training data, it's extremely important to make sure we don't accidentally introduce biases to the various worker nodes. To counteract this, we can periodically switch the data at each node and/or shuffle the data around periodically.
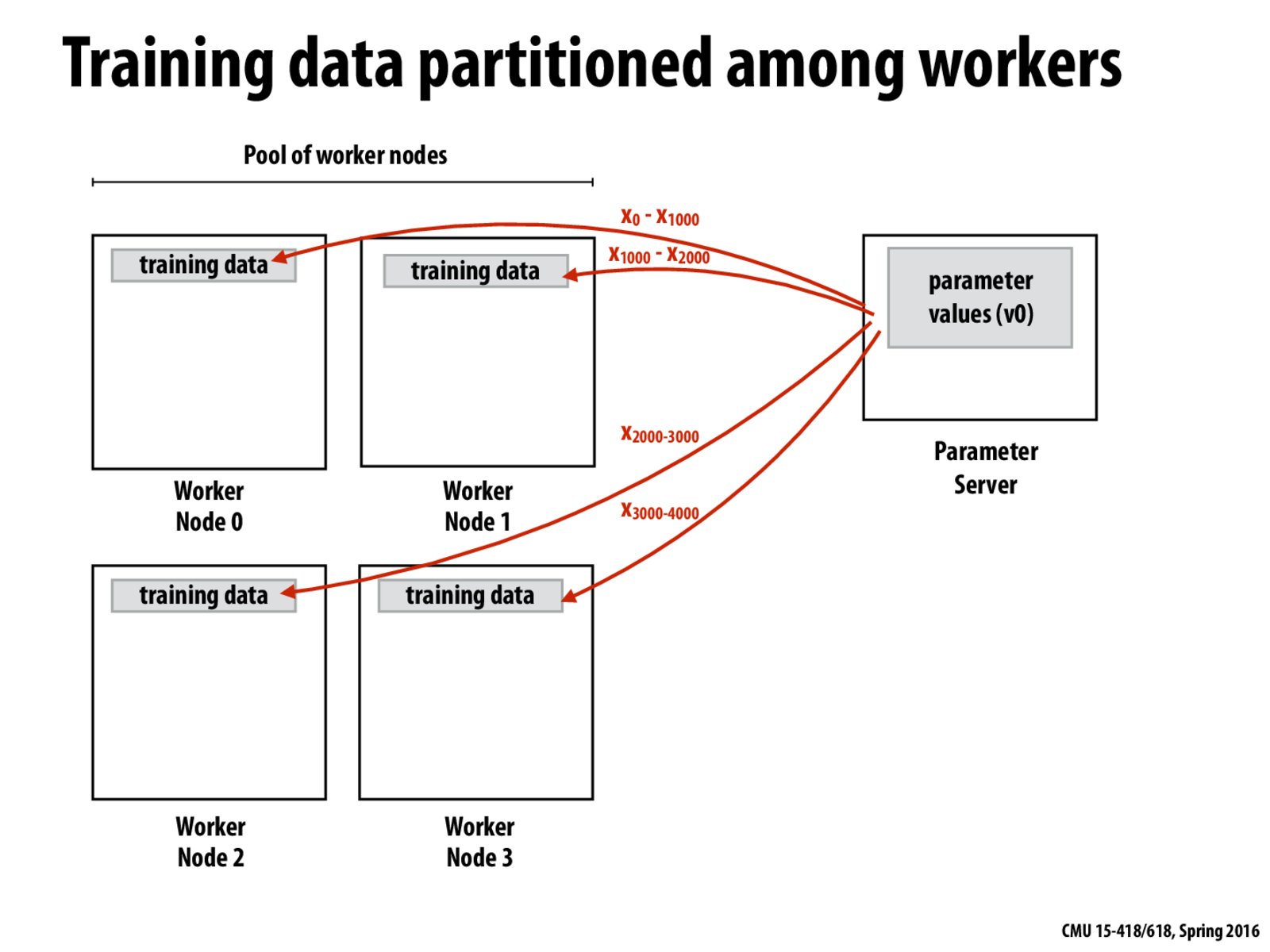
As discussed in lecture, when distributing the training data, it's extremely important to make sure we don't accidentally introduce biases to the various worker nodes. To counteract this, we can periodically switch the data at each node and/or shuffle the data around periodically.