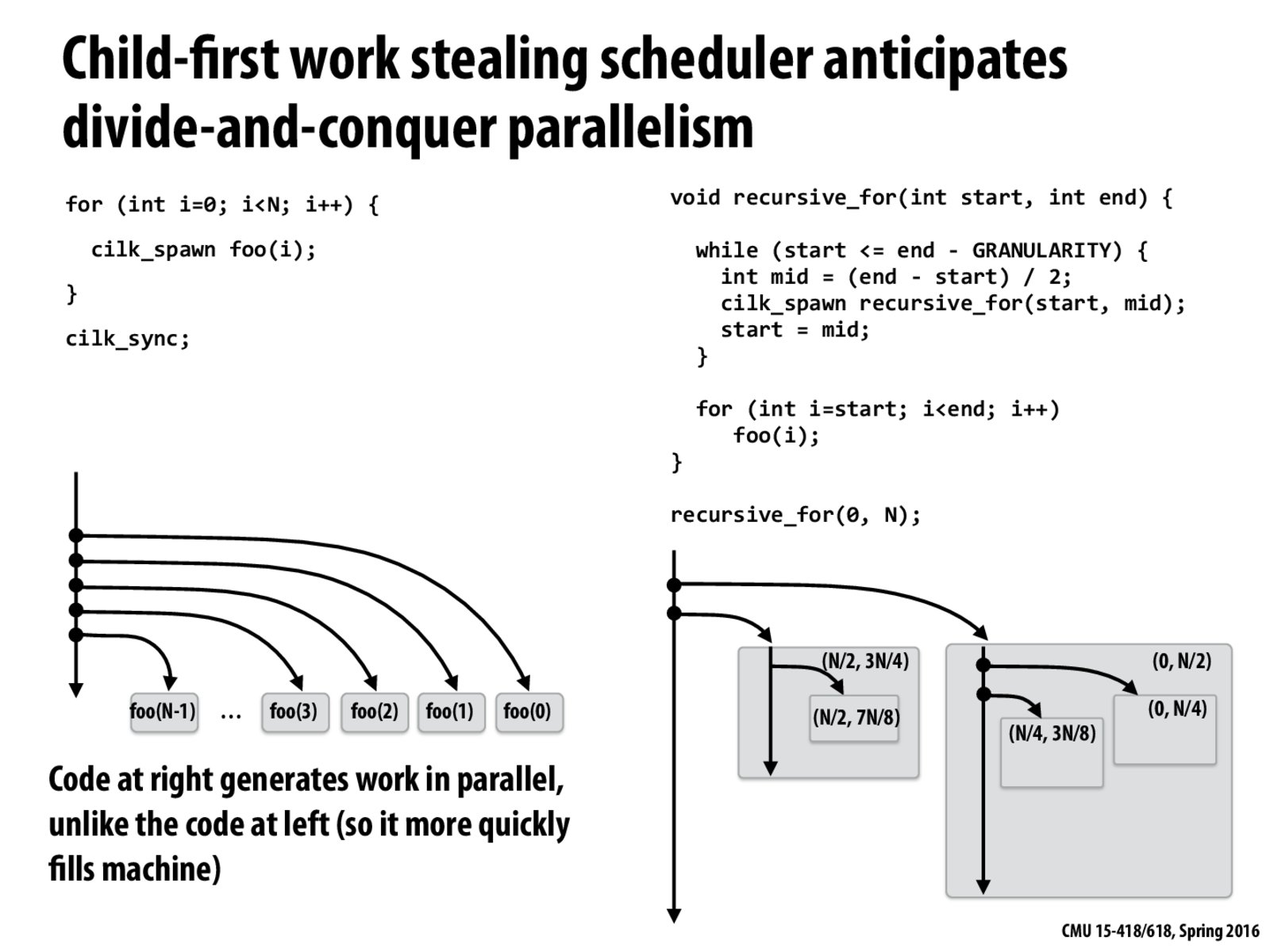
Question: Given your knowledge of how Cilk scheduler works (as described in this lecture), describe how the implementation on the right differs from the one of the left. Why is the implementation on the right the suggested way to write this Cilk program?
yimmyz
I guess the difference is that in the sequential version, the continuation of size (N-1), (n-2), ..., down to 1 are all stored in the queue for "steal", which gives a linear span.
OTOH, for the implementation on the right, the span is reduced down to $\log(n)$, since continuation of size N/2, N/4, ... 1 are stored in the queue. Total number of steals would still be O(n) though.
rmanne
@yimmyz, that doesn't seem quite right, since we can see that the span of the one in the left is actually constant. The one on the right, as you say, is log(n).
However, there are far more things to do on the left, and there's an overhead for starting the next task. This overhead is far greater on the left, which has a lot more small works to do, than the one on the right, which has just as much work overall, but each task does more work, so there are fewer such tasks to complete. So the one on the right will be easier to complete by the scheduler than the left, where it will get spend a lot of its time scheduling tasks.
yikesaiting
I think it is because there are large bulk of work in the queue. So the right approach reduce the time of steal.
doodooloo
Why is this case study specific to child-first work stealing? will it be the same case if the two code segments run with continuation first work stealing?
doodooloo
To answer Kayvon's question:
0. In terms of the total overhead of creating all the tasks, the two code segments are the same, because both of them need to divide around N times.
As mentioned on this slide, the code on the right generates all the tasks in parallel unlike the code on the left. Although after some time, the code on the left can have some thread generating some new task while having other threads doing the real work, it is slower at distributing the works at the beginning. Thus, the code on the left will have some cores being idle for a bit longer at the beginning.
Most importantly, considering the way Cilk is implemented (a worker pool), the code on the right is preferred, because once all the workers are busy, they are going to have equal amount of tasks and no significant stealing will happen.
doodooloo
Adding to point 2: In the code on the right, larger pieces of works are stolen every time rather than small pieces in the code on the left. Thus, the overhead of bookkeeping is less, since it happens less frequently.
MuscleNerd
Quick Clarification Needed:
Does child First Stealing mean that the child is run first or children are being put on the queue to be stolen?
Earlier slides explicitly mention "Run-Child First" or "Run-Continuation first".
kayvonf
On this slide the text "child first" = "run child first" (continuation stealing). Cilk implements run-child first scheduling. Continuations are stolen. The point is that when stealing does not occur, the program should execute in the same order as a serial program would (if all cilk_spawns were turned into normal function calls.) This order is locality maximizing.
Question: Given your knowledge of how Cilk scheduler works (as described in this lecture), describe how the implementation on the right differs from the one of the left. Why is the implementation on the right the suggested way to write this Cilk program?
I guess the difference is that in the sequential version, the continuation of size (N-1), (n-2), ..., down to 1 are all stored in the queue for "steal", which gives a linear span.
OTOH, for the implementation on the right, the span is reduced down to $\log(n)$, since continuation of size N/2, N/4, ... 1 are stored in the queue. Total number of steals would still be O(n) though.
@yimmyz, that doesn't seem quite right, since we can see that the span of the one in the left is actually constant. The one on the right, as you say, is log(n).
However, there are far more things to do on the left, and there's an overhead for starting the next task. This overhead is far greater on the left, which has a lot more small works to do, than the one on the right, which has just as much work overall, but each task does more work, so there are fewer such tasks to complete. So the one on the right will be easier to complete by the scheduler than the left, where it will get spend a lot of its time scheduling tasks.
I think it is because there are large bulk of work in the queue. So the right approach reduce the time of steal.
Why is this case study specific to child-first work stealing? will it be the same case if the two code segments run with continuation first work stealing?
To answer Kayvon's question: 0. In terms of the total overhead of creating all the tasks, the two code segments are the same, because both of them need to divide around N times.
As mentioned on this slide, the code on the right generates all the tasks in parallel unlike the code on the left. Although after some time, the code on the left can have some thread generating some new task while having other threads doing the real work, it is slower at distributing the works at the beginning. Thus, the code on the left will have some cores being idle for a bit longer at the beginning.
Most importantly, considering the way Cilk is implemented (a worker pool), the code on the right is preferred, because once all the workers are busy, they are going to have equal amount of tasks and no significant stealing will happen.
Adding to point 2: In the code on the right, larger pieces of works are stolen every time rather than small pieces in the code on the left. Thus, the overhead of bookkeeping is less, since it happens less frequently.
Quick Clarification Needed:
Does child First Stealing mean that the child is run first or children are being put on the queue to be stolen?
Earlier slides explicitly mention "Run-Child First" or "Run-Continuation first".
On this slide the text "child first" = "run child first" (continuation stealing). Cilk implements run-child first scheduling. Continuations are stolen. The point is that when stealing does not occur, the program should execute in the same order as a serial program would (if all
cilk_spawnswere turned into normal function calls.) This order is locality maximizing.