Is this ideal situation realistic for the schedule to predict? How often does it happen that the scheduler will have enough predictability of the cost of those long tasks that it will have the foresight to put those inherently sequential tasks first to distribute work more efficiently?
Calloc
In case the knowledge of workload is not there before hand and it's impossible to predict the cost of a task, then as Kayvon mentioned in lecture: one can randomly arrange the tasks and the work distribution then should be good on average.
taylor128
In case the work distribution is fixed and known, basically becomes the makespan problem that we discussed in 451. Fun fact: greedy scheduling approach is at most 2 times the optimum, and sorted greedy scheduling approach (first sort the tasks from large to small) is at most 1.5 times the optimum.
grizt
What @taylor128 says is true! In fact, you show that sorted-greedy-scheduling does no worse than 4/3 the optimal scheduling. A proof is here.
stee
I imagine that the knowledge of workload is typically provided by the person providing the tasks. Are there cases where the scheduler is able to guess the workload of the tasks?
pkoenig10
This question is similar to asking "Is the halting problem decidable?", which is a proven "No". Certainly determining the difficulty of a tasks is a much simpler problem, and could be done in limited cases. But it would likely be very application-specific. Most parallel problems are generally are designed so the workload is evenly distributed (think the modifications we made to the Mandelbrot generator in assignment 1). If the problem is complex enough where this may no be the case, it likely is complex enough where the time to calculate some reasonable good heuristic would outweigh the benefit it provides.
acfeng
For task scheduling, there are many strategies/disciplines that can assist in the distribution of workload to optimize resource usage. Each one has its own advantages and disadvantages that can depend on many different factors.
However, as @Calloc stated, without prior knowledge of timing and resource usage, you could not take advantage of task scheduling and will have to randomly assign.
It kinda sucks that there isn't a way to abstract scheduling to any parallel program. Although I suppose that since parallel problems tend to need to scale and are known beforehand, having parallel hardware specifically dedicated to certain problems is the better solution instead of generalizing.
ArbitorOfTheFountain
This looks like an example of the canonical bin packing problem - a couple of useful heuristics that can be used can be found here:
http://bastian.rieck.ru/uni/bin_packing/bin_packing.pdf
This is a common problem in multiprocessor work assignment in real-time systems where timing guarantees must be met.
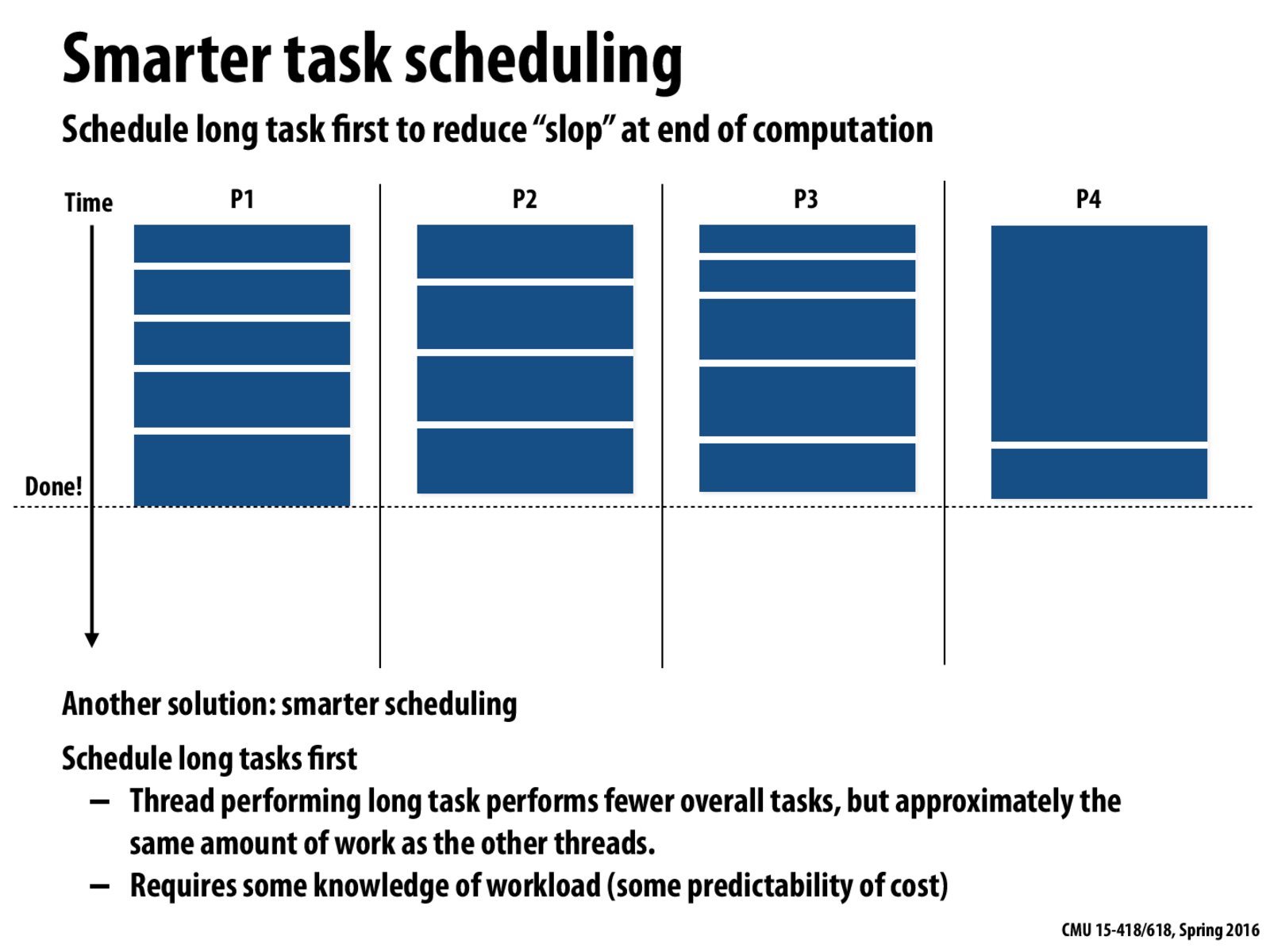
Is this ideal situation realistic for the schedule to predict? How often does it happen that the scheduler will have enough predictability of the cost of those long tasks that it will have the foresight to put those inherently sequential tasks first to distribute work more efficiently?
In case the knowledge of workload is not there before hand and it's impossible to predict the cost of a task, then as Kayvon mentioned in lecture: one can randomly arrange the tasks and the work distribution then should be good on average.
In case the work distribution is fixed and known, basically becomes the makespan problem that we discussed in 451. Fun fact: greedy scheduling approach is at most 2 times the optimum, and sorted greedy scheduling approach (first sort the tasks from large to small) is at most 1.5 times the optimum.
What @taylor128 says is true! In fact, you show that sorted-greedy-scheduling does no worse than 4/3 the optimal scheduling. A proof is here.
I imagine that the knowledge of workload is typically provided by the person providing the tasks. Are there cases where the scheduler is able to guess the workload of the tasks?
This question is similar to asking "Is the halting problem decidable?", which is a proven "No". Certainly determining the difficulty of a tasks is a much simpler problem, and could be done in limited cases. But it would likely be very application-specific. Most parallel problems are generally are designed so the workload is evenly distributed (think the modifications we made to the Mandelbrot generator in assignment 1). If the problem is complex enough where this may no be the case, it likely is complex enough where the time to calculate some reasonable good heuristic would outweigh the benefit it provides.
For task scheduling, there are many strategies/disciplines that can assist in the distribution of workload to optimize resource usage. Each one has its own advantages and disadvantages that can depend on many different factors.
However, as @Calloc stated, without prior knowledge of timing and resource usage, you could not take advantage of task scheduling and will have to randomly assign.
https://en.wikipedia.org/wiki/Scheduling_(computing)#Scheduling_disciplines
It kinda sucks that there isn't a way to abstract scheduling to any parallel program. Although I suppose that since parallel problems tend to need to scale and are known beforehand, having parallel hardware specifically dedicated to certain problems is the better solution instead of generalizing.
This looks like an example of the canonical bin packing problem - a couple of useful heuristics that can be used can be found here: http://bastian.rieck.ru/uni/bin_packing/bin_packing.pdf This is a common problem in multiprocessor work assignment in real-time systems where timing guarantees must be met.