For those who haven't taken ML, the notion of updating the parameters at each step as opposed to once at the end of the training run is called 'online' vs. 'batch' updating, respectively. There are pros and cons to each approach. More information on online updating (and a bit of a comparison to batch updating) can be found here.
This seems to be hybrid between both approaches and while I'm no ML expert, I think it may actually help with certain problems of either approaches.
efficiens
@aeu Is batch updating training the data with a large dataset only once or after specific a time period? I haven't taken ML so am not sure.
RX
It is called model-parallelism if the parameters are partitioned among worker nodes, it requires that the local subgradients could be computed independently of other parameters. In deep neural network training, I don't think that's the case, because we need the whole model to evaluate (feed forward) and then backward propagation. In fact, many state-of-the-art distributed DNN training frameworks are not model-parallelism, many of them assume that the whole model could be fit in main memory (CPU training) of each node or GPU memory (GPU training)
aeu
@efficiens What batch does is it goes through the entire training set, accumulates all the changes to weights and updates the weights once at the end, with the sum of all the updates 'batched'. Then, you go through the training set again, updating the weights with the accumulated change to weights at the end, then a third time, etc.
There are methods of leaving some of the tests out randomly at each step to test agains and check for error rate and convergence but it's a detail.
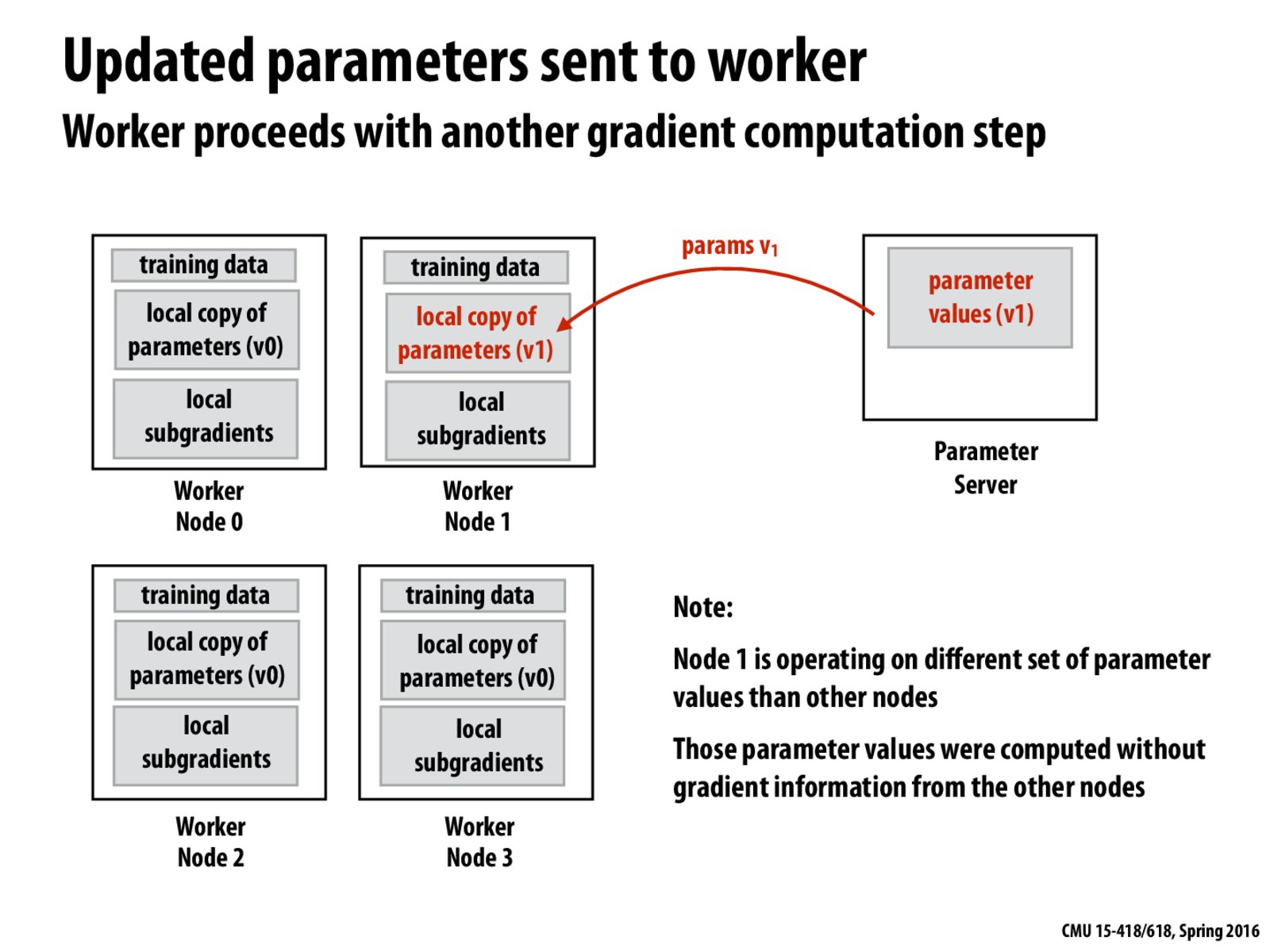
For those who haven't taken ML, the notion of updating the parameters at each step as opposed to once at the end of the training run is called 'online' vs. 'batch' updating, respectively. There are pros and cons to each approach. More information on online updating (and a bit of a comparison to batch updating) can be found here.
This seems to be hybrid between both approaches and while I'm no ML expert, I think it may actually help with certain problems of either approaches.
@aeu Is batch updating training the data with a large dataset only once or after specific a time period? I haven't taken ML so am not sure.
It is called model-parallelism if the parameters are partitioned among worker nodes, it requires that the local subgradients could be computed independently of other parameters. In deep neural network training, I don't think that's the case, because we need the whole model to evaluate (feed forward) and then backward propagation. In fact, many state-of-the-art distributed DNN training frameworks are not model-parallelism, many of them assume that the whole model could be fit in main memory (CPU training) of each node or GPU memory (GPU training)
@efficiens What batch does is it goes through the entire training set, accumulates all the changes to weights and updates the weights once at the end, with the sum of all the updates 'batched'. Then, you go through the training set again, updating the weights with the accumulated change to weights at the end, then a third time, etc.
There are methods of leaving some of the tests out randomly at each step to test agains and check for error rate and convergence but it's a detail.