It's possible to get a speedup of more than P using P processors in this graph. This is because as we add more processors, we also get more cache along with each processor. Also, we are dividing up the grid into smaller blocks because there are more processors available. So, at some point the working set will be small enough to fit into a processor's cache. We can therefore get a super-linear speed up because accesses that used to result in going to memory can instead utilize cache.
jerryzh
It's counter-intuitive to have a speedup that's greater than the "ideal" ones at the first glance. One way to understand it is that the "ideal" speedup of P indicates only the speedup if we divide the same amount of work to P machines, but the actual speedup contains the effect of cache which is realized only when we partition the data into more blocks, that is to say, when we divide the work, the work actually becomes "smaller" than original work divided by P.
eknight7
As P increases, with each new processor there is another L1 cache added to the system, which therefore helps in decreasing latency due to memory I/O. A super-linear speedup is made possible when then data accesses take a shorter amount of time than expected, and thats possible because of the extra L1 caches in this graph.
rmanne
It was also mentioned that this isn't just for cache. In distributed computing systems (or any system where there are multiple processors where each processor has access to its own private set of memory), like most of the super computers we discussed so far, it's also the case that in very large data sets that won't even fit in the RAM of a single or even a few nodes. As a result, using more such nodes may make it the case that all of it will fit in the RAM, which is a few orders of magnitude faster accessing an SSD, which is a few times faster than accessing a traditional HDD.
qqkk
A single core, single machine computation might be limited by not just ALU, but also other resources like cache, bandwidth, etc, which depends on specific programs.
If we only consider the "arithmetic computation" speed up using P processors, linear speed-up is the upper bound, because it only depends on number of computing cores.
But a processor is more than just computing cores, it also comes with cache, and even RAM if we are talking about distributed computing nodes.
yimmyz
I remember in the first lecture, a slide implies that speedup with $P$ processors "might" be higher than $P$, and now I'm glad to find out why.
However, I think this is only restricted to the optimistic cases where the program has static / predictable memory access (e.g. in scientific computation). For general purposes like multi-threaded servers / database, I don't think it is feasible to achieve super-linear speed-up. Does anyone have comments on this?
FarmerScrub
This slide reminds us that speedup is a little bit misleading and should be looked at with other stats as well. A slow parallel algorithm will still have a nice speedup if the sequential algorithm scale exponentially slower by size. Ultimately, we only care about how fast an algorithm runs.
maxdecmeridius
Isn't it also possible to get a super linear speedup due to hyper threading? In assignment 1 we saw some of these effects.
fleventyfive
@maxdecmeridius: I think that is a reasonable argument. If we consider a hyper-threaded processor to have just 1 core, then it may be possible to get 2x speedup due to the hyperthreading. However, if we consider the hyper-threaded processor to have 2*1 i.e. 2 cores, then the speedup we get would have to just be "linear".
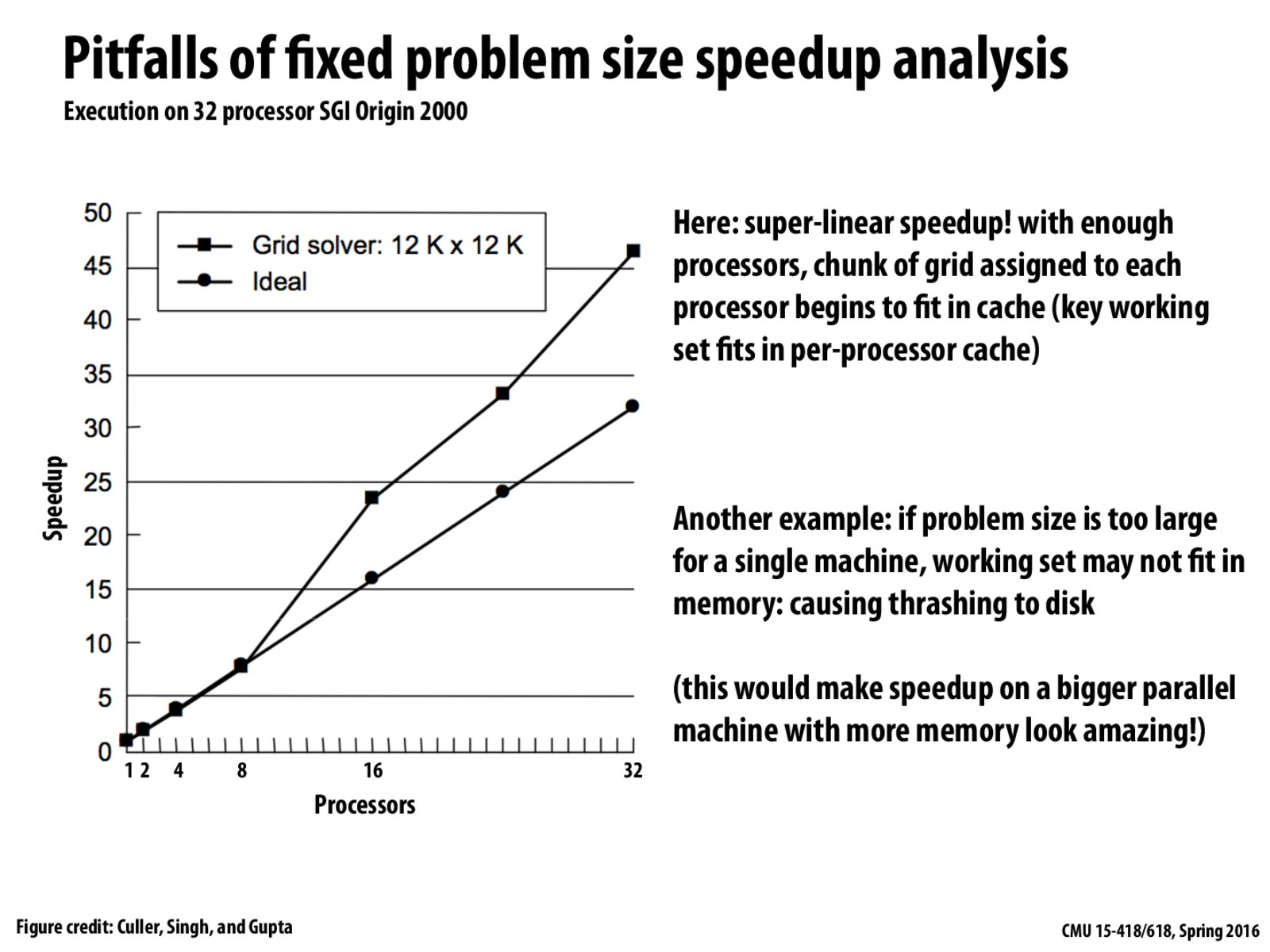
It's possible to get a speedup of more than P using P processors in this graph. This is because as we add more processors, we also get more cache along with each processor. Also, we are dividing up the grid into smaller blocks because there are more processors available. So, at some point the working set will be small enough to fit into a processor's cache. We can therefore get a super-linear speed up because accesses that used to result in going to memory can instead utilize cache.
It's counter-intuitive to have a speedup that's greater than the "ideal" ones at the first glance. One way to understand it is that the "ideal" speedup of P indicates only the speedup if we divide the same amount of work to P machines, but the actual speedup contains the effect of cache which is realized only when we partition the data into more blocks, that is to say, when we divide the work, the work actually becomes "smaller" than original work divided by P.
As P increases, with each new processor there is another L1 cache added to the system, which therefore helps in decreasing latency due to memory I/O. A super-linear speedup is made possible when then data accesses take a shorter amount of time than expected, and thats possible because of the extra L1 caches in this graph.
It was also mentioned that this isn't just for cache. In distributed computing systems (or any system where there are multiple processors where each processor has access to its own private set of memory), like most of the super computers we discussed so far, it's also the case that in very large data sets that won't even fit in the RAM of a single or even a few nodes. As a result, using more such nodes may make it the case that all of it will fit in the RAM, which is a few orders of magnitude faster accessing an SSD, which is a few times faster than accessing a traditional HDD.
A single core, single machine computation might be limited by not just ALU, but also other resources like cache, bandwidth, etc, which depends on specific programs.
If we only consider the "arithmetic computation" speed up using P processors, linear speed-up is the upper bound, because it only depends on number of computing cores. But a processor is more than just computing cores, it also comes with cache, and even RAM if we are talking about distributed computing nodes.
I remember in the first lecture, a slide implies that speedup with $P$ processors "might" be higher than $P$, and now I'm glad to find out why.
However, I think this is only restricted to the optimistic cases where the program has static / predictable memory access (e.g. in scientific computation). For general purposes like multi-threaded servers / database, I don't think it is feasible to achieve super-linear speed-up. Does anyone have comments on this?
This slide reminds us that speedup is a little bit misleading and should be looked at with other stats as well. A slow parallel algorithm will still have a nice speedup if the sequential algorithm scale exponentially slower by size. Ultimately, we only care about how fast an algorithm runs.
Isn't it also possible to get a super linear speedup due to hyper threading? In assignment 1 we saw some of these effects.
@maxdecmeridius: I think that is a reasonable argument. If we consider a hyper-threaded processor to have just 1 core, then it may be possible to get 2x speedup due to the hyperthreading. However, if we consider the hyper-threaded processor to have 2*1 i.e. 2 cores, then the speedup we get would have to just be "linear".
Link: Can Parallelism Achieve Superlinear Performance Gains?
"[normally,] our code becomes bound on memory, I/O or something else that means diminishing returns for adding more cores."
Here, it is summarized that superlinear speedup doesn't happen in general, but may be possible for problems satisfying the following properties.