I understand that if the circles are fairly evenly distributed then the solution on the right is better than shrinking the image down but would the "shrinking the image" solution be preferred if an even distribution isn't necessarily guaranteed?
Khryl
Another way to think about shrinking the image is that each pixel in the shrunk image corresponds to a 2 * 2 grid in the original image. We expect the new workload to be 1/4 of the original workload because the number of pixels are scaled down by 4. But this is often not the case, because each pixel now samples at the center of its corresponding 22 grid in the original image, so the coverage signal can be very different now. Imagine four circles all fit in each pixel in the 22 grid in the original image, after scaling, none of them will cover the center of pixel.
ArbitorOfTheFountain
While the intention of this slide is clear - in the case of the renderer might it still be faster to use a 32x32 pixel box size due to warp and block sizes in NVIDIA GPUs?
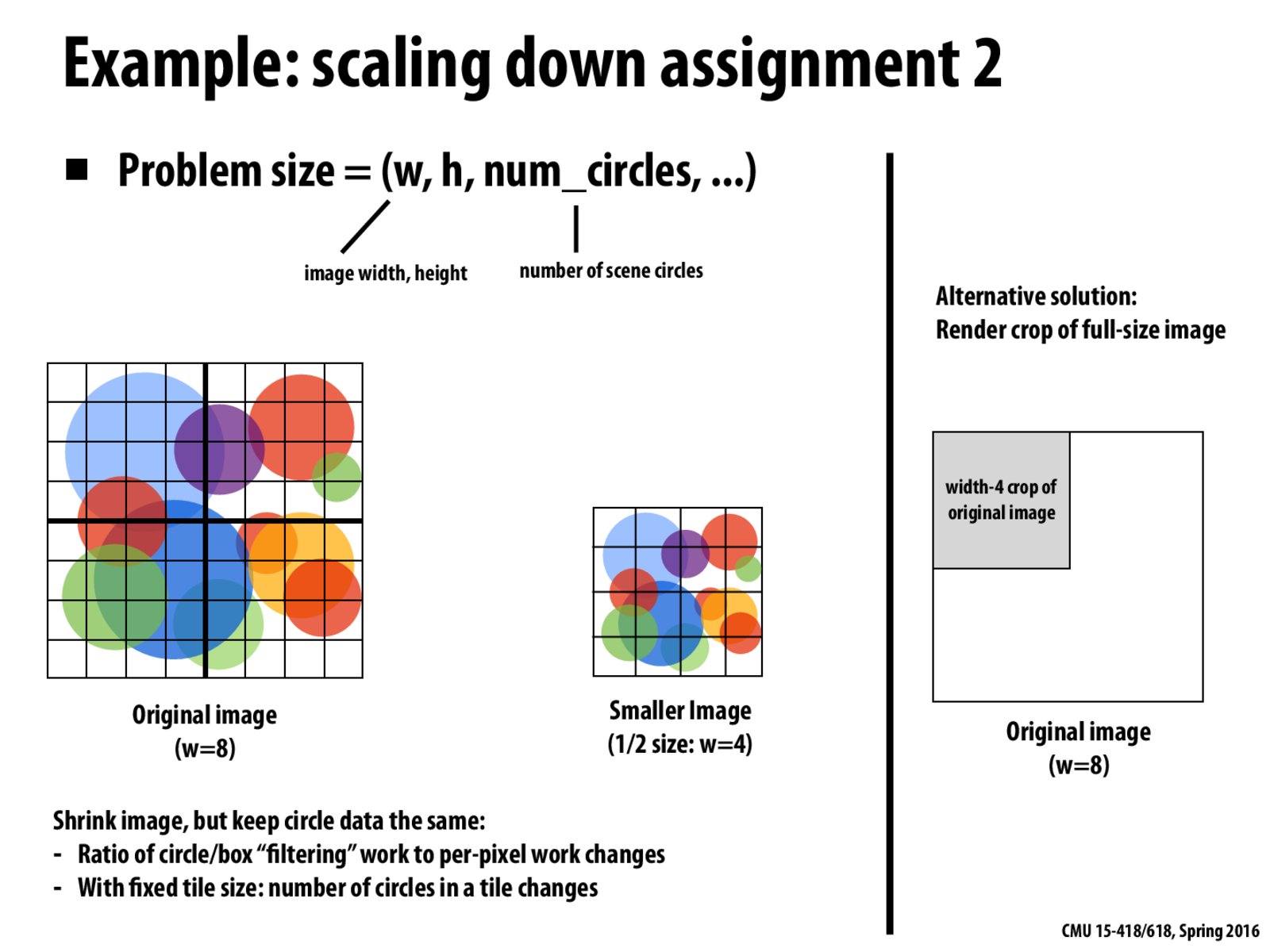
I understand that if the circles are fairly evenly distributed then the solution on the right is better than shrinking the image down but would the "shrinking the image" solution be preferred if an even distribution isn't necessarily guaranteed?
Another way to think about shrinking the image is that each pixel in the shrunk image corresponds to a 2 * 2 grid in the original image. We expect the new workload to be 1/4 of the original workload because the number of pixels are scaled down by 4. But this is often not the case, because each pixel now samples at the center of its corresponding 22 grid in the original image, so the coverage signal can be very different now. Imagine four circles all fit in each pixel in the 22 grid in the original image, after scaling, none of them will cover the center of pixel.
While the intention of this slide is clear - in the case of the renderer might it still be faster to use a 32x32 pixel box size due to warp and block sizes in NVIDIA GPUs?