So if I understand this correctly, the interleaved assignment is less efficient because as we load each contagious block in the array, P2, P3 and P4 initially have to wait for P1. And this trend continues where some of the processors have to wait for the others to complete. On the other hand, blocked assignment is better because once each processor gets its respective block, it doesn't have to wait for another processor - it has complete control over its block. So there is less time spent being idle by processors. Is this reasoning correct?
haibinl
I think the major reason that we choose blocked assignment over interleaved assignment is that the blocked one has less communication work between processes. Suppose now we are done computing all black cells and now need to compute all red cells, and imagine each process runs on a different node in the computing cluster. The data processor #2 needs from other processors is the black cells in the grey area marked above since each cell's computation depends on its 4 surrounding cells. You can see that there're few grey areas in the blocked assignment than that in interleaves assignment. This means much less data transfer/communication between processes is needed in the blocked approach.
gnunicorn
@efficiens According to my understanding, in either case, all four processors are at work during each iteration (computing the updated values for either the red dots or the black dots). The difference between the two assignments appears between the iterations, when we switch between red and black dots. Each processor needs to receive the updated values of the dots which appear along its segments' borders. In the blocked assignment case, each processor has only one segment (with 2 borders), so the amount of data which needs to be passed is smaller compared to the interleaved assignment.
zvonryan
@efficiens The key point of this Gauss-Seidel method is using updated values as the sweeping goes, instead of only values from the former iteration. (As it is originally an improvement on Jacobi method). About the actual difference, I think gnunicorn has given a great explanation.
PandaX
Is the 'communication' related to locality?
trappedin418
Communication isn't so much about locality as dependency in this case. Every red point depends on 4 black points so if we utilize multiple processors, the results from one processor may be used by a different processor. In this example, blocked assignment happens to be better due to less communication.
In previous lectures, we mentioned that interleaved is sometimes better but the goal was entirely different (cache locality).
If we didn't have dependency, it may be better to use interleaved though the exact specifics would depend on the cache.
Follow-up question: is there a way to divide up the work between processors to have even less communication than blocked?
patrickbot
(for a 2N x 2N grid), on 4 processors using blocked assignment, the top and bottom processor need to depend on roughly N points, while the middle ones depend on roughly 2N.
If we separate the data into 4 quadrants, each processor now only depends on N, which would be better. I'm not sure how this would extend to p processors.
Of course, if the entire process is communication bound, then we could just use fewer processors.
cyl
I think here the dependency has two concepts - the causality in time and the communication in space.
To me dependency is similar to locality, but time locality doesn't imply the causality.
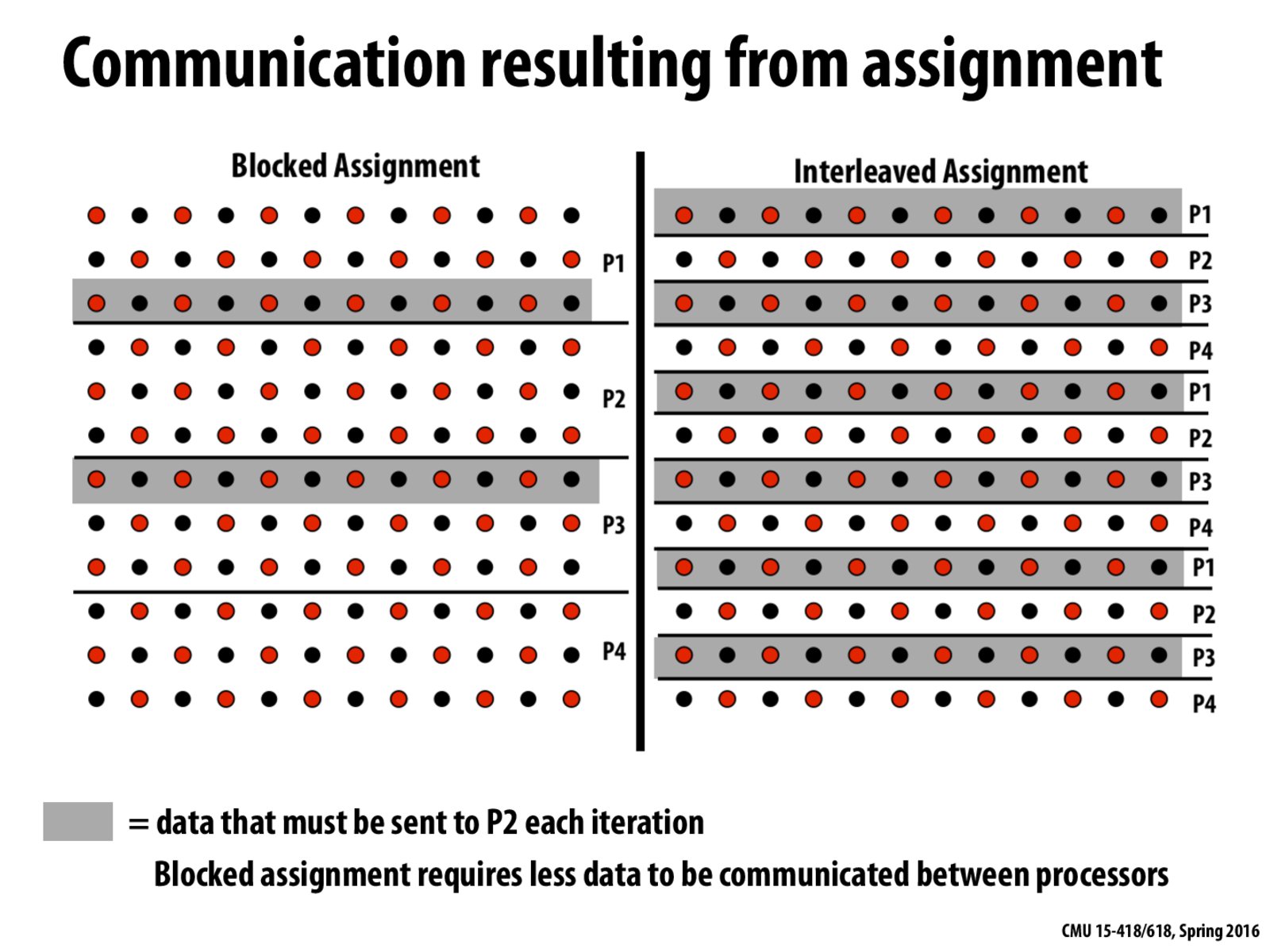
So if I understand this correctly, the interleaved assignment is less efficient because as we load each contagious block in the array, P2, P3 and P4 initially have to wait for P1. And this trend continues where some of the processors have to wait for the others to complete. On the other hand, blocked assignment is better because once each processor gets its respective block, it doesn't have to wait for another processor - it has complete control over its block. So there is less time spent being idle by processors. Is this reasoning correct?
I think the major reason that we choose blocked assignment over interleaved assignment is that the blocked one has less communication work between processes. Suppose now we are done computing all black cells and now need to compute all red cells, and imagine each process runs on a different node in the computing cluster. The data processor #2 needs from other processors is the black cells in the grey area marked above since each cell's computation depends on its 4 surrounding cells. You can see that there're few grey areas in the blocked assignment than that in interleaves assignment. This means much less data transfer/communication between processes is needed in the blocked approach.
@efficiens According to my understanding, in either case, all four processors are at work during each iteration (computing the updated values for either the red dots or the black dots). The difference between the two assignments appears between the iterations, when we switch between red and black dots. Each processor needs to receive the updated values of the dots which appear along its segments' borders. In the blocked assignment case, each processor has only one segment (with 2 borders), so the amount of data which needs to be passed is smaller compared to the interleaved assignment.
@efficiens The key point of this Gauss-Seidel method is using updated values as the sweeping goes, instead of only values from the former iteration. (As it is originally an improvement on Jacobi method). About the actual difference, I think gnunicorn has given a great explanation.
Is the 'communication' related to locality?
Communication isn't so much about locality as dependency in this case. Every red point depends on 4 black points so if we utilize multiple processors, the results from one processor may be used by a different processor. In this example, blocked assignment happens to be better due to less communication.
In previous lectures, we mentioned that interleaved is sometimes better but the goal was entirely different (cache locality).
If we didn't have dependency, it may be better to use interleaved though the exact specifics would depend on the cache.
Follow-up question: is there a way to divide up the work between processors to have even less communication than blocked?
(for a 2N x 2N grid), on 4 processors using blocked assignment, the top and bottom processor need to depend on roughly N points, while the middle ones depend on roughly 2N.
If we separate the data into 4 quadrants, each processor now only depends on N, which would be better. I'm not sure how this would extend to p processors.
Of course, if the entire process is communication bound, then we could just use fewer processors.
I think here the dependency has two concepts - the causality in time and the communication in space.
To me dependency is similar to locality, but time locality doesn't imply the causality.