A 210-style data-parallel approach with map and scan.
msfernan
@CC I haven't taken 210.
Would you/someone be able to elaborate on the map and scan approach?
Does it simply mean going data parallel one way, using scan to reorder the data and then going data parallel another way similar to what we have been doing all this while
jsunseri
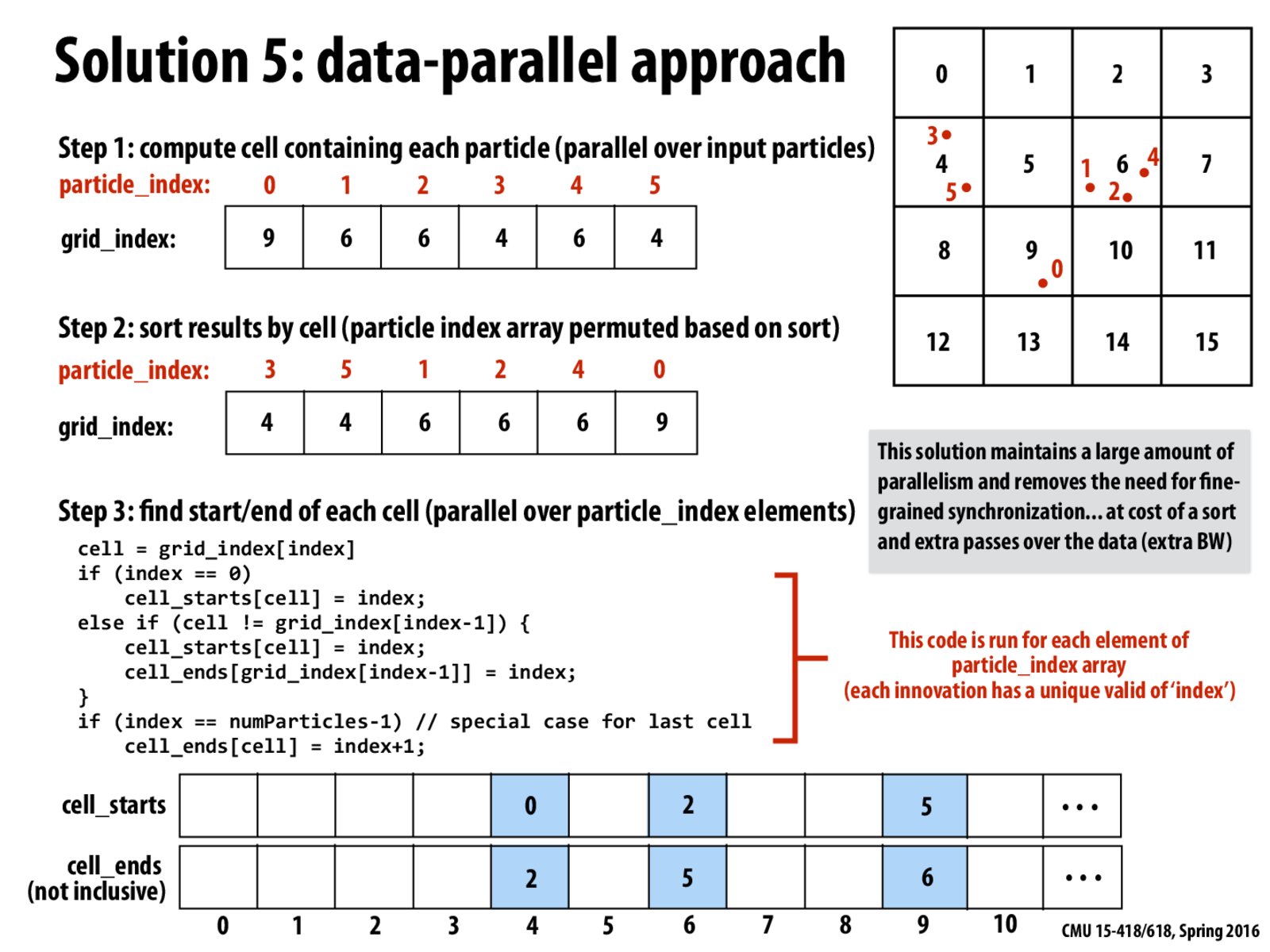
There's a lot happening on this slide, so I just want to break down the approach. The goal is to find the particles within each square. We ultimately end up with an array of particles sorted by the index of the grid in which they are contained - so if we step through this array, we pass through all the particles in square 1, then all the particles in square 2, and so on. We also have generated two companion arrays that you can index into using a grid square's index; one gives you the index into the particle array where that grid square's particles start, and the other gives you the index into the particle array where that grid square's particles end. A major benefit of this approach is that it is extremely parallel - array indices associated with each grid square are only written by the thread working on that square. Generating these data structures requires some additional passes over the data but pays off by maximizing parallelism and eliminating the need for synchronization.
A 210-style data-parallel approach with map and scan.
@CC I haven't taken 210.
Would you/someone be able to elaborate on the map and scan approach? Does it simply mean going data parallel one way, using scan to reorder the data and then going data parallel another way similar to what we have been doing all this while
There's a lot happening on this slide, so I just want to break down the approach. The goal is to find the particles within each square. We ultimately end up with an array of particles sorted by the index of the grid in which they are contained - so if we step through this array, we pass through all the particles in square 1, then all the particles in square 2, and so on. We also have generated two companion arrays that you can index into using a grid square's index; one gives you the index into the particle array where that grid square's particles start, and the other gives you the index into the particle array where that grid square's particles end. A major benefit of this approach is that it is extremely parallel - array indices associated with each grid square are only written by the thread working on that square. Generating these data structures requires some additional passes over the data but pays off by maximizing parallelism and eliminating the need for synchronization.