Notice that now when parallelizing the first phase of the program on to P processors (assume perfect work distribution), the graph shows that there is P parallelism for this phase of the computation. However, even if the first phase was made infinitely fast (e.g., via parallelization onto an infinite number of processors), the program would still take N^2 time, since there is N^2 work in the serial portion. This limits the maximum overall speedup to 2. We need to also parallelize the second phase of the program to obtain a better speedup.
aeu
During the lecture, I asked about whether adding multiple number of threads per core (rather than a single thread per core, assuming no hyper-threading is present and each core is equal to having one thread) could give us better performance for tasks that have I/O as part of their operation.
Since an I/O-bound part of a task will make block that task, I intuitively thought that having a multiple-threads-per-core way of approaching the problem would give better performance for tasks with the aforementioned I/O-bound parts. I looked around the web a little bit and seen that it might indeed be the case where having multiple threads per core (up to some number) gives you a better performance for general tasks; the correct answer was (as always) "it depends" and that benchmarking for your application should give you a better idea.
yimmyz
I think the key tradeoff here is between context-switching overhead caused by "multiple-threads-per-core" and the hidden I/O latency thanks to it.
Say if we have 1024 threads per core, we can reasonably assume that a lot of I/O latency is hidden. However, the cost of context-switches would be significant, and it is no longer worth the effort. From what I recall in OS, the cost of context-switching can be over 20-50 instructions. Thus, if we naively keep around lots of threads, the hidden I/O latency would be fully used by context-switching.
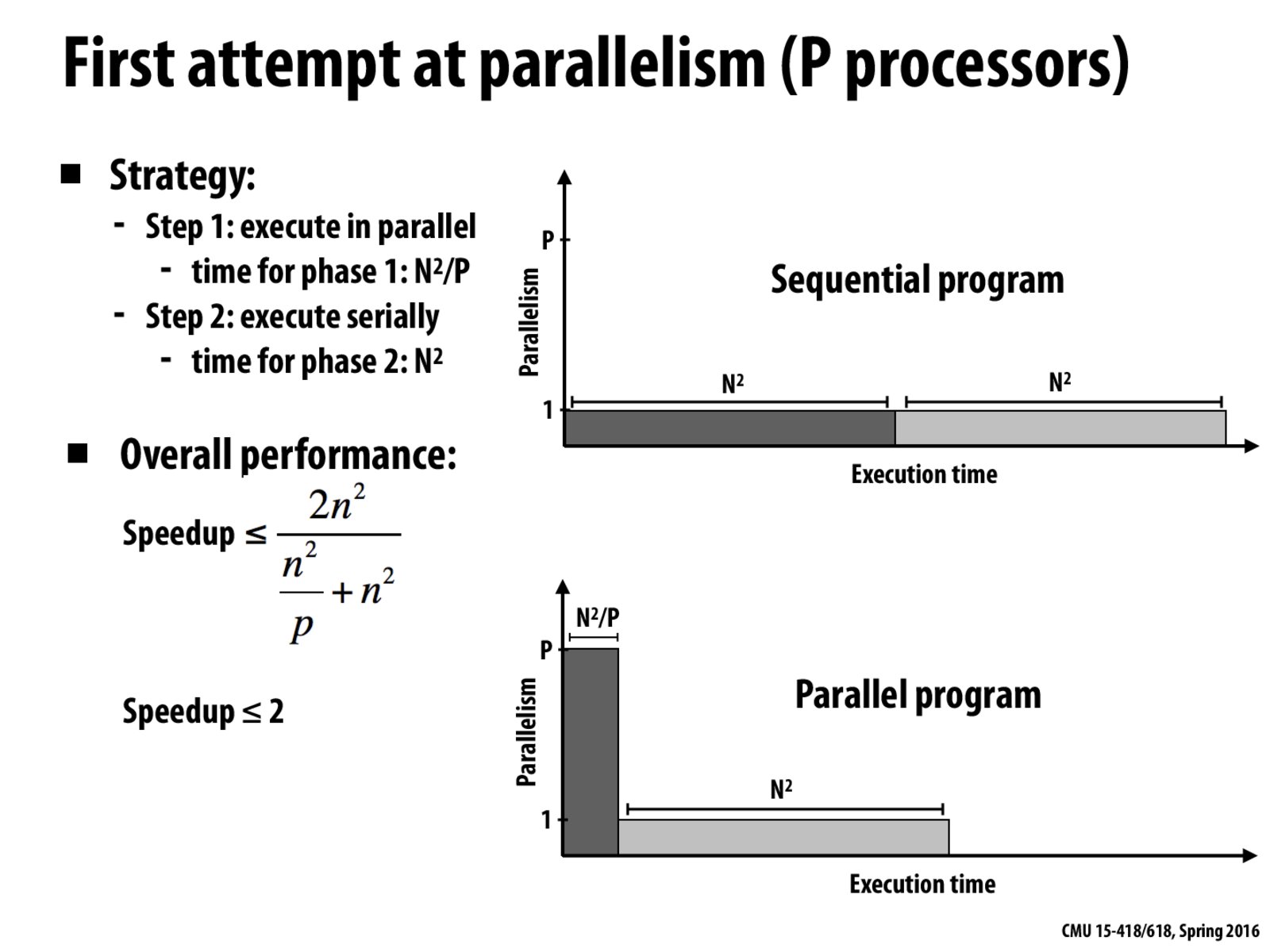
Notice that now when parallelizing the first phase of the program on to
Pprocessors (assume perfect work distribution), the graph shows that there isPparallelism for this phase of the computation. However, even if the first phase was made infinitely fast (e.g., via parallelization onto an infinite number of processors), the program would still take N^2 time, since there is N^2 work in the serial portion. This limits the maximum overall speedup to 2. We need to also parallelize the second phase of the program to obtain a better speedup.During the lecture, I asked about whether adding multiple number of threads per core (rather than a single thread per core, assuming no hyper-threading is present and each core is equal to having one thread) could give us better performance for tasks that have I/O as part of their operation.
Since an I/O-bound part of a task will make block that task, I intuitively thought that having a multiple-threads-per-core way of approaching the problem would give better performance for tasks with the aforementioned I/O-bound parts. I looked around the web a little bit and seen that it might indeed be the case where having multiple threads per core (up to some number) gives you a better performance for general tasks; the correct answer was (as always) "it depends" and that benchmarking for your application should give you a better idea.
I think the key tradeoff here is between context-switching overhead caused by "multiple-threads-per-core" and the hidden I/O latency thanks to it.
Say if we have 1024 threads per core, we can reasonably assume that a lot of I/O latency is hidden. However, the cost of context-switches would be significant, and it is no longer worth the effort. From what I recall in OS, the cost of context-switching can be over 20-50 instructions. Thus, if we naively keep around lots of threads, the hidden I/O latency would be fully used by context-switching.