Since the growth of quicksort is roughly exponential in terms of how many tasks it creates, you will quickly fill up most of your execution units anyways.
PandaX
Because this kind of problem is very common and physically create threads like this could result in exponential explosion of thread num. So we need an abstraction, that is how fork&join; is introduced.
totofufu
I'm actually kind of confused by what partition is doing. It's taking the begin and end pointers, choosing a random pivot, and... what exactly is the middle pointer that gets returned? I normally see partition as something that splits up the initial array into two arrays, one with all elements less than the pivot and the other with all elements greater than the pivot and then recursing on those two arrays.
hofstee
@totofufu the middle key is just the pivot. Partition here is just moving elements around, and returning the address of the pivot when it returns. Usually you quick sort all less than pivot, all greater than pivot, and then append the two lists and insert the pivot in between.
This is just your standard quicksort.
cyl
Isn't the merge sort much suitable for parallel computing? My reason is the work load is determined and balanced while the quick sort is not.
lol
@cyl I think this is just an example of fork-join. Samplesort variants are generally top tier parallel sorting algorithms, if you are looking for the best ones.
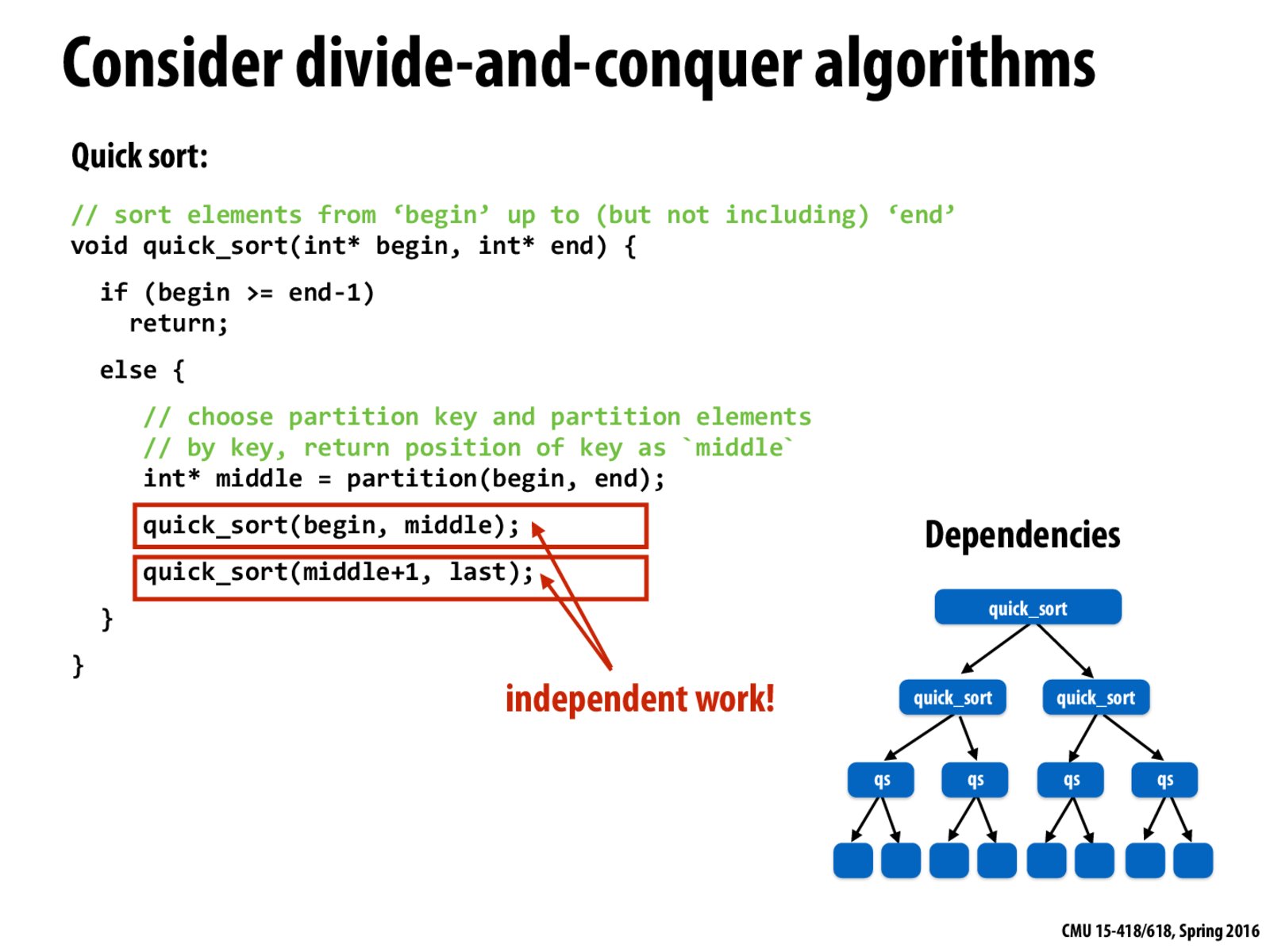
It seems like more cores could be initially utilized if quicksort used more than one pivot (at least for the first few iterations).
Also as a side note, a quicksort that makes multiple pivots takes advantage of modern caching. http://cs.stanford.edu/~rishig/courses/ref/l11a.pdf
Since the growth of quicksort is roughly exponential in terms of how many tasks it creates, you will quickly fill up most of your execution units anyways.
Because this kind of problem is very common and physically create threads like this could result in exponential explosion of thread num. So we need an abstraction, that is how fork&join; is introduced.
I'm actually kind of confused by what partition is doing. It's taking the begin and end pointers, choosing a random pivot, and... what exactly is the middle pointer that gets returned? I normally see partition as something that splits up the initial array into two arrays, one with all elements less than the pivot and the other with all elements greater than the pivot and then recursing on those two arrays.
@totofufu the middle key is just the pivot. Partition here is just moving elements around, and returning the address of the pivot when it returns. Usually you quick sort all less than pivot, all greater than pivot, and then append the two lists and insert the pivot in between.
This is just your standard quicksort.
Isn't the merge sort much suitable for parallel computing? My reason is the work load is determined and balanced while the quick sort is not.
@cyl I think this is just an example of fork-join. Samplesort variants are generally top tier parallel sorting algorithms, if you are looking for the best ones.