Only the data that cross the boundary needs to be communicated. In this sense, much less data needs to be moved in conv layers compared with dense layers.
shihenw
1x1 convolutions are used when we transform a classification network (one image mapped to a length-of-4 vector) to be fully convolutional, outputting a 4-channel image, or feature map, where every patch on the input image is mapped to a length-of-4 vector (now in channel dimension). In this way the size of input and output images can be arbitrary.
In fact, I believe it is probably easier to create smaller networks that fits in memory that sample patches of the image instead to achieve the same effect.
shihenw
@bojianh You can achieve the same effect (here by "same" we mean the network is trained with the same amount of training data sampled from image) by sampling "every patch" on the image, which is inefficient because overlapping patches share computation of convolutions. I agree FCNN may cause memory problems, which motivates parallelism to distribute memory footprints over GPUs/machines.
bojianh
@shihenw: It is true that overlapping patches will result in more computation. However, take note that we are actually bounded by memory in this case, so trading more computation for less things in the memory may not be a bad idea.
TanXiaoFengSheng
If we divide the parameters horizontally as in this slides, then after each step, some amount of data has to be communicated and the total communication cost would be O(d) where d is the depth of network
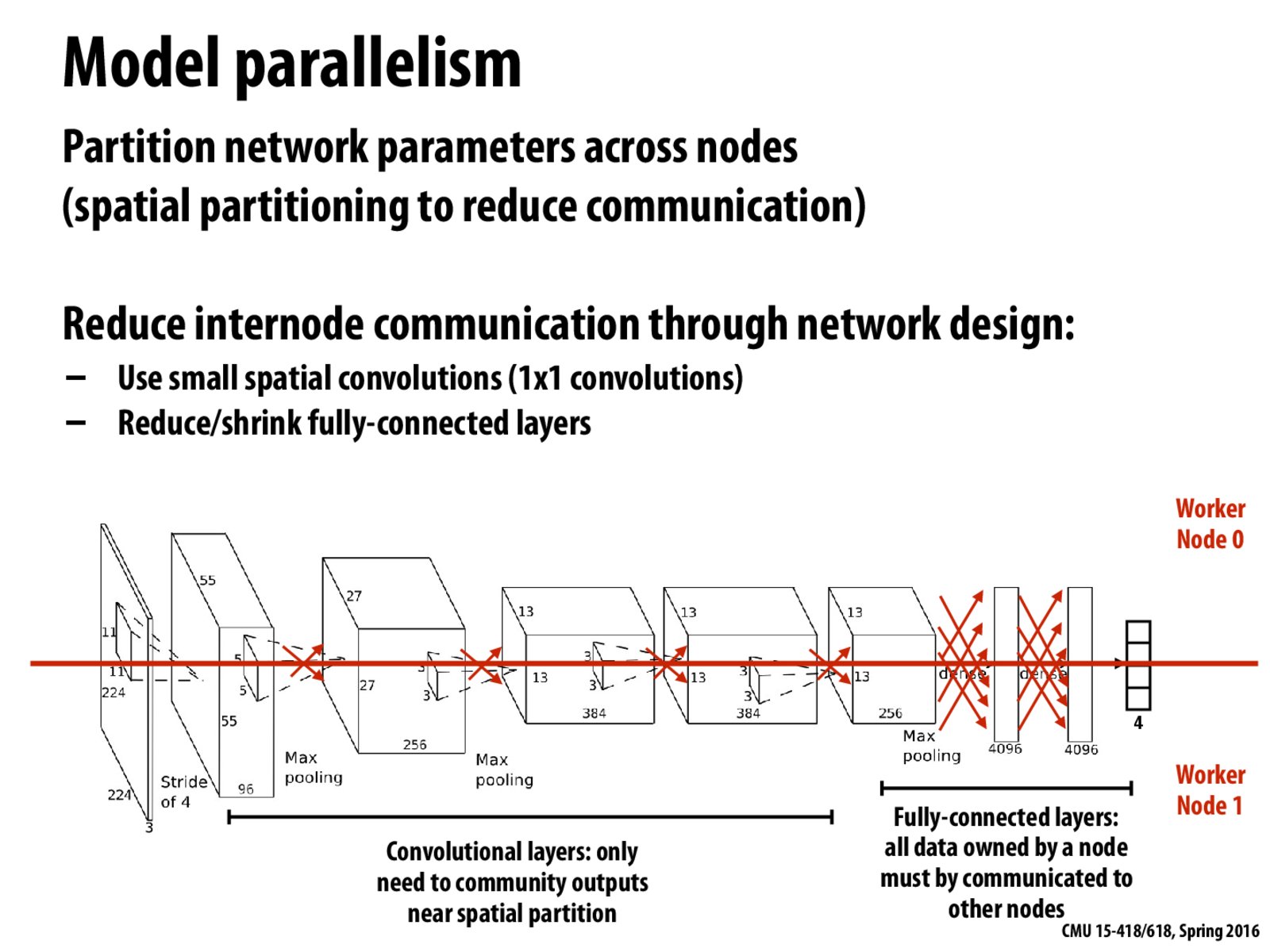
Only the data that cross the boundary needs to be communicated. In this sense, much less data needs to be moved in conv layers compared with dense layers.
1x1 convolutions are used when we transform a classification network (one image mapped to a length-of-4 vector) to be fully convolutional, outputting a 4-channel image, or feature map, where every patch on the input image is mapped to a length-of-4 vector (now in channel dimension). In this way the size of input and output images can be arbitrary.
This paper brought this idea first.
In fact, I believe it is probably easier to create smaller networks that fits in memory that sample patches of the image instead to achieve the same effect.
@bojianh You can achieve the same effect (here by "same" we mean the network is trained with the same amount of training data sampled from image) by sampling "every patch" on the image, which is inefficient because overlapping patches share computation of convolutions. I agree FCNN may cause memory problems, which motivates parallelism to distribute memory footprints over GPUs/machines.
@shihenw: It is true that overlapping patches will result in more computation. However, take note that we are actually bounded by memory in this case, so trading more computation for less things in the memory may not be a bad idea.
If we divide the parameters horizontally as in this slides, then after each step, some amount of data has to be communicated and the total communication cost would be O(d) where d is the depth of network