In my opinion, abstraction is what you do not need to do whereas implementation is what you have to do. For example, when you order a BigMac at McDonalds, you don't need to know how the BigMac is made. You only need to tell the employee, "I want a BigMac and here is 8 bucks". Then after a while you get one. Here, the employee is an interface where you can get burgers from. But if you are a cook at McDonalds you have to know how to make different burgers. Here, as a cook, you "implement" a burger according to the customer's need. And you also use some abstraction others provide. For example, you don't need to know how to grow vegetables, how to keep cattle, ... You only use those materials as you need, which means you are using abstraction provided by farmers.
grarawr
I agree with monkeyking. To add on to that, I think abstraction provides an interface with which outside users can use for their own purposes without needing to know how it is implemented. It is probably better to hide implementation to users since it allows the user to use the code knowing that they won't have to change the source if a new version is pushed. On the other hand, the developer will have to pay attention to these interface methods so that the client will still be able to use it no matter what changes the developer makes.
haboric
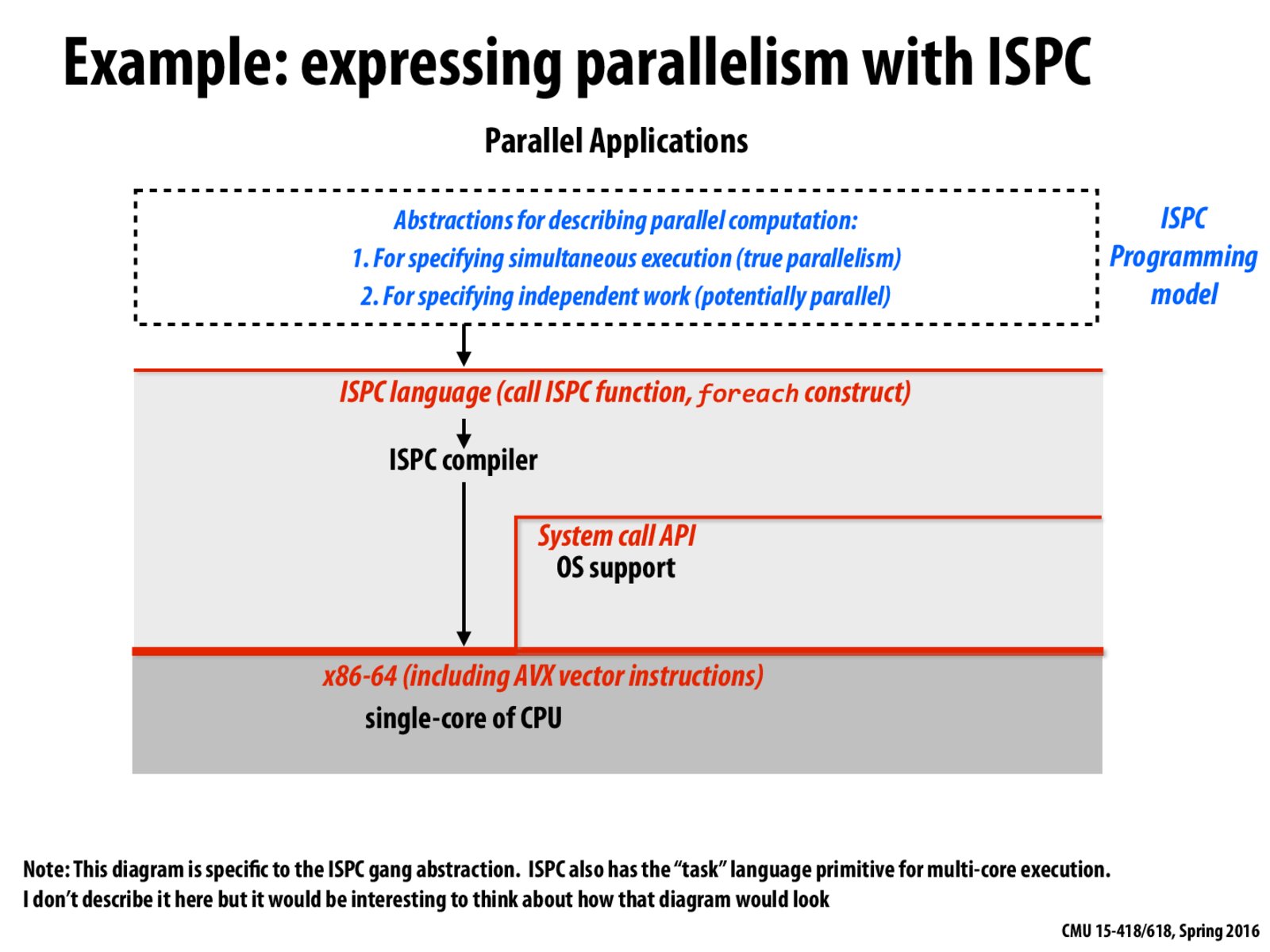
In the comment, can "task" language primitive have an arrow pointing to system call API?
FarmerScrub
I like the burger analogy. However, sometimes it is still useful to know the implementation details. For example, with the ISPC implementation of foreach uses static interweave assignment of program instances. This is usually what you want to do, but there may be cases where block assignment could yield better cache efficiency.
In my opinion, abstraction is what you do not need to do whereas implementation is what you have to do. For example, when you order a BigMac at McDonalds, you don't need to know how the BigMac is made. You only need to tell the employee, "I want a BigMac and here is 8 bucks". Then after a while you get one. Here, the employee is an interface where you can get burgers from. But if you are a cook at McDonalds you have to know how to make different burgers. Here, as a cook, you "implement" a burger according to the customer's need. And you also use some abstraction others provide. For example, you don't need to know how to grow vegetables, how to keep cattle, ... You only use those materials as you need, which means you are using abstraction provided by farmers.
I agree with monkeyking. To add on to that, I think abstraction provides an interface with which outside users can use for their own purposes without needing to know how it is implemented. It is probably better to hide implementation to users since it allows the user to use the code knowing that they won't have to change the source if a new version is pushed. On the other hand, the developer will have to pay attention to these interface methods so that the client will still be able to use it no matter what changes the developer makes.
In the comment, can "task" language primitive have an arrow pointing to system call API?
I like the burger analogy. However, sometimes it is still useful to know the implementation details. For example, with the ISPC implementation of foreach uses static interweave assignment of program instances. This is usually what you want to do, but there may be cases where block assignment could yield better cache efficiency.