As per 1/25 lecture, gather/scatter instructions are expensive due to possibly bad spacial locality. That is, the vector of elements may reside in non-contiguous memory addresses, leading to cache misses.
ppwwyyxx
In machine learning systems like the famous tensorflow, there are also gather and scatter operator. The abstraction is still the same, just another implementation in different levels of the system.
nramakri
To expand on the point about gather/scatter being expensive - this is because every element could be on a different cache line. Every element could also be a TLB miss
enuitt
What allows the scatter instruction to be included in the AVX512?
Richard
I think it's quite easy to implement gather/scatter... Please correct me.
Suppose we want to implement scatter for array. The mapping is f(x). So we hope: array[f(x)]=array[x]. The code can be simply like this:
foreach(i=0,1,...,N){
int temp=array[i];
int index=f(i);
array[index]=temp;
}
randomthread
@Richard I think that is a reasonable implementation of scatter/gather. However I believe the performance problem remains. With k-wide simd we can perform all k loads in one clock (contingent on the memory system) whereas the above gather implementation would only be able to perform up to 1 load per clock. Thus non-sequential loads can have up to k times the cost for k-wide simd.
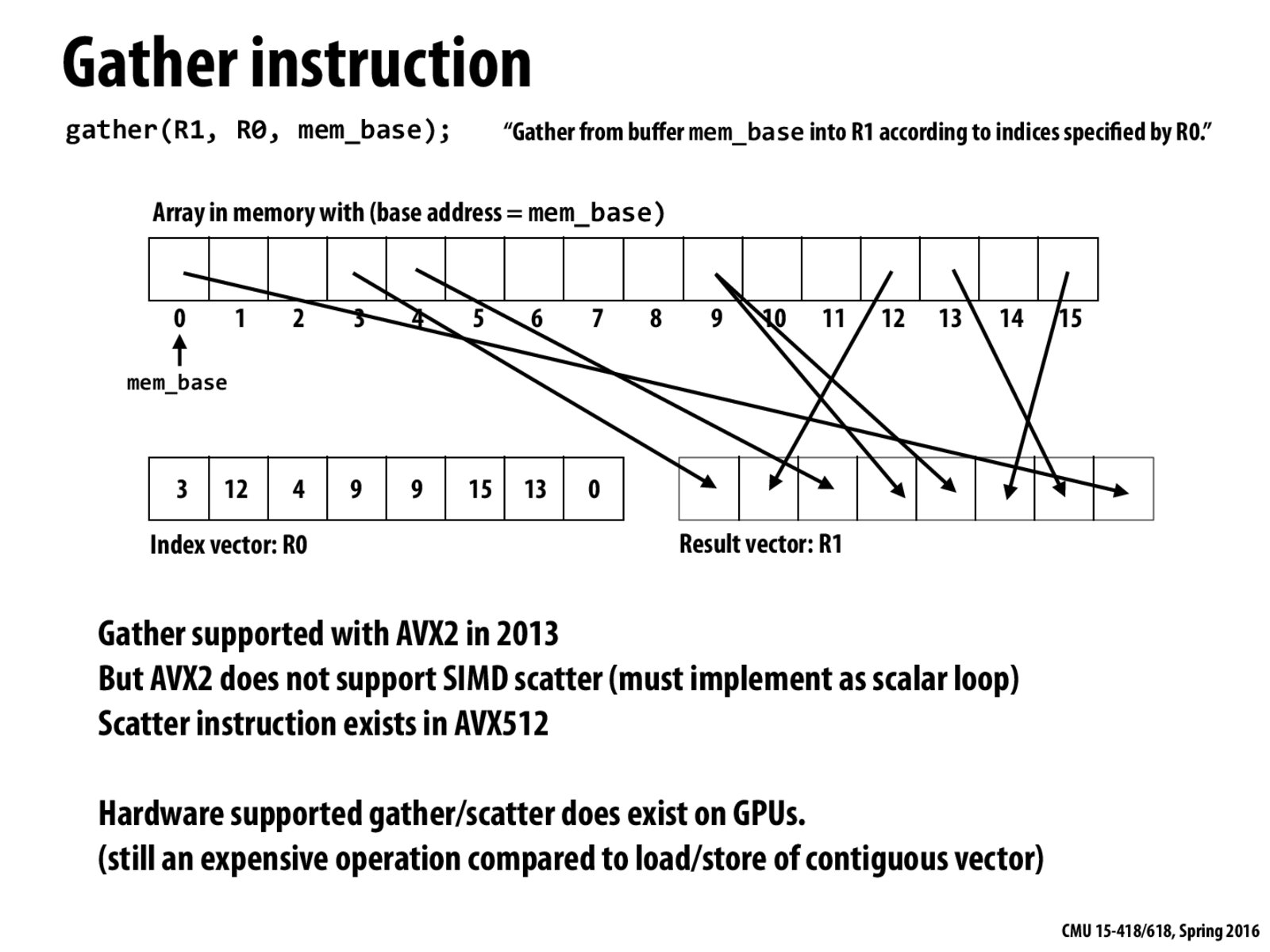
As per 1/25 lecture, gather/scatter instructions are expensive due to possibly bad spacial locality. That is, the vector of elements may reside in non-contiguous memory addresses, leading to cache misses.
In machine learning systems like the famous tensorflow, there are also gather and scatter operator. The abstraction is still the same, just another implementation in different levels of the system.
To expand on the point about gather/scatter being expensive - this is because every element could be on a different cache line. Every element could also be a TLB miss
What allows the scatter instruction to be included in the AVX512?
I think it's quite easy to implement gather/scatter... Please correct me.
Suppose we want to implement scatter for array. The mapping is f(x). So we hope: array[f(x)]=array[x]. The code can be simply like this:
foreach(i=0,1,...,N){
}
@Richard I think that is a reasonable implementation of scatter/gather. However I believe the performance problem remains. With k-wide simd we can perform all k loads in one clock (contingent on the memory system) whereas the above gather implementation would only be able to perform up to 1 load per clock. Thus non-sequential loads can have up to k times the cost for k-wide simd.