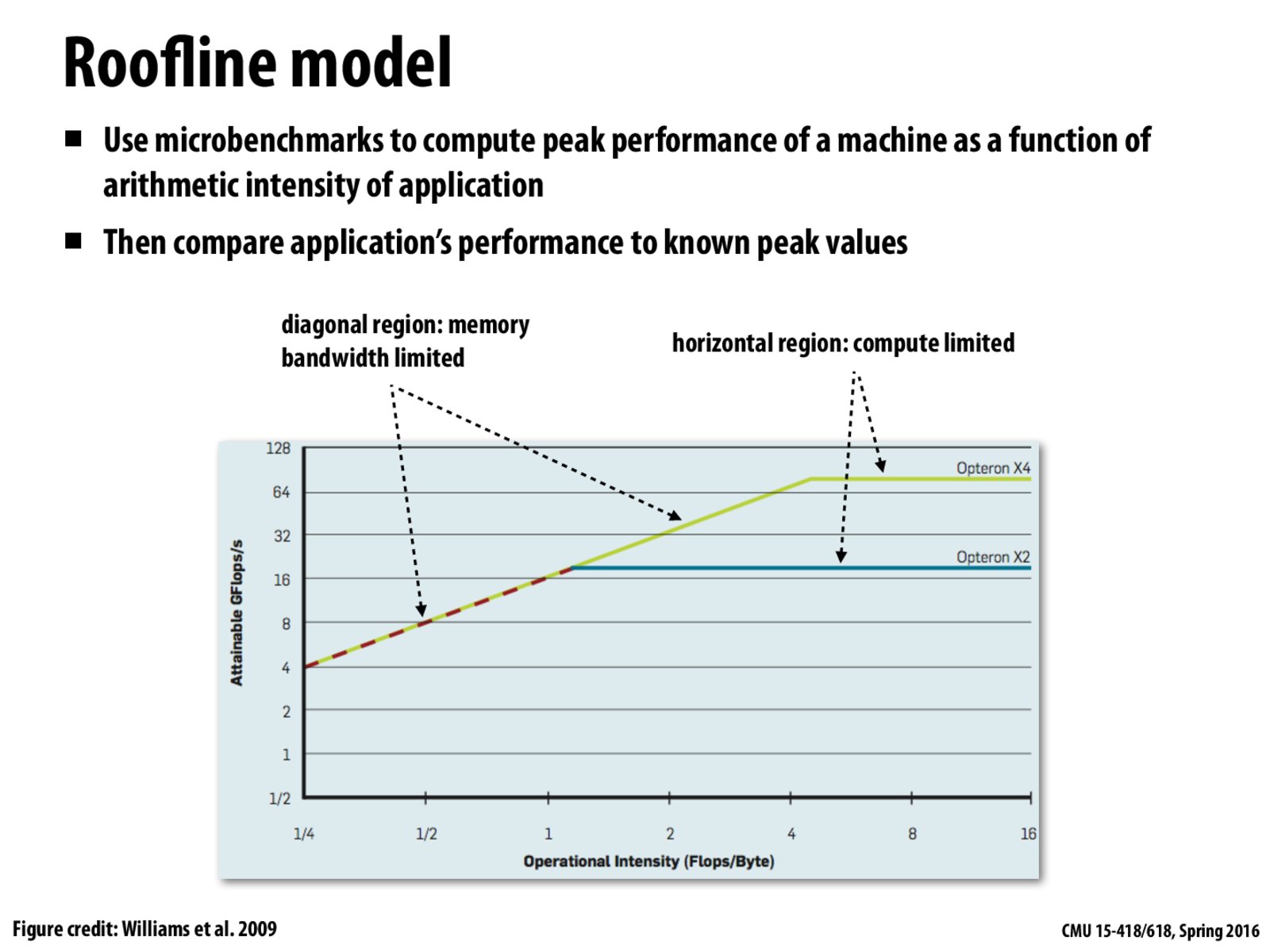
On the left side of the graph, the machines are memory-bound. There are relatively few arithmetic operations compared to memory accesses, and the rate at which the machine can do math is bottlenecked by memory bandwidth and/or latency. On the right-side of the graph, memory is no longer a problem, but the machines have reached maximal arithmetic intensity -- they can't process instructions at a faster rate.
eknight7
The figures in this graph are correct because along with the double number of cores, the X4 processor also has the ability to do twice more memory fetches than X2. Therefore, X4 is 4 times faster than X2.
bpr
I want to correct any misunderstandings, since we only quickly mentioned the basis behind these results. To quote the paper (http://www.eecs.berkeley.edu/~waterman/papers/roofline.pdf), "[the processors] have the same DRAM channels and can thus have the same peak memory bandwidth, although prefetching is better in the X4. In addition to doubling the number of cores, the X4 also has twice the peak floating-point performance per core".
jrgallag
To build on @eknight7's comment, each core in the X4 can do twice as many memory fetches than each core in the X2. Therefore, in the X4, which has 4 cores, we can do 4 times as many math operations, doubling once from the extra memory fetches and doubling twice from having 2 more cores.
bpr
In the horizontal region, the processors are compute limited and could (if the graph was extended to the right) be executing hundreds to thousands of floating point operations per memory fetch. In this region (as @thomasts noted), it is not the memory that bounds the flops/s, but rather the ability to execute more floating point operations every cycle. Each core in the X4 has twice the floating point execution rate than the X2's cores, which is providing a doubling of flops/s in the compute limited region. The remaining increase is primarily from doubling the cores, although an increase in clock speed and other artifacts plays a minor role.
On the left side of the graph, the machines are memory-bound. There are relatively few arithmetic operations compared to memory accesses, and the rate at which the machine can do math is bottlenecked by memory bandwidth and/or latency. On the right-side of the graph, memory is no longer a problem, but the machines have reached maximal arithmetic intensity -- they can't process instructions at a faster rate.
The figures in this graph are correct because along with the double number of cores, the X4 processor also has the ability to do twice more memory fetches than X2. Therefore, X4 is 4 times faster than X2.
I want to correct any misunderstandings, since we only quickly mentioned the basis behind these results. To quote the paper (http://www.eecs.berkeley.edu/~waterman/papers/roofline.pdf), "[the processors] have the same DRAM channels and can thus have the same peak memory bandwidth, although prefetching is better in the X4. In addition to doubling the number of cores, the X4 also has twice the peak floating-point performance per core".
To build on @eknight7's comment, each core in the X4 can do twice as many memory fetches than each core in the X2. Therefore, in the X4, which has 4 cores, we can do 4 times as many math operations, doubling once from the extra memory fetches and doubling twice from having 2 more cores.
In the horizontal region, the processors are compute limited and could (if the graph was extended to the right) be executing hundreds to thousands of floating point operations per memory fetch. In this region (as @thomasts noted), it is not the memory that bounds the flops/s, but rather the ability to execute more floating point operations every cycle. Each core in the X4 has twice the floating point execution rate than the X2's cores, which is providing a doubling of flops/s in the compute limited region. The remaining increase is primarily from doubling the cores, although an increase in clock speed and other artifacts plays a minor role.