Since there doesn't seem to be much point for parallelism beyond a certain number of cores, how do supercomputers, which have thousands of cores find tasks suited to them? What kind of tasks are suited to this massive a level of parallelism? How do you go about avoiding the huge overheads associated with supercomputers?
sharangc
Wouldn't the usefulness of the cores depend mainly on how much the problem is parallelizable? So, why would there be no point of having many cores if the problem allows you to use those cores for significant speedup? I might be missing something. Some tasks in which supercomputers are used are weather forecasting, animated graphics etc.
The NOAA also placed 2 orders for supercomputers on the order of around 5 PFLOPS each for use in weather forecasting, both at the research and production level just this past week.
Stampede, the number 10 supercomputer in terms of benchmarks at UT Austin lists a few applications on their website, and you can find many more if you look further.
XSEDE used to have some nice graphs showing which fields had the most compute hours but I can't seem to find them anymore...
jhibshma
In general, how often is Amdahl's law a limiting factor? Are most commonly performed computations largely parallelizable, or is the reverse true?
Also, do we generally know the factor from Amdahl's law, or is it generally a mystery? It seems that to find out how parallelizable a problem is, we need to map out all of its dependencies. If we could map out all of its dependencies, it seems that an ideal parallel algorithm would naturally flow from this map; is this the case?
nmrrs
@jhibshma This doesn't directly answer your question, but it's interesting to note that Amdahl's law has been criticized a bit for being overly pessimistic if it is the only heuristic we look at. In a lot of cases, as the problem size grows (the amount of data we are trying to analyze for example), the amount of time spent in the parallel section of the algorithm becomes larger relative to the amount of time spent in the sequential section of the algorithm. Gufstafson's Law can be used here to show that it is still useful to add more processors as the problem size grows.
yikesaiting
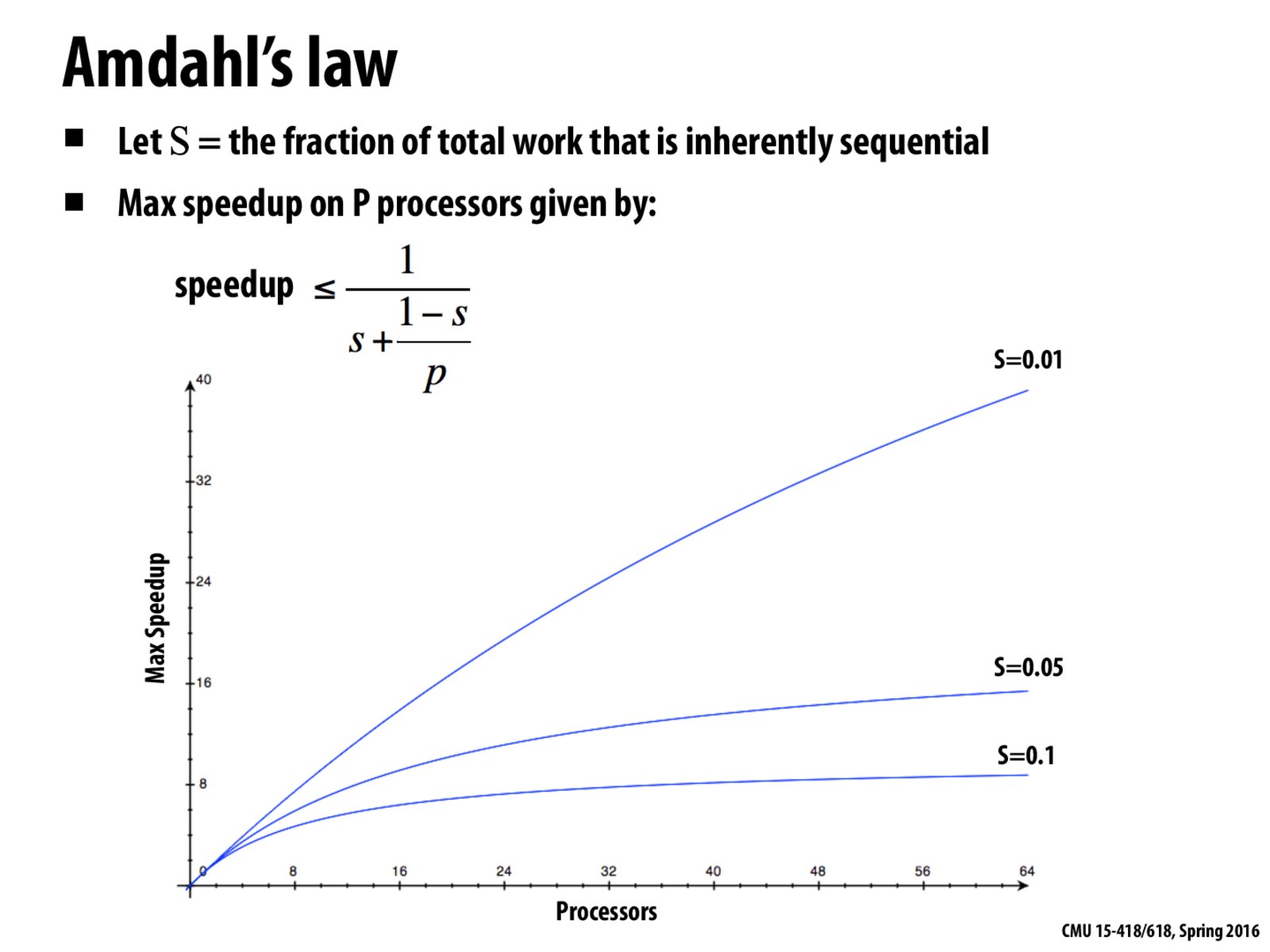
I really love this graph so I search more about Amdahl's law. More formally, s here should be the percentage of the execution time of the whole task concerning the part that CANNOT benefit from the improvement of the resources of the system before the improvement.
1pct
Considering the last slides, the work of combining the partial sum can be interpreted as the part of work that is inherently sequential. So, the fraction S will be p/(2N^2+p). When N>>p, this fraction will be really small (approximately 0) and we can achieve a approximately p speedup.
CaptainBlueBear
The 1/(S + (1-S)/P) equation comes from our earlier equation for the speedup from P processors: speedup = time (1 processor) / time (p processors). The time for P processors in this case is the time for sequential execution + time for parallel execution on the P processors = S + (1-S)/P. So the time for 1 processor = S + (1-S)/1 = 1. Then speedup = 1/(S + (1-S)/P)
maxdecmeridius
Are super computers generally utilized to their full capabilities? It seems extremely difficult to create a program parallel enough to warrant the overheads with super computers.
Even with using "embarrassingly parallel" algorithms, doesn't that limit the applications of said super computers?
kayvonf
@maxdecmeridius: You're intuition is absolutely correct. It is very difficult to use a supercomputer with a large number of processing elements to its full potential. An application much have a huge amount of work, with essentially all of that work widely parallelizable -- developing programming languages and tools to get the most out of current and future supercomputers is an active area of research. For example, meeting the President's goal of building an Exascale supercomputer is going to require significant technology innovation.
Since there doesn't seem to be much point for parallelism beyond a certain number of cores, how do supercomputers, which have thousands of cores find tasks suited to them? What kind of tasks are suited to this massive a level of parallelism? How do you go about avoiding the huge overheads associated with supercomputers?
Wouldn't the usefulness of the cores depend mainly on how much the problem is parallelizable? So, why would there be no point of having many cores if the problem allows you to use those cores for significant speedup? I might be missing something. Some tasks in which supercomputers are used are weather forecasting, animated graphics etc.
@kidz supercomputers are usually used for embarrassingly parallel problems. On the supercomputer Wikipedia page it lists a few of these applications by era of supercomputer.
The NOAA also placed 2 orders for supercomputers on the order of around 5 PFLOPS each for use in weather forecasting, both at the research and production level just this past week.
Stampede, the number 10 supercomputer in terms of benchmarks at UT Austin lists a few applications on their website, and you can find many more if you look further.
XSEDE used to have some nice graphs showing which fields had the most compute hours but I can't seem to find them anymore...
In general, how often is Amdahl's law a limiting factor? Are most commonly performed computations largely parallelizable, or is the reverse true?
Also, do we generally know the factor from Amdahl's law, or is it generally a mystery? It seems that to find out how parallelizable a problem is, we need to map out all of its dependencies. If we could map out all of its dependencies, it seems that an ideal parallel algorithm would naturally flow from this map; is this the case?
@jhibshma This doesn't directly answer your question, but it's interesting to note that Amdahl's law has been criticized a bit for being overly pessimistic if it is the only heuristic we look at. In a lot of cases, as the problem size grows (the amount of data we are trying to analyze for example), the amount of time spent in the parallel section of the algorithm becomes larger relative to the amount of time spent in the sequential section of the algorithm. Gufstafson's Law can be used here to show that it is still useful to add more processors as the problem size grows.
I really love this graph so I search more about Amdahl's law. More formally, s here should be the percentage of the execution time of the whole task concerning the part that CANNOT benefit from the improvement of the resources of the system before the improvement.
Considering the last slides, the work of combining the partial sum can be interpreted as the part of work that is inherently sequential. So, the fraction S will be p/(2N^2+p). When N>>p, this fraction will be really small (approximately 0) and we can achieve a approximately p speedup.
The 1/(S + (1-S)/P) equation comes from our earlier equation for the speedup from P processors: speedup = time (1 processor) / time (p processors). The time for P processors in this case is the time for sequential execution + time for parallel execution on the P processors = S + (1-S)/P. So the time for 1 processor = S + (1-S)/1 = 1. Then speedup = 1/(S + (1-S)/P)
Are super computers generally utilized to their full capabilities? It seems extremely difficult to create a program parallel enough to warrant the overheads with super computers.
Even with using "embarrassingly parallel" algorithms, doesn't that limit the applications of said super computers?
@maxdecmeridius: You're intuition is absolutely correct. It is very difficult to use a supercomputer with a large number of processing elements to its full potential. An application much have a huge amount of work, with essentially all of that work widely parallelizable -- developing programming languages and tools to get the most out of current and future supercomputers is an active area of research. For example, meeting the President's goal of building an Exascale supercomputer is going to require significant technology innovation.