I was wondering if I was thinking about this correctly
Worker 0 and worker 1 each get the original parameter values from the parameter server
Worker 0 finishes calculating its gradients first... the parameter server does the update
and sends worker 0 a new batch of training examples and the updated parameters
Now worker 1 finishes calculating its gradients and sends these to the parameter server...
So the parameters on the server (which were updated by the gradients calculated in worker 0) are being updated with gradients which were calculated on worker 1 using the original parameters. This produces some error; however, if the mini-batch isn't too large this error will be negligible.
365sleeping
@IntergalacticPeanutMaker You are right. Not only the size of mini-batch matters, but also the value of learning rate. Also, it is because that the error is negligible, but the gradient doesn't have to be perfect.
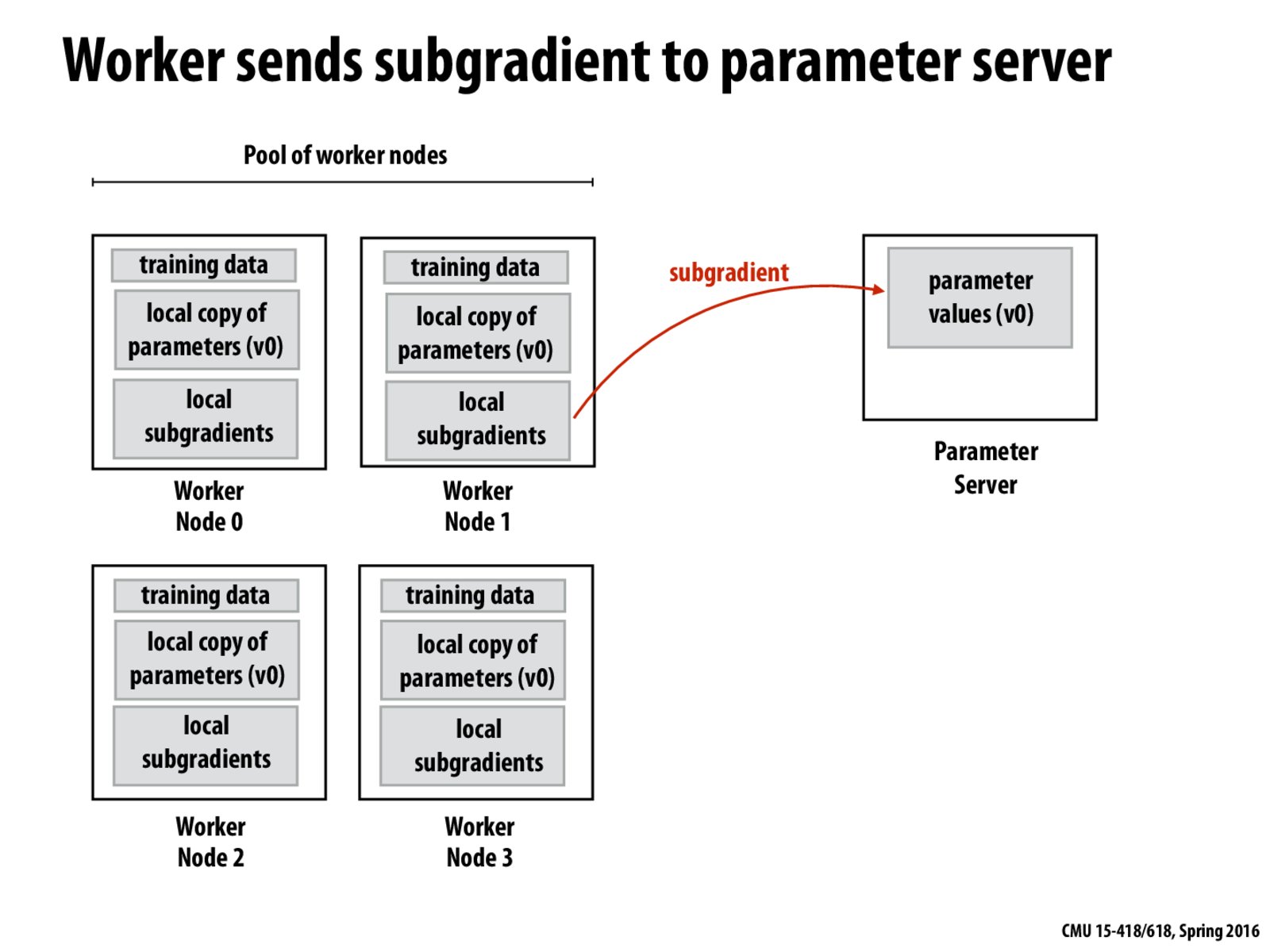
I was wondering if I was thinking about this correctly
Worker 0 and worker 1 each get the original parameter values from the parameter server
Worker 0 finishes calculating its gradients first... the parameter server does the update and sends worker 0 a new batch of training examples and the updated parameters
Now worker 1 finishes calculating its gradients and sends these to the parameter server...
So the parameters on the server (which were updated by the gradients calculated in worker 0) are being updated with gradients which were calculated on worker 1 using the original parameters. This produces some error; however, if the mini-batch isn't too large this error will be negligible.
@IntergalacticPeanutMaker You are right. Not only the size of mini-batch matters, but also the value of learning rate. Also, it is because that the error is negligible, but the gradient doesn't have to be perfect.